Regressie-analyse. Cursus Bachelor Project 2 B&O College 2 Harry B.G. Ganzeboom. Regressie-model en mediatie-analyse 1
|
|
|
- Veerle Vedder
- 8 jaren geleden
- Aantal bezoeken:
Transcriptie
1 Regressie-analyse Cursus Bachelor Project 2 B&O College 2 Harry B.G. Ganzeboom Regressie-model en mediatie-analyse 1

2 Agenda Lineaire regressie-model (herhaling) Enkelvoudig (simple) Meervoudig (multiple) Regressie met dummy variabelen / lineariteit. Valkuilen (regression diagnostics) Relatie regressie- en factoranalyse Invloed van onbetrouwbaarheid Regressie-model en mediatie-analyse 2

3 Pallant Ch. 13 is een mooie en korte inleiding in regressieanalyse. De collegestof geeft diepere achtergronden. In deze cursus doen we niet veel met Regression Diagnostics ( ). Lees ze voorzichtig door. Je moet deze begrippen in het kopje van 164 wel kunnen uitleggen! Lees de rest zeer grondig. Merk op verschil in terminologie: Hierarchical multiple regression stepwise (blockwise) forward. Standard regression Multiple regression. Regressie-model en mediatie-analyse 3
 forward.")
4 Model: simple regression X1 B1 /beta1 Y residu Regressie-model en mediatie-analyse 4

5 Model: multiple regression X1 B1 /beta1 Corr r Y residu X2 B2 /beta2 Regressie-model en mediatie-analyse 5

6 Korte demonstratie in SPSS ** MULTIPLE REGRESSIE STAPSGEWIJS **. regr /dep=ident /enter=respect /enter=pride. regr /stat=def change tol /dep=ident /enter=respect /enter=pride. Regressie-model en mediatie-analyse 6

7 Het multipele regressiemodel Het meest gangbare model voor samenhangen tussen twee of meer variabelen is het meervoudige (multipele) lineaire regressiemodel: Y = B0 + B1*X1 + B2*X Bk*Xk + e In woorden: hoe meer X1, X2.. Xp, des te meer Y. Ook: als X1, X2, dan meer Y (discrete variant). Regressie-model en mediatie-analyse 7
.")
8 Het enkelvoudige regressiemodel In de meest eenvoudige variant wordt slechts één X met de Y in verband gebracht: Y = B0 + B1*X1 + residu Y X1 B0 B1 e Afhankelijke variabele Onafhankelijke variabele Intercept, constante Slope, hellingshoek, effect Error, residu. Het enkelvoudige (simple) regressiemodel heeft niet veel directe toepassing, maar als je dit eenmaal begrijpt, is meervoudige regressie een eitje. Regressie-model en mediatie-analyse 8
 regressiemodel heeft niet veel directe toepassing, maar als je dit eenmaal begrijpt,")
9 Y B0 B1. X B0 = intercept: de waarde van Y als X 0 is B1 = slope: de helling van de lijn. Dus de hoeveelheid Y die erbij komt als X één eenheid omhoog gaat Regressie-model en mediatie-analyse 9

10 Wat is het intercept? En wat is de slope? Intercept: bij X = 0, Y = 5. Het intercept is dus 5 Slope: bij X = 35 stijgt Y met 5 (van 5 naar 10). 5/35 is De slope is dus 0.14 Regressie-model en mediatie-analyse 10
. 5/35 is 0.14. De slope is dus 0.")
11 Kleinste Kwadraten, Least Squares De coefficienten van het model (B0 en B1) worden berekend door minimalisering van de kwadratensom: Y Y^ = residu OLS: Sum(Y-Y^)**2 minimaal. Voor deze minimalisering bestaat maar één oplossing en deze kan zonder iteraties worden berekend. Dat doet SPSS voor je. Regressie-model en mediatie-analyse 11

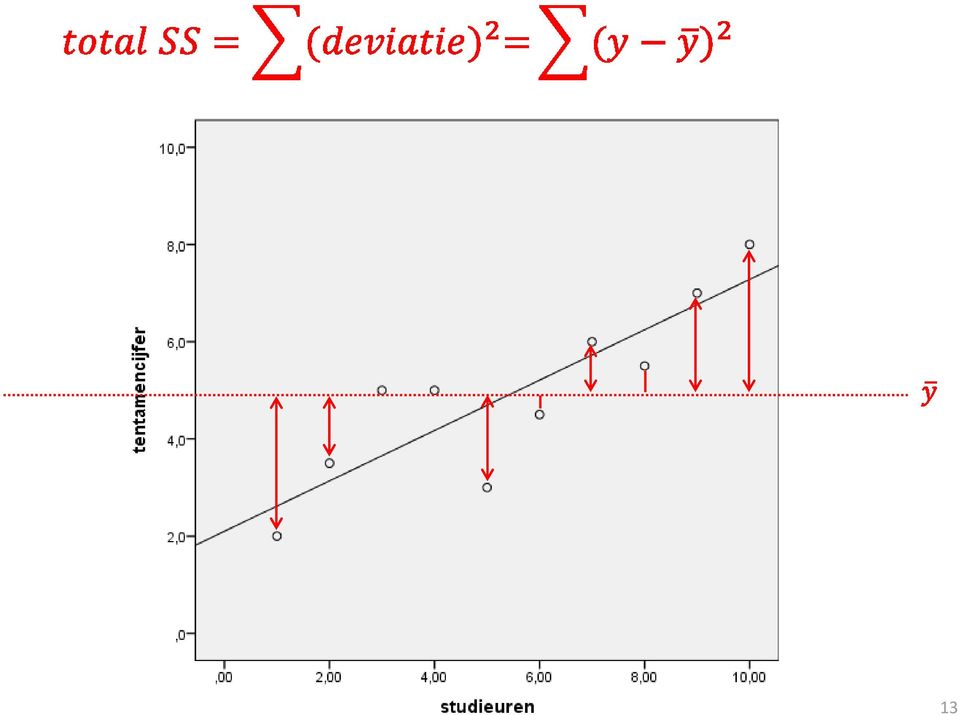
12 12

13 13
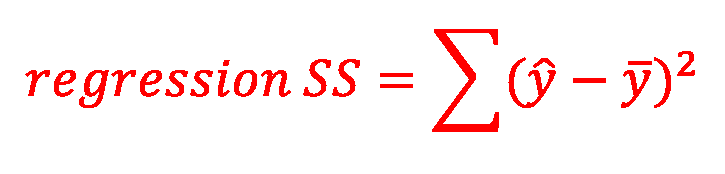
14 14
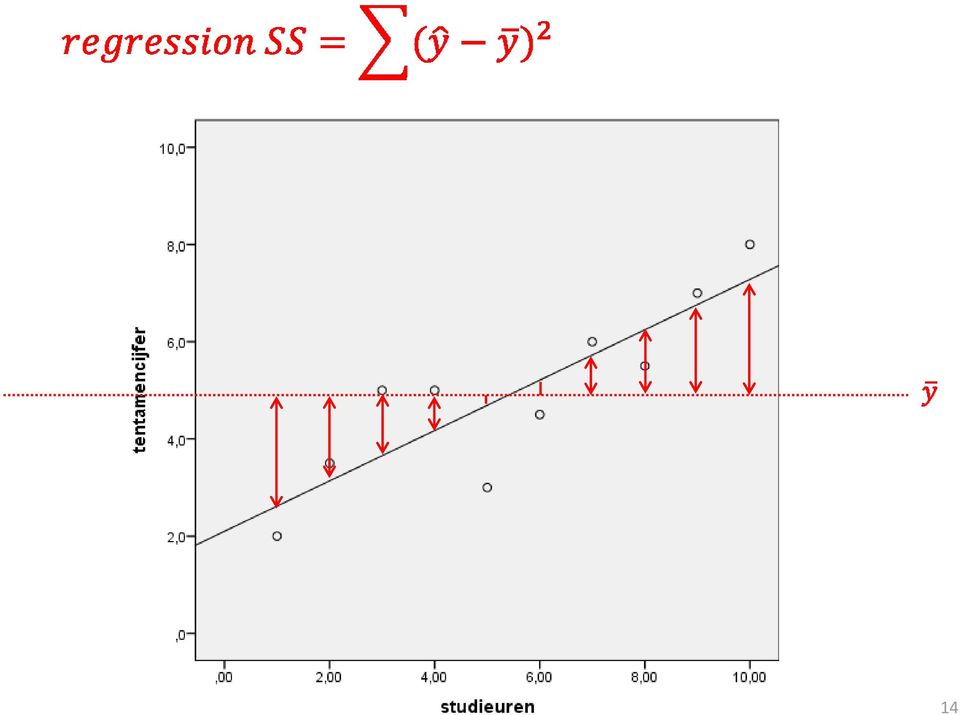
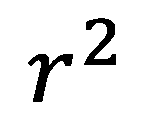
15 15
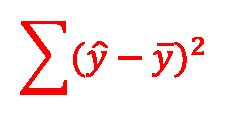
16 16

17 Gestandaardiseerde regressie In gestandaardiseerde regressie worden Y en X allebei gestandaardiseerd tot Z-variabelen ZX = (X M(X)) / SD(X) ZY = (Y M(Y)) / SD(Y) ZY = 0 + beta*zx + residu -1 < beta < 1 Het voordeel van beta boven B is dat je onmiddellijk de sterkte van een invloed ziet. Bij enkelvoudige regressie is beta gelijk aan de correlatie. Het blijft een regressiecoefficient: beta is een slope die aangeeft hoeveel SD(Y) je krijgt voor 1 SD(X). De intercept van een gestandaardiseerde regressie is altijd 0. Regressie-model en mediatie-analyse 17
 je krijgt voor 1 SD(X).")
18 Demonstratie in SPSS ** gestandaardiseerd **. desc respect pride ident /save. desc Zrespect Zpride Zident. regr /dep=zident /enter=zpride Zrespect Regressie-model en mediatie-analyse 18

19 Hoe te lezen? Van onder naar boven.. Het model: Ongestandaardiseerde regressie-coefficienten B (als je de eenheden van X en Y inhoudelijk kunt interpreteren) Gestandaardiseerde regressie-coefficienten BETA (als de eenheden feitelijk betekenisloos zijn) Significantie: Standard Error (SE): geschatte steekproeffluctuatie T-waarde = B/SE: hoeveel SE ligt de B van 0 af! 0 is de bij de nulhypothese veranderstelde waarde. Sig.: Kans dat je deze B zou verkrijgen als H0 waar is. Confidence interval: 95% kans dat de populatiecoefficient in dit interval valt. Regressie-model en mediatie-analyse 19

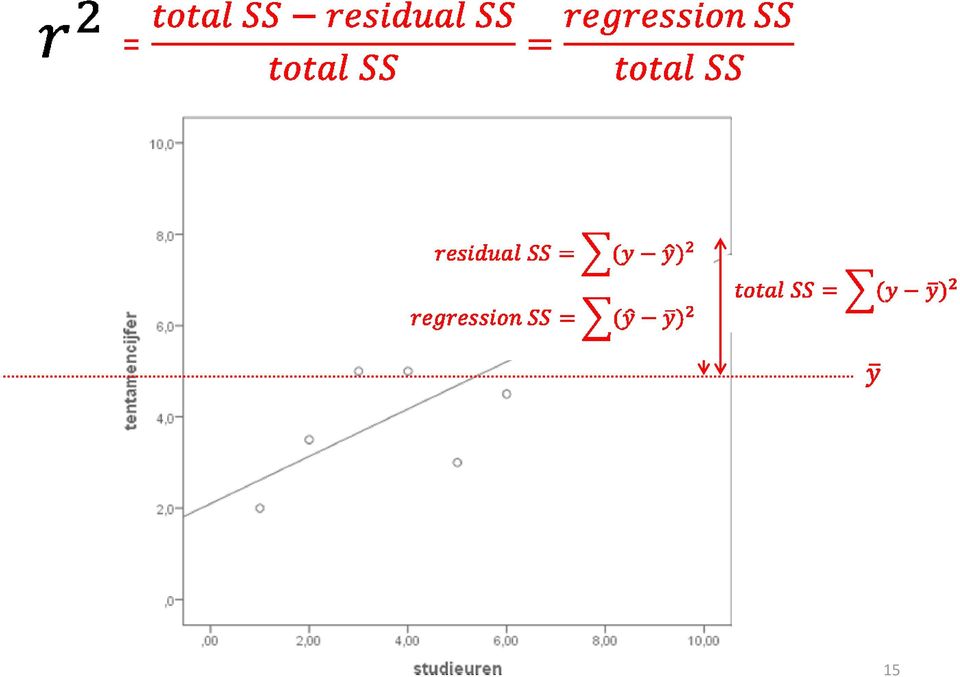
20 ANOVA en R2 De ANOVA-tabel geeft de opdeling van de kwadraatsommen SS: SS-Total SS-Regression SS-Residual SS-total = SS-regression + SS-residual Verklaarde variantie: R2 = SS-regression / SS-Total R = R2 Adj. R2: R2 rekening houdend met aantal X-variabelen. Vrijheidsgraden DF: DF-total = N-1 DF-regression = aantal B-coeffienten DF-residu = DF-total DF-regression Mean squares MS = SS / ndf. F-test: MS-regression / MS-residual. (DF1, DF2). SPSS zoekt de significantie voor je op. De F-test toetst de significantie van de verandering in R2. Dit is met name interessant bij stapsgewijze regressie, waarin je meerdere modellen vergelijkt Regressie-model en mediatie-analyse 20
. SPSS zoekt de significantie voor je op. De F-test toetst de significantie van de verandering in R2.")
21 Multipele regressie Bij multipele regressie komen er gewoon meer X- variabelen en evenveel B-coefficienten bij. De coëfficiënten B staan nu voor partiële effecten. Dit betekent dat je B1 nu het effect van X1 op Y is terwijl X2 constant wordt gehouden. Evenzo is B2 het effect van X2 op Y als X1 constant wordt gehouden. Aan deze partiële interpretatie dankt het regressie-model zijn kracht en bruikbaarheid. Regressie-model en mediatie-analyse 21
22 Hoe houdt multiple regressie constant? (1) De interpretatie van multipele regressiecoefficienten is partieel: B1 geeft de invloed van X1 op Y, terwijl X2 constant wordt gehouden; B2 geeft de invloed van X2 op Y terwijl X1 constant wordt gehouden. Regressie-analyse is daarmee geschikt om de invloed van met elkaar correleren X-vars op Y te bestuderen. Maar hoe doet regressie dat eigenlijk? Constant houden van X1 betekent eigenlijk: terwijl we binnen vaste waarden van X2 kijken. Regressie-model en mediatie-analyse 22
23 Hoe houdt regressie-analyse constant? (2) Multipele regressie werkt eigenlijk als volgt: X2 = BB0 + BB1*X1 ResX1 = X2 - BB0 + BB1*X1 X1 = BB0 + BB2*X2 ResX2 = X1 - BB0 + BB1*X2 ResX1 en ResX2 zijn de residuen van X1 (resp. X2) uit de voorspelling van X2 (resp. X1). Het zijn de stukjes van X1 (resp. X2) die NIET beinvloed worden door X2 (resp. X1). Regr /dep=y /enter=resx1. Regr /dep=y /enter=resx2. Dit geeft dezelfde coefficienten als: Regr /dep=y /enter=x1 X2. Illustratie in SPSS. Regressie-model en mediatie-analyse 23
24 Demonstratie in SPSS ** Hoe houdt regressie analyse constant? **. regr /dep=pride /enter=respect /save=residual(respride). regr /dep=respect /enter=pride /save=residual(resrespect). regr /dep=ident /enter=respride. regr /dep=ident /enter=resrespect. regr /dep=ident /enter=pride Respect. Regressie-model en mediatie-analyse 24
25 Valkuil 1: Intercept Interpretatie van het intercept B0. Dit is de verwachte waarde van Y als alle X-variabelen 0 zijn. Dit is alleen maar een zinvolle grootheid als 0 inderdaad een geldige waarde van X is. Het is goede praktijk om de X-variabelen zo te coderen dat je weet wat 0 is. Bv: codeer de variabele Sekse als (0) man en (1) vrouw. Leeftijd: trek gemiddelde leeftijd af (centreren). Regressie-model en mediatie-analyse 25
26 Valkuil 2: (multi)collineariteit Collineariteit is de mate waarin de X-variabelen met elkaar samenhangen: Collineariteit: correlatie tussen twee X-variabelen Multi-collineariteit: voorspelbaarheid van één X uit alle andere X-variabelen. Multi-collineariteit kun je niet (direct) zien aan de correlaties tussen de X-vars!! Als de X-variabelen sterk met elkaar samenhangen worden de schattingen van B instabiel: SE worden heel groot Verklaarde variantie R2 neemt juist niet toe Regressie-model en mediatie-analyse 26
27 Valkuil 2: multi-collineariteit SPSS geeft diagnostische toetsen of de collineariteit niet te sterk is: TOL (tolerance): onverklaarde variantie van een X uit andere X- en. VIF: 1/Tolerance. Advies: VIF < 10. TOL >.10. Problemen van multi-collineariteit zijn echter afhankelijk van N: bij grote N krijg je wel stabiele schattingen, ook al is er sterke samenhang tussen X-vars. Merk op dat multipele regressie-analyse juist bedoeld is om collineaire situaties te analyseren: als de X-vars niet zouden correleren, kun je net zo goed enkelvoudige regressie doen! Regressie-model en mediatie-analyse 27
28 Valkuil 3: perfecte collineariteit (singulariteit) Als X-variabelen perfect uit elkaar voorspelbaar zijn, kun je de B-coefficienten niet schatten. Ook niet als je heel veel data hebt! Voorbeelden: Leeftijd en geboortejaar Mannen versus vrouwen (dummy-variabelen): je vergelijkt dan met een referentie (=weggelaten) categorie! Regressie-model en mediatie-analyse 28
29 Valkuil 4: Lineariteitsaanname Regressie-modellen zouden beter lineaire modellen kunnen heten: relaties worden samengevat via een rechte lijn: y = a + b.x. Maar lang niet alle relaties zijn lineair. Denk aan: Historisch trends met breuken en golven Verschillen tussen leeftijdsgroepen Regressie-model en mediatie-analyse 29
30 Lineariteitstest Means levert een test of linearity voor het geval je X categorisch (gemaakt) is (AgeCat). Je kunt deze test of linearity ook zelf maken via dummy variabelen. De test bij means is een nuttig en snel begin, maar als je het via dummy variabelen zelf doet, heb je meer mogelijkheden. Regressie-model en mediatie-analyse 30
31 Dummy-variabelen Een set dummyvariabelen wordt afgeleid van een categorische variabelen: Recode Educat (1=1)(else=0) into EduCat1. Recode Educat (2=1)(else=0) into EduCat2. Recode Educat (3=1)(else=0) into EduCat3. Recode Educat (4=1)(else=0) into EduCat4. Recode Educat (5=1)(else=0) into EduCat5. Dit levert vijf 0/1 variabelen op die we in een multiple regressie als voorspeller gebruiken ipv de oorspronkelijke EduCat. Y = B0 + B1*Educat1 + B2*Educat2 + B3*Educat3 + B4*Educat4 + B5*Educat5 Regressie-modEel en mediatie-analyse 31
32 Demonstratie in SPSS regr /dep=pinc /enter=educat1 educat2 educat3 educat4 educat5. regr /dep=pinc /enter=educat2 educat3 educat4 educat5. Regressie-model en mediatie-analyse 32
33 Regressie met dummy-variabelen Dummy-variabelen zijn perfect collineair! Ze moeten dat ook zijn!! Je kunt de regressievergelijking goed interpreteren als je één dummy-var weglaat. Het is heel belangrijk te weten welke deze referentie is. SPSS kiest meestal voor de dummy-variabele die hoort bij de categorie met de grootste N. Soms is het handiger om een andere te kiezen. De effecten van de dummy-variabelen moet je interpreteren als een verschil met de intercept die de verwachte waarde voor de referentie voorstelt. Regressie-model en mediatie-analyse 33
34 Valkuil 5: Onbetrouwbaarheid van de X-variabelen (niet behandeld) Het regressiemodel veronderstelt dat je X- variabelen volledig betrouwbaarheid gemeten zijn. Als er toch onbetrouwbaarheid in de onafhankelijke variabelen is overgebleven, verzwakt dat de B- en Beta-coefficienten. De gevolgen kunnen met name dramatisch zijn, wanneer je onderzoeksvraag gaat over de relatieve sterkte van B- of Beta-coefficienten. Regressie-model en mediatie-analyse 34
35 Onbetrouwbaarheid van Y Als je je Y met onbetrouwbaarheid gemeten is: Vermindert dat de verklaarde variantie Verzwakt dat de Beta-coefficienten Vergroot dat de SE, Maar blijven de B-coefficienten (ongeveer) hetzelfde! Regressie-model en mediatie-analyse 35
36 Demonstratie in SPSS ** EFFECT VAN ONBETROUWBAARHEID IN **. set seed compute loting1=uniform(1). compute loting2=uniform(1). sort cases by loting1. compute xpride=pride. if (loting2 >.80) xpride=lag(pride). regr /dep=ident /enter=xpride Respect. Regressie-model en mediatie-analyse 36
37 Nog wat meer valkuilen (Pallant) Pallant bediscussieert: N of cases (??) Outliers (niet behandeld) Normaliteit (van residuen) Homoskedasticiteit Onafhankelijkheid van waarnemingen Het zijn allemaal belangrijke problemen, maar er is een belangrijke kanttekening bij: vertekeningen treden met name op in de schatting van de SE s, niet zozeer bij de B s. Het doet er allemaal veel toe, bij de significantietesten. Regressie-model en mediatie-analyse 37
38 Nogmaals: gestandaardiseerd of ongestandaardiseerd? Gestandaardiseerde modellen zijn een herberekening van het ongestandaardiseerde model. Ongestandaardiseerde coefficienten van twee X-vars kun je alleen vergelijken als de meeteenheid dezelfde is, bv. tussen stapsgewijze modellen, of tussen groepen (mannen en vrouwen). Gestandaardiseerde coëfficiënten kun (ook) vergelijken tussen variabelen: je kunt er de relatieve sterkte van effecten mee bepalen. Gestandaardiseerde effecten zijn niet gemakkelijk te interpreteren bij 0/1 X-variabelen zoals dummy variabelen. Regressie-model en mediatie-analyse 38
39 Regressie- en Factor-analyse Factoranalyse is weinig anders dan een verzameling van meerdere multipele regressiemodellen, waarbij de onafhankelijke variabelen ongemeten (latent) zijn. In de praktijk gebruiken we hier bijna altijd gestandaardiseerde coefficienten; de intercepten zijn dan altijd 0 en blijven onvermeld. Regressie-model en mediatie-analyse 39
40 Factor- en regressieanalyse Y1 = B11*F1 + B12*F2 + residu Y2 = B21*F1 + B22*F2 + residu Y3 = B31*F1 + B32*F2 + residu Y4 = B41*F1 + B42*F2 + residu Met simple structure: Y1 = B11*F1 + 0*F2 + residu Y2 = B21*F1 + B22*F2 + residu Y3 = 0*F1 + B32*F2 + residu Y4 = 0*F1 + B42*F2 + residu Regressie-model en mediatie-analyse 40
41 Regressie en causaliteit Regressie-coefficienten worden vaak binnen een causaal (oorzaak-gevolg) model geinterpreteerd. Causale interpretatie is alleen geldig als aan twee voorwaarden voldaan is: No reversed causation = causale volgorde: X kan oorzaak van Y zijn = X gaat vooraf aan Y (en niet andersom) No confounding: X en Y worden niet beinvloed door een achterliggende variabele Z. Causale volgorde volgt uit je design of theoretische overwegingen; confounders moet je meten en via regressie constant houden. Regressie-model en mediatie-analyse 41
42 Waarom heet regressie zo? Regressiemodel is een niet zo duidelijke naam. Beter zou zijn lineaire modellen of least-squares modellen. De term regressie is afkomstig uit de biologie, waarin het model oorspronkelijke ontwikkeld is om de samenhang in lengte tussen ouders en kinderen te modelleren. Kinderen worden niet even lang als hun ouders: lange ouders hebben kinderen die gemiddeld korter zijn dan zijzelf, korte ouders hebben kinderen die gemiddeld langer zijn dan zijzelf. De regressie -coeffecient meet dan de mate waarin dit verband niet perfect (1.0) is, i.e. de lengte van kinderen regresseert naar het gemiddelde. Regressie-model en mediatie-analyse 42
43 Stappenplan regressie-analyse Stap 1: Check variabelen: meetniveau, missing values? Codeer categorische variabelen als 0/1 (dummy) variabelen. Zorg voor 0-punt bij andere variabelen duidelijk is (centreren). Stap 2: Causale volgorde: wat is X en wat is Y? Stap 3: Bereken de regressiemodellen, bij voorkeur stapsgewijs (regress /enter=). Stap 4: Interpreteer eerst het ongestandaardiseerde en gestandaardiseerde regressie-model, daarna de significantie. Stap 5: Rapporteer B en SE, en/of beta/t en R2. Regressie-model en mediatie-analyse 43
44 Mediatie en moderatie Volgende week mediatie-analyse, derde week moderatie analyse: Mediatie: verloopt de invloed van X op Y via M? Moderatie: hangt de invloed van X op Y af Z? Baron & Kenny beginnen met Moderatie, wij doen het andersom. Over geen van beide geeft Pallant directe informatie. Beide maken gebruik van het multipele regressie-model zoals besproken in Pallant, CH 13. Regressie-model en mediatie-analyse 44
Analyse van confounders en mediatoren. Cursus Bachelor Project 2 B&O College 3 Harry B.G. Ganzeboom
 Analyse van confounders en mediatoren Cursus Bachelor Project 2 B&O College 3 Harry B.G. Ganzeboom 1 AGENDA Nabespreking Practicum 2. Terug naar College 2: regressie met dummyvariabelen. Confounding en
Analyse van confounders en mediatoren Cursus Bachelor Project 2 B&O College 3 Harry B.G. Ganzeboom 1 AGENDA Nabespreking Practicum 2. Terug naar College 2: regressie met dummyvariabelen. Confounding en
Moderatie-analyse met continue moderator (wijzigingen in rood) Cursus Bachelor Project 2 B&O College 5 Harry B.G. Ganzeboom
 Cursus Bachelor Project 2 B&O College 5 Harry B.G. Ganzeboom") Moderatie-analyse met continue moderator (wijzigingen in rood) Cursus Bachelor Project 2 B&O College 5 Harry B.G. Ganzeboom 1 AGENDA Responsiecollege a.s. vrijdag Nabespreking Practicum 4: moderatie met
Moderatie-analyse met continue moderator (wijzigingen in rood) Cursus Bachelor Project 2 B&O College 5 Harry B.G. Ganzeboom 1 AGENDA Responsiecollege a.s. vrijdag Nabespreking Practicum 4: moderatie met
11. Multipele Regressie en Correlatie
 11. Multipele Regressie en Correlatie Meervoudig regressie model Nu gaan we kijken naar een relatie tussen een responsvariabele en meerdere verklarende variabelen. Een bivariate regressielijn ziet er in
11. Multipele Regressie en Correlatie Meervoudig regressie model Nu gaan we kijken naar een relatie tussen een responsvariabele en meerdere verklarende variabelen. Een bivariate regressielijn ziet er in
Causale modellen: Confounding en mediatie. Harry Ganzeboom Kwantitatieve Methoden voor PMC-BCO College 2: 25 april 2016
 Causale modellen: Confounding en mediatie Harry Ganzeboom Kwantitatieve Methoden voor PMC-BCO College 2: 25 april 2016 Correlatie en causatie Een standaard wijsheid in methodologie is dat correlatie (samenhang)
Causale modellen: Confounding en mediatie Harry Ganzeboom Kwantitatieve Methoden voor PMC-BCO College 2: 25 april 2016 Correlatie en causatie Een standaard wijsheid in methodologie is dat correlatie (samenhang)
Regressie-analyse doel menu hulp globale werkwijze aandachtspunten Doel: Voor de uitvoering in SPSS: Missing Values Globale werkwijze
 Regressie-analyse Regressie-analyse is gericht op het voorspellen van één (numerieke) afhankelijke variabele met behulp van een of meerdere onafhankelijke variabelen (numerieke en/of dummy-variabelen).
Regressie-analyse Regressie-analyse is gericht op het voorspellen van één (numerieke) afhankelijke variabele met behulp van een of meerdere onafhankelijke variabelen (numerieke en/of dummy-variabelen).
Mediatie-analyse College 4+ Cursus PMC Statistiek Plus. Harry Ganzeboom 1 maart 2019
 Mediatie-analyse College 4+ Cursus PMC Statistiek Plus Harry Ganzeboom 1 maart 2019 Hoofdpunten Wat is mediatie? Wat is confounding? Waarschuwing: Mediatie is geen moderatie!! Multipele regressie: hoe
Mediatie-analyse College 4+ Cursus PMC Statistiek Plus Harry Ganzeboom 1 maart 2019 Hoofdpunten Wat is mediatie? Wat is confounding? Waarschuwing: Mediatie is geen moderatie!! Multipele regressie: hoe
Kwantitatieve modellen. Harry B.G. Ganzeboom 18 april 2016 College 1: Meetkwaliteit
 Kwantitatieve modellen voor BCO PMC Harry B.G. Ganzeboom 18 april 2016 College 1: Meetkwaliteit Drie colleges Validiteits- en betrouwbaarheidsanalyse Causale analyse met confounding en mediatie Causale
Kwantitatieve modellen voor BCO PMC Harry B.G. Ganzeboom 18 april 2016 College 1: Meetkwaliteit Drie colleges Validiteits- en betrouwbaarheidsanalyse Causale analyse met confounding en mediatie Causale
** VOORBEELD VAN CAUSALE ANALYSE MET CONFOUNDER EN MEDIATOR **.. GET FILE='u:\)Research\ISSP-NL\ISSP \Data\issp_2013_2014_NL_def.sav'.
Research\ISSP-NL\ISSP \Data\issp_2013_2014_NL_def.sav'.") ** VOORBEELD VAN CAUSALE ANALYSE MET CONFOUNDER EN MEDIATOR **.. GET FILE=''. ** EERST MAKEN WE EEN OVERZICHT VAN DE DATA **. freq nl_rinc wrkhrs sex. Frequencies Statistics N Valid Missing NL_RINC Resp:
** VOORBEELD VAN CAUSALE ANALYSE MET CONFOUNDER EN MEDIATOR **.. GET FILE=''. ** EERST MAKEN WE EEN OVERZICHT VAN DE DATA **. freq nl_rinc wrkhrs sex. Frequencies Statistics N Valid Missing NL_RINC Resp:
Zowel correlatie als regressie meten statistische samenhang Correlatie: geen oorzakelijk verband verondersteld: X Y
 1 Regressie analyse Zowel correlatie als regressie meten statistische samenhang Correlatie: geen oorzakelijk verband verondersteld: X Y Regressie: wel een oorzakelijk verband verondersteld: X Y Voorbeeld
1 Regressie analyse Zowel correlatie als regressie meten statistische samenhang Correlatie: geen oorzakelijk verband verondersteld: X Y Regressie: wel een oorzakelijk verband verondersteld: X Y Voorbeeld
mlw stroom 2.1: Statistisch modelleren
 mlw stroom 2.1: Statistisch modelleren College 5: Regressie en correlatie (2) Rosner 11.5-11.8 Arnold Kester Capaciteitsgroep Methodologie en Statistiek Universiteit Maastricht Postbus 616, 6200 MD Maastricht
mlw stroom 2.1: Statistisch modelleren College 5: Regressie en correlatie (2) Rosner 11.5-11.8 Arnold Kester Capaciteitsgroep Methodologie en Statistiek Universiteit Maastricht Postbus 616, 6200 MD Maastricht
(slope in het Engels) en het snijpunt met de y-as, b 0
 en het snijpunt met de y-as, b 0") 8. Regressie Een introductie Al vaak is genoemd dat statistische modellen allemaal neerkomen op uitkomst = model + error. Dit model kun je ook gebruiken om de uitkomst te voorspellen, met een correlatie
8. Regressie Een introductie Al vaak is genoemd dat statistische modellen allemaal neerkomen op uitkomst = model + error. Dit model kun je ook gebruiken om de uitkomst te voorspellen, met een correlatie
Voorbeeld regressie-analyse
 Voorbeeld regressie-analyse In dit voorbeeld wordt gebruik gemaakt van het SPSS data-bestand vb_regr.sav (dit bestand kan gedownload worden via de on-line helpdesk). We schatten een model waarin de afhankelijke
Voorbeeld regressie-analyse In dit voorbeeld wordt gebruik gemaakt van het SPSS data-bestand vb_regr.sav (dit bestand kan gedownload worden via de on-line helpdesk). We schatten een model waarin de afhankelijke
Hoofdstuk 8: Multipele regressie Vragen
 Hoofdstuk 8: Multipele regressie Vragen 1. Wat is het verschil tussen de pearson correlatie en de multipele correlatie R? 2. Voor twee modellen berekenen we de adjusted R2 : Model 1 heeft een adjusted
Hoofdstuk 8: Multipele regressie Vragen 1. Wat is het verschil tussen de pearson correlatie en de multipele correlatie R? 2. Voor twee modellen berekenen we de adjusted R2 : Model 1 heeft een adjusted
9. Lineaire Regressie en Correlatie
 9. Lineaire Regressie en Correlatie Lineaire verbanden In dit hoofdstuk worden methoden gepresenteerd waarmee je kwantitatieve respons variabelen (afhankelijk) en verklarende variabelen (onafhankelijk)
9. Lineaire Regressie en Correlatie Lineaire verbanden In dit hoofdstuk worden methoden gepresenteerd waarmee je kwantitatieve respons variabelen (afhankelijk) en verklarende variabelen (onafhankelijk)
Cursus TEO: Theorie en Empirisch Onderzoek. Practicum 2: Herhaling BIS 11 februari 2015
 Cursus TEO: Theorie en Empirisch Onderzoek Practicum 2: Herhaling BIS 11 februari 2015 Centrale tendentie Centrale tendentie wordt meestal afgemeten aan twee maten: Mediaan: de middelste waarneming, 50%
Cursus TEO: Theorie en Empirisch Onderzoek Practicum 2: Herhaling BIS 11 februari 2015 Centrale tendentie Centrale tendentie wordt meestal afgemeten aan twee maten: Mediaan: de middelste waarneming, 50%
College 6: Responsiecollege (wijzigingen in rood) Cursus Bachelor Project 2 B&O College 6 Harry B.G. Ganzeboom
 Cursus Bachelor Project 2 B&O College 6 Harry B.G. Ganzeboom") College 6: Responsiecollege (wijzigingen in rood) Cursus Bachelor Project 2 B&O College 6 Harry B.G. Ganzeboom AGENDA Omgang met SPSS (tijdens het tentamen). Gebruik van Excel. Factoranalyse en betrouwbaarheidsanalyse
College 6: Responsiecollege (wijzigingen in rood) Cursus Bachelor Project 2 B&O College 6 Harry B.G. Ganzeboom AGENDA Omgang met SPSS (tijdens het tentamen). Gebruik van Excel. Factoranalyse en betrouwbaarheidsanalyse
10. Moderatie, mediatie en nog meer regressie
 10. Moderatie, mediatie en nog meer regressie Voordat je moderatie en mediatie analyses gaat uitvoeren in, kun je het best een extra dialog box installeren, PROCESS. Volg hiervoor de stappen op pagina
10. Moderatie, mediatie en nog meer regressie Voordat je moderatie en mediatie analyses gaat uitvoeren in, kun je het best een extra dialog box installeren, PROCESS. Volg hiervoor de stappen op pagina
HOOFDSTUK VII REGRESSIE ANALYSE
 HOOFDSTUK VII REGRESSIE ANALYSE 1 DOEL VAN REGRESSIE ANALYSE De relatie te bestuderen tussen een response variabele en een verzameling verklarende variabelen 1. LINEAIRE REGRESSIE Veronderstel dat gegevens
HOOFDSTUK VII REGRESSIE ANALYSE 1 DOEL VAN REGRESSIE ANALYSE De relatie te bestuderen tussen een response variabele en een verzameling verklarende variabelen 1. LINEAIRE REGRESSIE Veronderstel dat gegevens
College 2 Enkelvoudige Lineaire Regressie
 College Enkelvoudige Lineaire Regressie - Leary: Hoofdstuk 7 tot p. 170 (Advanced Correlational Strategies) - MM&C: Hoofdstuk 10 (Inference for Regression) - Aanvullende tekst 3 Jolien Pas ECO 011-01 Correlatie:
College Enkelvoudige Lineaire Regressie - Leary: Hoofdstuk 7 tot p. 170 (Advanced Correlational Strategies) - MM&C: Hoofdstuk 10 (Inference for Regression) - Aanvullende tekst 3 Jolien Pas ECO 011-01 Correlatie:
Hoofdstuk 19. Voorspellende analyse bij marktonderzoek
 Hoofdstuk 19 Voorspellende analyse bij marktonderzoek Voorspellen begrijpen Voorspelling: een uitspraak over wat er naar verwachting in de toekomst zal gebeuren op basis van ervaringen uit het verleden
Hoofdstuk 19 Voorspellende analyse bij marktonderzoek Voorspellen begrijpen Voorspelling: een uitspraak over wat er naar verwachting in de toekomst zal gebeuren op basis van ervaringen uit het verleden
X covarieert ook met Y, indien de invloed van confounders Z constant wordt gehouden (no confounding).
.") CAUSALE ANALYSE Een handreiking Harry B.G. Ganzeboom (Deze versie: 2 maart 2015). Het belang van causaliteit Wetenschap is erop gericht om uit te vinden hoe de wereld werkt. In het onderzoek dienen daarom
CAUSALE ANALYSE Een handreiking Harry B.G. Ganzeboom (Deze versie: 2 maart 2015). Het belang van causaliteit Wetenschap is erop gericht om uit te vinden hoe de wereld werkt. In het onderzoek dienen daarom
College 3 Meervoudige Lineaire Regressie
 College 3 Meervoudige Lineaire Regressie - Leary: Hoofdstuk 8 p. 165-169 - MM&C: Hoofdstuk 11 - Aanvullende tekst 3 (alinea 2) Jolien Pas ECO 2012-2013 'Computerprogramma voorspelt Top 40-hits Bron: http://www.nu.nl/internet/2696133/computerprogramma-voorspelt-top-40-hits.html
College 3 Meervoudige Lineaire Regressie - Leary: Hoofdstuk 8 p. 165-169 - MM&C: Hoofdstuk 11 - Aanvullende tekst 3 (alinea 2) Jolien Pas ECO 2012-2013 'Computerprogramma voorspelt Top 40-hits Bron: http://www.nu.nl/internet/2696133/computerprogramma-voorspelt-top-40-hits.html
werkcollege 8 correlatie, regressie - D&P5: Summarizing Bivariate Data relatie tussen variabelen scattergram cursus Statistiek
 cursus 23 mei 2012 werkcollege 8 correlatie, regressie - D&P5: Summarizing Bivariate Data relatie tussen variabelen onderzoek streeft naar inzicht in relatie tussen variabelen bv. tussen onafhankelijke
cursus 23 mei 2012 werkcollege 8 correlatie, regressie - D&P5: Summarizing Bivariate Data relatie tussen variabelen onderzoek streeft naar inzicht in relatie tussen variabelen bv. tussen onafhankelijke
Waar waren we? Onderzoekspracticum BCO ANALYSEPLAN. Soorten gegevens. Documentatie. Kwalitatieve gegevens. Coderen kwalitatieve gegevens
 Waar waren we? BCO ANALYSEPLAN Harry Ganzeboom 14 april 2005 Probleemstelling, deelvragen, theorie Definities, conceptueel model Hypothesen Onderzoekzoeksopzet, operationalisatie Dataverzameling Data-analyse
Waar waren we? BCO ANALYSEPLAN Harry Ganzeboom 14 april 2005 Probleemstelling, deelvragen, theorie Definities, conceptueel model Hypothesen Onderzoekzoeksopzet, operationalisatie Dataverzameling Data-analyse
Valid N Missing N
 Tabel 1: Frequentieverdelingen, gemiddelden en spreiding van opleidingen van respondenten en partners (naar geslacht) en vaders en moeders van de respondent. Respondenten Partners Ouders Mannen Vrouwen
Tabel 1: Frequentieverdelingen, gemiddelden en spreiding van opleidingen van respondenten en partners (naar geslacht) en vaders en moeders van de respondent. Respondenten Partners Ouders Mannen Vrouwen
College 7. Regressie-analyse en Variantie verklaren. Inleiding M&T Hemmo Smit
 College 7 Regressie-analyse en Variantie verklaren Inleiding M&T 2012 2013 Hemmo Smit Neem mee naar tentamen Geslepen potlood + gum Collegekaart (alternatief: rijbewijs, ID-kaart, paspoort) (Grafische)
College 7 Regressie-analyse en Variantie verklaren Inleiding M&T 2012 2013 Hemmo Smit Neem mee naar tentamen Geslepen potlood + gum Collegekaart (alternatief: rijbewijs, ID-kaart, paspoort) (Grafische)
Masterclass: advanced statistics. Bianca de Greef Sander van Kuijk Afdeling KEMTA
 Masterclass: advanced statistics Bianca de Greef Sander van Kuijk Afdeling KEMTA Inhoud Masterclass Deel 1 (theorie): Achtergrond regressie Deel 2 (voorbeeld): Keuzes Output Model Model Dependent variable
Masterclass: advanced statistics Bianca de Greef Sander van Kuijk Afdeling KEMTA Inhoud Masterclass Deel 1 (theorie): Achtergrond regressie Deel 2 (voorbeeld): Keuzes Output Model Model Dependent variable
Bij factor ANOVA is er een tweede onafhankelijke variabele in de analyse bij gekomen. Er zijn drie soorten designs mogelijk:
 13. Factor ANOVA De theorie achter factor ANOVA (tussengroep) Bij factor ANOVA is er een tweede onafhankelijke variabele in de analyse bij gekomen. Er zijn drie soorten designs mogelijk: 1. Onafhankelijke
13. Factor ANOVA De theorie achter factor ANOVA (tussengroep) Bij factor ANOVA is er een tweede onafhankelijke variabele in de analyse bij gekomen. Er zijn drie soorten designs mogelijk: 1. Onafhankelijke
Enkelvoudige lineaire regressie
 Enkelvoudige lineaire regressie Inleiding Dit hoofdstuk sluit aan op hoofdstuk I-9 van het statistiekboek. Er wordt hier steeds gesproken over het verband tussen één afhankelijke variabele Y en één onafhankelijke
Enkelvoudige lineaire regressie Inleiding Dit hoofdstuk sluit aan op hoofdstuk I-9 van het statistiekboek. Er wordt hier steeds gesproken over het verband tussen één afhankelijke variabele Y en één onafhankelijke
1. Reductie van error variantie en dus verhogen van power op F-test
 Werkboek 2013-2014 ANCOVA Covariantie analyse bestaat uit regressieanalyse en variantieanalyse. Er wordt een afhankelijke variabele (intervalniveau) voorspeld uit meerdere onafhankelijke variabelen. De
Werkboek 2013-2014 ANCOVA Covariantie analyse bestaat uit regressieanalyse en variantieanalyse. Er wordt een afhankelijke variabele (intervalniveau) voorspeld uit meerdere onafhankelijke variabelen. De
Deze opdracht lossen we eenvoudig op door in de vergelijking X1 en X2 te vervangen door de geobserveerde waarden van deze variabelen:
 INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 10 1. Volgende regressievergelijking werd opgesteld na onderzoek: YY ii = 6 + 2.5 XX ii1 + 3 XX ii2 + εε ii Bereken de voorspelde
INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 10 1. Volgende regressievergelijking werd opgesteld na onderzoek: YY ii = 6 + 2.5 XX ii1 + 3 XX ii2 + εε ii Bereken de voorspelde
mlw stroom 2.2 Biostatistiek en Epidemiologie College 9: Herhaalde metingen (2) Syllabus Afhankelijke Data Hoofdstuk 4, 5.1, 5.2
 Syllabus Afhankelijke Data Hoofdstuk 4, 5.1, 5.2") mlw stroom 2.2 Biostatistiek en Epidemiologie College 9: Herhaalde metingen (2) Syllabus Afhankelijke Data Hoofdstuk 4, 5.1, 5.2 Bjorn Winkens Methodologie en Statistiek Universiteit Maastricht 21 maart
mlw stroom 2.2 Biostatistiek en Epidemiologie College 9: Herhaalde metingen (2) Syllabus Afhankelijke Data Hoofdstuk 4, 5.1, 5.2 Bjorn Winkens Methodologie en Statistiek Universiteit Maastricht 21 maart
Oplossingen hoofdstuk XI
 Oplossingen hoofdstuk XI. Hierbij vind je de resultaten van het onderzoek naar de relatie tussen een leestest en een schoolrapport voor lezen. Deze gegevens hebben betrekking op een regressieanalyse bij
Oplossingen hoofdstuk XI. Hierbij vind je de resultaten van het onderzoek naar de relatie tussen een leestest en een schoolrapport voor lezen. Deze gegevens hebben betrekking op een regressieanalyse bij
Meervoudige lineaire regressie
 Meervoudige lineaire regressie Inleiding In dit hoofdstuk dat aansluit op hoofdstuk II- (deel 2) wordt uitgelegd hoe een meervoudige regressieanalyse uitgevoerd kan worden met behulp van SPSS. Aan de hand
Meervoudige lineaire regressie Inleiding In dit hoofdstuk dat aansluit op hoofdstuk II- (deel 2) wordt uitgelegd hoe een meervoudige regressieanalyse uitgevoerd kan worden met behulp van SPSS. Aan de hand
Theorie en Empirisch Onderzoek. Werkcollege 4.3 Experimenteel onderzoek Rijken & Merz. 2014
 Theorie en Empirisch Onderzoek Werkcollege 4.3 Experimenteel onderzoek Rijken & Merz. 2014 Te bespreken Rijken & Merz Wat is hier de hoofdvraag? Wat is een double standard en hoe is het hier gemodelleerd?
Theorie en Empirisch Onderzoek Werkcollege 4.3 Experimenteel onderzoek Rijken & Merz. 2014 Te bespreken Rijken & Merz Wat is hier de hoofdvraag? Wat is een double standard en hoe is het hier gemodelleerd?
Hoofdstuk 10: Regressie
 Hoofdstuk 10: Regressie Inleiding In dit deel zal uitgelegd worden hoe we statistische berekeningen kunnen maken als sprake is van één kwantitatieve responsvariabele en één kwantitatieve verklarende variabele.
Hoofdstuk 10: Regressie Inleiding In dit deel zal uitgelegd worden hoe we statistische berekeningen kunnen maken als sprake is van één kwantitatieve responsvariabele en één kwantitatieve verklarende variabele.
11. Meerdere gemiddelden vergelijken, ANOVA
 11. Meerdere gemiddelden vergelijken, ANOVA Analyse van variantie (ANOVA) wordt gebruikt wanneer er situaties zijn waarbij er meer dan twee condities vergeleken worden. In dit hoofdstuk wordt de onafhankelijke
11. Meerdere gemiddelden vergelijken, ANOVA Analyse van variantie (ANOVA) wordt gebruikt wanneer er situaties zijn waarbij er meer dan twee condities vergeleken worden. In dit hoofdstuk wordt de onafhankelijke
DEEL 1 Probleemstelling 1
 DEEL 1 Probleemstelling 1 Hoofdstuk 1 Van Probleem naar Analyse 1.1 Notatie 4 1.1.1 Types variabelen 4 1.1.2 Types samenhang 5 1.2 Sociaalwetenschappelijke probleemstellingen en hun basisformat 6 1.2.1
DEEL 1 Probleemstelling 1 Hoofdstuk 1 Van Probleem naar Analyse 1.1 Notatie 4 1.1.1 Types variabelen 4 1.1.2 Types samenhang 5 1.2 Sociaalwetenschappelijke probleemstellingen en hun basisformat 6 1.2.1
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica. Tentamenopgaven Statistiek (2DD71) op xx-xx-xxxx, xx.00-xx.00 uur.
 op xx-xx-xxxx, xx.00-xx.00 uur.") VOORAF: Hieronder staat een aantal opgaven over de stof. Veel meer dan op het tentamen zelf gevraagd zullen worden. Op het tentamen zullen in totaal 20 onderdelen gevraagd worden. TECHNISCHE UNIVERSITEIT
VOORAF: Hieronder staat een aantal opgaven over de stof. Veel meer dan op het tentamen zelf gevraagd zullen worden. Op het tentamen zullen in totaal 20 onderdelen gevraagd worden. TECHNISCHE UNIVERSITEIT
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica. Tentamen Statistiek 2 voor TeMa (2S195) op vrijdag , 9-12 uur.
 op vrijdag , 9-12 uur.") TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek 2 voor TeMa (2S95) op vrijdag 29-04-2004, 9-2 uur. Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek 2 voor TeMa (2S95) op vrijdag 29-04-2004, 9-2 uur. Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
2.9 Het adolescentieonderzoek 69 2.10 Opgaven 72
 Inhoud Hoofdstuk 1 Design en analyse 11 1.1 Specificatie van designs 13 1.2 Definities 14 1.3 Het verschil tussen een afhankelijke variabele en een niveau van een within-subjectfactor 19 1.4 Kiezen van
Inhoud Hoofdstuk 1 Design en analyse 11 1.1 Specificatie van designs 13 1.2 Definities 14 1.3 Het verschil tussen een afhankelijke variabele en een niveau van een within-subjectfactor 19 1.4 Kiezen van
Bijlage 3: Multiple regressie analyse
 Bijlage 3: Multiple regressie analyse REGRESSION /DESCRIPTIVES MEAN STDDEV CORR SIG N /MISSING PAIRWISE /STATISTICS COEFF OUTS CI(95) R ANOVA COLLIN TOL ZPP /CRITERIA=PIN(.05) POUT(.10) /NOORIGIN /DEPENDENT
Bijlage 3: Multiple regressie analyse REGRESSION /DESCRIPTIVES MEAN STDDEV CORR SIG N /MISSING PAIRWISE /STATISTICS COEFF OUTS CI(95) R ANOVA COLLIN TOL ZPP /CRITERIA=PIN(.05) POUT(.10) /NOORIGIN /DEPENDENT
Hoofdstuk 2: Verbanden
 Hoofdstuk 2: Verbanden Inleiding In het gebruik van statistiek komen we vaak relaties tussen variabelen tegen. De focus van dit hoofdstuk ligt op het leren hoe deze relaties op grafische en numerieke wijze
Hoofdstuk 2: Verbanden Inleiding In het gebruik van statistiek komen we vaak relaties tussen variabelen tegen. De focus van dit hoofdstuk ligt op het leren hoe deze relaties op grafische en numerieke wijze
Data analyse Inleiding statistiek
 Data analyse Inleiding statistiek Terugblik - Inductieve statistiek Afleiden van eigenschappen van een populatie op basis van een beperkt aantal metingen (steekproef) Kennis gemaakt met kans & kansverdelingen
Data analyse Inleiding statistiek Terugblik - Inductieve statistiek Afleiden van eigenschappen van een populatie op basis van een beperkt aantal metingen (steekproef) Kennis gemaakt met kans & kansverdelingen
Aanpassingen takenboek! Statistische toetsen. Deze persoon in een verdeling. Iedereen in een verdeling
 Kwantitatieve Data Analyse (KDA) Onderzoekspracticum Sessie 2 11 Aanpassingen takenboek! Check studienet om eventuele verbeteringen te downloaden! Huidige versie takenboek: 09 Gjalt-Jorn Peters gjp@ou.nl
Kwantitatieve Data Analyse (KDA) Onderzoekspracticum Sessie 2 11 Aanpassingen takenboek! Check studienet om eventuele verbeteringen te downloaden! Huidige versie takenboek: 09 Gjalt-Jorn Peters gjp@ou.nl
Wat gaan we doen? Help! Statistiek! Wat is een lineaire relatie? De rechte-lijn-vergelijking: Y = a + b X. Relatie tussen gewicht en lengte
 Help! Statistiek! Wat gaan we doen? Doel: Informeren over statistiek in klinisch onderzoek. Tijd: Doorlopende serie laagdrempelige lezingen, voor iedereen vrij toegankelijk. Derde woensdag in de maand,
Help! Statistiek! Wat gaan we doen? Doel: Informeren over statistiek in klinisch onderzoek. Tijd: Doorlopende serie laagdrempelige lezingen, voor iedereen vrij toegankelijk. Derde woensdag in de maand,
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor T (2S070) op vrijdag 8 oktober 1999, uur De u
 op vrijdag 8 oktober 1999, uur De u") TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor T (2S070) op vrijdag 8 oktober 1999, 14.00-17.00 uur De uitwerkingen van de opgaven dienen duidelijk geformuleerd
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor T (2S070) op vrijdag 8 oktober 1999, 14.00-17.00 uur De uitwerkingen van de opgaven dienen duidelijk geformuleerd
Verband tussen twee variabelen
 Verband tussen twee variabelen Inleiding Dit practicum sluit aan op hoofdstuk I-3 van het statistiekboek en geeft uitleg over het maken van kruistabellen, het berekenen van de correlatiecoëfficiënt en
Verband tussen twee variabelen Inleiding Dit practicum sluit aan op hoofdstuk I-3 van het statistiekboek en geeft uitleg over het maken van kruistabellen, het berekenen van de correlatiecoëfficiënt en
Robuustheid regressiemodel voor kapitaalkosten gebaseerd op aansluitdichtheid
 Robuustheid regressiemodel voor kapitaalkosten gebaseerd op aansluitdichtheid Dr.ir. P.W. Heijnen Faculteit Techniek, Bestuur en Management Technische Universiteit Delft 6 mei 2010 1 1 Introductie De Energiekamer
Robuustheid regressiemodel voor kapitaalkosten gebaseerd op aansluitdichtheid Dr.ir. P.W. Heijnen Faculteit Techniek, Bestuur en Management Technische Universiteit Delft 6 mei 2010 1 1 Introductie De Energiekamer
Classification - Prediction
 Classification - Prediction Tot hiertoe: vooral classification Naive Bayes k-nearest Neighbours... Op basis van predictor variabelen X 1, X 2,..., X p klasse Y (= discreet) proberen te bepalen. Training
Classification - Prediction Tot hiertoe: vooral classification Naive Bayes k-nearest Neighbours... Op basis van predictor variabelen X 1, X 2,..., X p klasse Y (= discreet) proberen te bepalen. Training
Robuustheid regressiemodel voor kapitaalkosten gebaseerd op aansluitdichtheid
 Robuustheid regressiemodel voor kapitaalkosten gebaseerd op aansluitdichtheid Dr.ir. P.W. Heijnen Faculteit Techniek, Bestuur en Management Technische Universiteit Delft 22 april 2010 1 1 Introductie De
Robuustheid regressiemodel voor kapitaalkosten gebaseerd op aansluitdichtheid Dr.ir. P.W. Heijnen Faculteit Techniek, Bestuur en Management Technische Universiteit Delft 22 april 2010 1 1 Introductie De
Dummyvariabelen in meervoudige regressie
 UNIVERSITEIT GENT Department of Sociology Korte Meer 3 9000 Gent Belgium Phone: +32(0)9 264.67.96 Fax: +32(0)9 264.69.75 Email: socio@ugent.be Dummyvariabelen in meervoudige regressie Een inleiding voor
UNIVERSITEIT GENT Department of Sociology Korte Meer 3 9000 Gent Belgium Phone: +32(0)9 264.67.96 Fax: +32(0)9 264.69.75 Email: socio@ugent.be Dummyvariabelen in meervoudige regressie Een inleiding voor
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica. Tentamen Statistiek 2 voor TeMa (2S195) op dinsdag , uur.
 op dinsdag , uur.") TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor TeMa (S95) op dinsdag 3-03-00, 9- uur. Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor TeMa (S95) op dinsdag 3-03-00, 9- uur. Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en
Meervoudige ANOVA Onderzoeksvraag Voorwaarden
 Er is onderzoek gedaan naar rouw na het overlijden van een huisdier (contactpersoon: Karolijne van der Houwen (Klinische Psychologie)). Mensen konden op internet een vragenlijst invullen. Daarin werd gevraagd
Er is onderzoek gedaan naar rouw na het overlijden van een huisdier (contactpersoon: Karolijne van der Houwen (Klinische Psychologie)). Mensen konden op internet een vragenlijst invullen. Daarin werd gevraagd
laboratory for industrial mathematics eindhoven Endinet Regressie-analyse Energiekamer
 Endinet Regressie-analyse Energiekamer Laboratory for Industrial Mathematics Eindhoven Postbus 513 5600 MB Eindhoven tel.: 040 247 4875 fax: 040 244 2489 e-mail: lime@tue.nl WWW: http://www.lime.tue.nl
Endinet Regressie-analyse Energiekamer Laboratory for Industrial Mathematics Eindhoven Postbus 513 5600 MB Eindhoven tel.: 040 247 4875 fax: 040 244 2489 e-mail: lime@tue.nl WWW: http://www.lime.tue.nl
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica. Tentamen Statistiek 2 voor TeMa (2S195) op dinsdag ,
 op dinsdag ,") TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek 2 voor TeMa (2S95) op dinsdag 5-03-2005, 9.00-22.00 uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek 2 voor TeMa (2S95) op dinsdag 5-03-2005, 9.00-22.00 uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
Experimenteel en Correlationeel Onderzoek
 Experimenteel en Correlationeel Onderzoek In veel onderzoek is het doel: Het vaststellen van oorzaak-gevolg (causale) relaties Criteria voor causaliteit 1. Samenhang (correlatie, covariantie) 2. Opeenvolging
Experimenteel en Correlationeel Onderzoek In veel onderzoek is het doel: Het vaststellen van oorzaak-gevolg (causale) relaties Criteria voor causaliteit 1. Samenhang (correlatie, covariantie) 2. Opeenvolging
1 vorig = omzet voorgaande jaar. Forward (Criterion: Probability-of-F-to-enter <=,050) 2 bezoek = aantal bezoeken vertegenwoordiger
 2 bezoek = aantal bezoeken vertegenwoordiger") De groothandel Onderwerp: regressieanalyse met SPSS Bij: hoofdstuk 10 Een groothandel heeft onderzoek gedaan onder de klanten en daarbij geprobeerd met regressieanalyse vast te stellen wat de bepalende
De groothandel Onderwerp: regressieanalyse met SPSS Bij: hoofdstuk 10 Een groothandel heeft onderzoek gedaan onder de klanten en daarbij geprobeerd met regressieanalyse vast te stellen wat de bepalende
Hoofdstuk 12: Eenweg ANOVA
 Hoofdstuk 12: Eenweg ANOVA 12.1 Eenweg analyse van variantie Eenweg en tweeweg ANOVA Wanneer we verschillende populaties of behandelingen met elkaar vergelijken, dan zal er binnen de data altijd sprake
Hoofdstuk 12: Eenweg ANOVA 12.1 Eenweg analyse van variantie Eenweg en tweeweg ANOVA Wanneer we verschillende populaties of behandelingen met elkaar vergelijken, dan zal er binnen de data altijd sprake
Meten: algemene beginselen. Harry B.G. Ganzeboom ADEK UvS College 1 28 februari 2011
 Meten: algemene Harry B.G. Ganzeboom ADEK UvS College 1 28 februari 2011 OPZET College 1: Algemene College 2: Meting van attitudes (ISSP) College 3: Meting van achtergrondvariabelen via MTMM College 4:
Meten: algemene Harry B.G. Ganzeboom ADEK UvS College 1 28 februari 2011 OPZET College 1: Algemene College 2: Meting van attitudes (ISSP) College 3: Meting van achtergrondvariabelen via MTMM College 4:
HOOFDSTUK VIII VARIANTIE ANALYSE (ANOVA)
") HOOFDSTUK VIII VARIANTIE ANALYSE (ANOVA) DATA STRUKTUUR Afhankelijke variabele: Eén kontinue variabele Onafhankelijke variabele(n): - één discrete variabele: één gecontroleerde factor - twee discrete variabelen:
HOOFDSTUK VIII VARIANTIE ANALYSE (ANOVA) DATA STRUKTUUR Afhankelijke variabele: Eén kontinue variabele Onafhankelijke variabele(n): - één discrete variabele: één gecontroleerde factor - twee discrete variabelen:
Toegepaste Statistiek, Dag 7 1
 Toegepaste Statistiek, Dag 7 1 Statistiek: Afkomstig uit het Duits: De studie van politieke feiten en cijfers. Afgeleid uit het latijn: status, staat, toestand Belangrijkste associatie: beschrijvende statistiek
Toegepaste Statistiek, Dag 7 1 Statistiek: Afkomstig uit het Duits: De studie van politieke feiten en cijfers. Afgeleid uit het latijn: status, staat, toestand Belangrijkste associatie: beschrijvende statistiek
Tentamen Biostatistiek 1 voor BMT (2DM40) woensdag 2 november 2011, uur
 woensdag 2 november 2011, uur") Faculteit der Wiskunde en Informatica Tentamen Biostatistiek 1 voor BMT (2DM40) woensdag 2 november 2011, 9.00-12.00 uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en van een onbeschreven
Faculteit der Wiskunde en Informatica Tentamen Biostatistiek 1 voor BMT (2DM40) woensdag 2 november 2011, 9.00-12.00 uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en van een onbeschreven
Inhoud. Woord vooraf 13. Hoofdstuk 1. Inductieve statistiek in onderzoek 17. Hoofdstuk 2. Kansverdelingen en kansberekening 28
 Inhoud Woord vooraf 13 Hoofdstuk 1. Inductieve statistiek in onderzoek 17 1.1 Wat is de bedoeling van statistiek? 18 1.2 De empirische cyclus 19 1.3 Het probleem van de inductieve statistiek 20 1.4 Statistische
Inhoud Woord vooraf 13 Hoofdstuk 1. Inductieve statistiek in onderzoek 17 1.1 Wat is de bedoeling van statistiek? 18 1.2 De empirische cyclus 19 1.3 Het probleem van de inductieve statistiek 20 1.4 Statistische
b. Bepaal b1 en b0 en geef de vergelijking van de kleinste-kwadratenlijn.
 Opdracht 12a ------------ enkelvoudige lineaire regressie Kan de leeftijd waarop een kind begint te spreken voorspellen hoe zijn score zal zijn bij een latere test op verstandelijke vermogens? Een studie
Opdracht 12a ------------ enkelvoudige lineaire regressie Kan de leeftijd waarop een kind begint te spreken voorspellen hoe zijn score zal zijn bij een latere test op verstandelijke vermogens? Een studie
20. Multilevel lineaire modellen
 20. Multilevel lineaire modellen Hiërarchische gegevens Veel fenomenen zijn ingebed in een bredere context. Variabelen kunnen dus ook hiërarchisch zijn, ingebed zijn in variabelen op hogere niveaus. Deze
20. Multilevel lineaire modellen Hiërarchische gegevens Veel fenomenen zijn ingebed in een bredere context. Variabelen kunnen dus ook hiërarchisch zijn, ingebed zijn in variabelen op hogere niveaus. Deze
LES 2: Data-cleaning en -transformatie 1. Frequentietabel
 Methoden SPSS hoe en waarom LES 1: Introductie SPSS 1. Basiskennis SPSS Eerst 3 stappen uitvoeren in de databank: 1. Definitie van variabelen = variabelen invoegen en values definiëren = missing values
Methoden SPSS hoe en waarom LES 1: Introductie SPSS 1. Basiskennis SPSS Eerst 3 stappen uitvoeren in de databank: 1. Definitie van variabelen = variabelen invoegen en values definiëren = missing values
Tentamen Biostatistiek 1 voor BMT (2DM40), op maandag 5 januari 2009 14.00-17.00 uur
, op maandag 5 januari 2009 14.00-17.00 uur") Faculteit der Wiskunde en Informatica Tentamen Biostatistiek voor BMT (2DM4), op maandag 5 januari 29 4.-7. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en van een onbeschreven
Faculteit der Wiskunde en Informatica Tentamen Biostatistiek voor BMT (2DM4), op maandag 5 januari 29 4.-7. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en van een onbeschreven
Statistiek II. Sessie 4. Feedback Deel 4
 Statistiek II Sessie 4 Feedback Deel 4 VPPK Universiteit Gent 2017-2018 Feedback Oefensessie 4 We hebben besloten de bekomen grafieken in R niet in het document in te voegen, dit omdat het document met
Statistiek II Sessie 4 Feedback Deel 4 VPPK Universiteit Gent 2017-2018 Feedback Oefensessie 4 We hebben besloten de bekomen grafieken in R niet in het document in te voegen, dit omdat het document met
Statistiek II. Sessie 3. Verzamelde vragen en feedback Deel 3
 Statistiek II Sessie 3 Verzamelde vragen en feedback Deel 3 VPPK Universiteit Gent 2017-2018 Feedback Oefensessie 3 1 Statismex en bloeddruk 1. Afhankelijke variabele: Bloeddruk (van ratio-niveau) Onafhankelijke
Statistiek II Sessie 3 Verzamelde vragen en feedback Deel 3 VPPK Universiteit Gent 2017-2018 Feedback Oefensessie 3 1 Statismex en bloeddruk 1. Afhankelijke variabele: Bloeddruk (van ratio-niveau) Onafhankelijke
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica
 TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor TeMa (S95) Avondopleiding. donderdag 6-6-3, 9.-. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor TeMa (S95) Avondopleiding. donderdag 6-6-3, 9.-. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
Statistiek II. Sessie 5. Feedback Deel 5
 Statistiek II Sessie 5 Feedback Deel 5 VPPK Universiteit Gent 2017-2018 Feedback Oefensessie 5 1 Statismex, gewicht en slaperigheid2 1. Lineair model: slaperigheid2 = β 0 + β 1 dosis + β 2 bd + ε H 0 :
Statistiek II Sessie 5 Feedback Deel 5 VPPK Universiteit Gent 2017-2018 Feedback Oefensessie 5 1 Statismex, gewicht en slaperigheid2 1. Lineair model: slaperigheid2 = β 0 + β 1 dosis + β 2 bd + ε H 0 :
Algemeen lineair model
 Algemeen lineair model Lieven Clement 2 de bach. in de Biologie, Chemie, Biochemie en Biotechnologie en Biomedische Wetenschappen statomics, Ghent University lieven.clement@ugent.be 1/57 Inleiding Tot
Algemeen lineair model Lieven Clement 2 de bach. in de Biologie, Chemie, Biochemie en Biotechnologie en Biomedische Wetenschappen statomics, Ghent University lieven.clement@ugent.be 1/57 Inleiding Tot
Opgaven hoofdstuk 12 Enkelvoudige lineaire regressie
 Opgaven hoofdstuk 12 Enkelvoudige lineaire regressie 12.1 Teken voor elk van de volgende gevallen de lijn die door de gegeven punten gaat. a. (1,1) en (5,5). b. (0,3) en (3,0) c. ( 1,1) en (4,2) d. ( 6,
Opgaven hoofdstuk 12 Enkelvoudige lineaire regressie 12.1 Teken voor elk van de volgende gevallen de lijn die door de gegeven punten gaat. a. (1,1) en (5,5). b. (0,3) en (3,0) c. ( 1,1) en (4,2) d. ( 6,
Disclosure Belangen Spreker
 1 Geen (potentiële) belangenverstengeling Disclosure Belangen Spreker Voor bijeenkomst mogelijk relevante relaties: Sponsoring of onderzoeksgeld - Honorarium of andere (financiële ) vergoedingen Aandeelhouder
1 Geen (potentiële) belangenverstengeling Disclosure Belangen Spreker Voor bijeenkomst mogelijk relevante relaties: Sponsoring of onderzoeksgeld - Honorarium of andere (financiële ) vergoedingen Aandeelhouder
College 6 Eenweg Variantie-Analyse
 College 6 Eenweg Variantie-Analyse - Leary: Hoofdstuk 11, 1 (t/m p. 55) - MM&C: Hoofdstuk 1 (t/m p. 617), p. 63 t/m p. 66 - Aanvullende tekst 6, 7 en 8 Jolien Pas ECO 01-013 Het Experiment: een voorbeeld
College 6 Eenweg Variantie-Analyse - Leary: Hoofdstuk 11, 1 (t/m p. 55) - MM&C: Hoofdstuk 1 (t/m p. 617), p. 63 t/m p. 66 - Aanvullende tekst 6, 7 en 8 Jolien Pas ECO 01-013 Het Experiment: een voorbeeld
HOOFDSTUK 2: VERBANDEN
 HOOFDSTUK 2: VERBANDEN Inleiding In het gebruik van statistiek komen we vaak relaties tussen variabelen tegen. De focus van dit hoodfstuk ligt op het leren hoe deze relaties op grafische en numerieke wijze
HOOFDSTUK 2: VERBANDEN Inleiding In het gebruik van statistiek komen we vaak relaties tussen variabelen tegen. De focus van dit hoodfstuk ligt op het leren hoe deze relaties op grafische en numerieke wijze
Bachelorproject II College 1: Validiteit en betrouwbaarheid: factor- en betrouwbaarheidsanalyse. Harry BG Ganzeboom 5 januari 2016 Bijgewerkt in rood
 Bachelorproject II College 1: Validiteit en betrouwbaarheid: factor- en betrouwbaarheidsanalyse Harry BG Ganzeboom 5 januari 2016 Bijgewerkt in rood App.gosoapbox.com en gebruik telkens de volgende inlogcode:
Bachelorproject II College 1: Validiteit en betrouwbaarheid: factor- en betrouwbaarheidsanalyse Harry BG Ganzeboom 5 januari 2016 Bijgewerkt in rood App.gosoapbox.com en gebruik telkens de volgende inlogcode:
Statistiek II. 1. Eenvoudig toetsen. Onderdeel toetsen binnen de cursus: Toetsen en schatten ivm één statistiek of steekproef
 Statistiek II Onderdeel toetsen binnen de cursus: 1. Eenvoudig toetsen Toetsen en schatten ivm één statistiek of steekproef Via de z-verdeling, als µ onderzocht wordt en gekend is: Via de t-verdeling,
Statistiek II Onderdeel toetsen binnen de cursus: 1. Eenvoudig toetsen Toetsen en schatten ivm één statistiek of steekproef Via de z-verdeling, als µ onderzocht wordt en gekend is: Via de t-verdeling,
Opgave 1: (zowel 2DM40 als 2S390)
") TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Biostatistiek voor BMT (DM4 en S39) op donderdag, 4.-7. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Biostatistiek voor BMT (DM4 en S39) op donderdag, 4.-7. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
6 De relatie tussen de intentie tot exploratie, binding en delinquent gedrag
 6 De relatie tussen de intentie tot exploratie, binding en delinquent gedrag 6.1 Inleiding Is de toe- en afname van het aantal jongeren met delinquent gedrag in de adolescentie een gevolg van de intentie
6 De relatie tussen de intentie tot exploratie, binding en delinquent gedrag 6.1 Inleiding Is de toe- en afname van het aantal jongeren met delinquent gedrag in de adolescentie een gevolg van de intentie
SPSS. Statistiek : SPSS
 SPSS - hoofdstuk 1 : 1.4. fase 4 : verrichten van metingen en / of verzamelen van gegevens Gegevens gevonden bij een onderzoek worden systematisch weergegeven in een datamatrix bij SPSS De datamatrix Gebruik
SPSS - hoofdstuk 1 : 1.4. fase 4 : verrichten van metingen en / of verzamelen van gegevens Gegevens gevonden bij een onderzoek worden systematisch weergegeven in een datamatrix bij SPSS De datamatrix Gebruik
College 6. Samenhang tussen variabelen. Inleiding M&T Hemmo Smit
 College 6 Samenhang tussen variabelen Inleiding M&T 2012 2013 Hemmo Smit Overzicht van deze cursus 1. Grondprincipes van de wetenschap 2. Observeren en meten 3. Interne consistentie; Beschrijvend onderzoek
College 6 Samenhang tussen variabelen Inleiding M&T 2012 2013 Hemmo Smit Overzicht van deze cursus 1. Grondprincipes van de wetenschap 2. Observeren en meten 3. Interne consistentie; Beschrijvend onderzoek
Toegepaste data-analyse: oefensessie 2
 Toegepaste data-analyse: oefensessie 2 Depressie 1. Beschrijf de clustering van de dataset en geef aan op welk niveau de verschillende variabelen behoren Je moet weten hoe de data geclusterd zijn om uit
Toegepaste data-analyse: oefensessie 2 Depressie 1. Beschrijf de clustering van de dataset en geef aan op welk niveau de verschillende variabelen behoren Je moet weten hoe de data geclusterd zijn om uit
Hoofdstuk 8 Het toetsen van nonparametrische variabelen
 Hoofdstuk 8 Het toetsen van nonparametrische variabelen 8.1 Non-parametrische toetsen: deze toetsen zijn toetsen waarbij de aannamen van normaliteit en intervalniveau niet nodig zijn. De aannamen zijn
Hoofdstuk 8 Het toetsen van nonparametrische variabelen 8.1 Non-parametrische toetsen: deze toetsen zijn toetsen waarbij de aannamen van normaliteit en intervalniveau niet nodig zijn. De aannamen zijn
Enkelvoudige ANOVA Onderzoeksvraag Voorwaarden
 Er is onderzoek gedaan naar rouw na het overlijden van een huisdier (contactpersoon: Karolijne van der Houwen (Klinische Psychologie)). Mensen konden op internet een vragenlijst invullen. Daarin werd gevraagd
Er is onderzoek gedaan naar rouw na het overlijden van een huisdier (contactpersoon: Karolijne van der Houwen (Klinische Psychologie)). Mensen konden op internet een vragenlijst invullen. Daarin werd gevraagd
Spreidingsdiagram, kleinste-kwadraten regressielijn, correlatiecoefficient
 Opdracht 4a ----------- Spreidingsdiagram, kleinste-kwadraten regressielijn, correlatiecoefficient In 1738 werd in de haven van Stockholm voor een aantal landen voor elk land geregistreerd hoeveel schepen
Opdracht 4a ----------- Spreidingsdiagram, kleinste-kwadraten regressielijn, correlatiecoefficient In 1738 werd in de haven van Stockholm voor een aantal landen voor elk land geregistreerd hoeveel schepen
16. MANOVA. Overeenkomsten en verschillen met ANOVA. De theorie MANOVA
 16. MANOVA MANOVA Multivariate variantieanalyse (MANOVA) kan gebruikt worden in een situatie waarin je meerdere afhankelijke variabelen hebt. Met MANOVA kan er 1 onafhankelijke variabele gebruikt worden
16. MANOVA MANOVA Multivariate variantieanalyse (MANOVA) kan gebruikt worden in een situatie waarin je meerdere afhankelijke variabelen hebt. Met MANOVA kan er 1 onafhankelijke variabele gebruikt worden
Bij herhaalde metingen ANOVA komt het effect van het experiment naar voren bij de variantie binnen participanten. Bij de gewone ANOVA is dit de SS R
 14. Herhaalde metingen Introductie Bij herhaalde metingen worden er bij verschillende condities in een experiment dezelfde proefpersonen gebruikt of waarbij dezelfde proefpersonen op verschillende momenten
14. Herhaalde metingen Introductie Bij herhaalde metingen worden er bij verschillende condities in een experiment dezelfde proefpersonen gebruikt of waarbij dezelfde proefpersonen op verschillende momenten
b) Het spreidingsdiagram ziet er als volgt uit (de getrokken lijn is de later uit te rekenen lineaire regressie-lijn): hoogte
 Het spreidingsdiagram ziet er als volgt uit (de getrokken lijn is de later uit te rekenen lineaire regressie-lijn): hoogte") Classroom Exercises GEO2-4208 Opgave 7.1 a) Regressie-analyse dicteert hier geen stricte regels voor. Wanneer we echter naar causaliteit kijken (wat wordt door wat bepaald), dan is het duidelijk dat hoogte
Classroom Exercises GEO2-4208 Opgave 7.1 a) Regressie-analyse dicteert hier geen stricte regels voor. Wanneer we echter naar causaliteit kijken (wat wordt door wat bepaald), dan is het duidelijk dat hoogte
Voorbeeldtentamen Statistiek voor Psychologie
 Voorbeeldtentamen Statistiek voor Psychologie 1) Vul de volgende uitspraak aan, zodat er een juiste bewering ontstaat: De verdeling van een variabele geeft een opsomming van de categorieën en geeft daarbij
Voorbeeldtentamen Statistiek voor Psychologie 1) Vul de volgende uitspraak aan, zodat er een juiste bewering ontstaat: De verdeling van een variabele geeft een opsomming van de categorieën en geeft daarbij
Rapport. Rapportage Bijzondere Bijstand 2013
 w Rapport Rapportage Bijzondere Bijstand 2013 T.J. Slager en J. Weidum 14 november 2014 Samenvatting In 2013 is er in totaal 374 miljoen euro door gemeenten uitgegeven aan bijzondere bijstand. Het gaat
w Rapport Rapportage Bijzondere Bijstand 2013 T.J. Slager en J. Weidum 14 november 2014 Samenvatting In 2013 is er in totaal 374 miljoen euro door gemeenten uitgegeven aan bijzondere bijstand. Het gaat
1 Basisbegrippen, W / O voor waar/onwaar
 Naam - Toetsende Statistiek Rijksuniversiteit Groningen Lente Docent: John Nerbonne Tentamen di. 22 juni om 14 uur tentamenhal Belangrijke instructies 1. Schrijf uw naam & studentnummer hierboven, schrijf
Naam - Toetsende Statistiek Rijksuniversiteit Groningen Lente Docent: John Nerbonne Tentamen di. 22 juni om 14 uur tentamenhal Belangrijke instructies 1. Schrijf uw naam & studentnummer hierboven, schrijf
Examen Statistische Modellen en Data-analyse. Derde Bachelor Wiskunde. 14 januari 2008
 Examen Statistische Modellen en Data-analyse Derde Bachelor Wiskunde 14 januari 2008 Vraag 1 1. Stel dat ɛ N 3 (0, σ 2 I 3 ) en dat Y 0 N(0, σ 2 0) onafhankelijk is van ɛ = (ɛ 1, ɛ 2, ɛ 3 ). Definieer
Examen Statistische Modellen en Data-analyse Derde Bachelor Wiskunde 14 januari 2008 Vraag 1 1. Stel dat ɛ N 3 (0, σ 2 I 3 ) en dat Y 0 N(0, σ 2 0) onafhankelijk is van ɛ = (ɛ 1, ɛ 2, ɛ 3 ). Definieer
Tentamen Biostatistiek 2 voor BMT (2DM50), op woensdag 22 april uur
, op woensdag 22 april uur") Faculteit der Wiskunde en Informatica Tentamen Biostatistiek 2 voor BMT (2DM50), op woensdag 22 april 2009 9.00-12.00 uur Bij het tentamen mag alleen gebruik worden gemaakt van een zakrekenmachine. Het
Faculteit der Wiskunde en Informatica Tentamen Biostatistiek 2 voor BMT (2DM50), op woensdag 22 april 2009 9.00-12.00 uur Bij het tentamen mag alleen gebruik worden gemaakt van een zakrekenmachine. Het
Tentamen Biostatistiek 1 voor BMT (2DM40) woensdag 28 oktober 2009, 9.00-12.00 uur
 woensdag 28 oktober 2009, 9.00-12.00 uur") Faculteit der Wiskunde en Informatica Tentamen Biostatistiek voor BMT (DM4) woensdag 8 oktober 9, 9.-. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en van een onbeschreven Statistisch
Faculteit der Wiskunde en Informatica Tentamen Biostatistiek voor BMT (DM4) woensdag 8 oktober 9, 9.-. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en van een onbeschreven Statistisch
Logistische regressie analyse: een handleiding Inge Sieben 1 Liesbeth Linssen
 Logistische regressie analyse: een handleiding Inge Sieben 1 Liesbeth Linssen Inhoudsopgave: Wat is logistische regressie analyse Hoe stuur je logistische regressie analyse in SPSS aan Hoe interpreteer
Logistische regressie analyse: een handleiding Inge Sieben 1 Liesbeth Linssen Inhoudsopgave: Wat is logistische regressie analyse Hoe stuur je logistische regressie analyse in SPSS aan Hoe interpreteer
INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 5
 INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 5 1. De onderzoekers van een preventiedienst vermoeden dat werknemers in een bedrijf zonder liften fitter zijn dan werknemers
INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 5 1. De onderzoekers van een preventiedienst vermoeden dat werknemers in een bedrijf zonder liften fitter zijn dan werknemers
Herkansing Inleiding Intelligente Data Analyse Datum: Tijd: , BBL 508 Dit is geen open boek tentamen.
 Herkansing Inleiding Intelligente Data Analyse Datum: 3-3-2003 Tijd: 14.00-17.00, BBL 508 Dit is geen open boek tentamen. Algemene aanwijzingen 1. U mag ten hoogste één A4 met aantekeningen raadplegen.
Herkansing Inleiding Intelligente Data Analyse Datum: 3-3-2003 Tijd: 14.00-17.00, BBL 508 Dit is geen open boek tentamen. Algemene aanwijzingen 1. U mag ten hoogste één A4 met aantekeningen raadplegen.
HOOFDSTUK VI NIET-PARAMETRISCHE (VERDELINGSVRIJE) STATISTIEK
 STATISTIEK") HOOFDSTUK VI NIET-PARAMETRISCHE (VERDELINGSVRIJE) STATISTIEK 1 1. INLEIDING Parametrische statistiek: Normale Verdeling Niet-parametrische statistiek: Verdelingsvrij Keuze tussen de twee benaderingen I.
HOOFDSTUK VI NIET-PARAMETRISCHE (VERDELINGSVRIJE) STATISTIEK 1 1. INLEIDING Parametrische statistiek: Normale Verdeling Niet-parametrische statistiek: Verdelingsvrij Keuze tussen de twee benaderingen I.