Missing Data in Clinical Trials. Kristien Wouters Statisticus - Onderzoekscel
|
|
|
- Vera Sarah Verbeke
- 9 jaren geleden
- Aantal bezoeken:
Transcriptie

1 Missing Data in Clinical Trials Kristien Wouters Statisticus - Onderzoekscel

2 Overzicht Inleidend voorbeeld Missing data proces Missing data mechanisme Missing data patroon Methoden voor behandeling van missing data Vroeger Nu... Samenvatting en Conclusie

3 Overzicht Inleidend voorbeeld Missing data proces Missing data mechanisme Missing data patroon Methoden voor behandeling van missing data Vroeger Nu... Samenvatting en Conclusie

4 Inleiding: Voorbeeld Vergelijking behandeling A met B Power berekening: 50 patiënten per groep nodig 20% lost to follow-up

5 Inleiding: Voorbeeld Vergelijking behandeling A met B Power berekening: 50 patiënten per groep nodig 20% lost to follow-up Reductie van de power

6 Inleiding: Voorbeeld Vergelijking behandeling A met B Power berekening: 50 patiënten per groep nodig 20% lost to follow-up Reductie van de power Reductie van de variabiliteit Vertekend resultaat (bias)!

7 Redenen voor missing data Vraag niet ingevuld door patiënt Patiënt is verhuisd, niet meer bereikbaar Patiënt stopt met de studie Patientgerelateerd Overlijden patiënt Fout in labo waarden Machine stuk Niet patientgerelateerd

8 Redenen voor missing data Vraag niet ingevuld door patiënt Patiënt is verhuisd, niet meer bereikbaar Patiënt stopt met de studie Patientgerelateerd Overlijden patiënt Fout in labo waarden Machine stuk Niet patientgerelateerd Missing data mechanisme

9 Missing Data Mechanismen X variabelen zonder missings? M missing data proces Y variabelen met missings?

10 Missing Completely at Random (MCAR) Kans op ontbrekende waarde is onafhankelijk van alle andere geobserveerde en ongeobserveerde variabelen Patienten met/zonder missing data zijn een random steekproef van de populatie X MCAR M P (M Y, X) = P (M) Y

11 Voorbeeld: Bloeddruk studie Verloop van bloeddruk over de tijd 30 patiënten, maandelijkse meting Januari: Metingen voor alle 30 patiënten Februari: Deel van patiënten komen niet opdagen vanwege het slechte weer MCAR

12 Missing at Random (MAR) Kans op ontbrekende waarden hangt af van geobserveerde en niet van ongeobserveerde variabelen Gegeven de geobserveerde variabelen, ontbreken de gegevens random. X MAR M P (M Y, X) = P (M X) Y

13 Voorbeeld: Bloeddruk studie Verloop van bloeddruk over de tijd 30 patiënten, maandelijkse meting Januari: Metingen voor alle 30 patiënten Februari: Patienten die in januari geen hoge bloeddruk hadden komen niet opdagen MAR

14 Missing Not at Random (MNAR) Kans op missing data hangt af van de nietgeobserveerde variabelen. MNAR kan benaderd worden door MAR mechanisme door het verzamelen van extra informatie geassocieerd met de ontbrekende gegevens X MNAR M P (M Y, X) = P (M Y, X) Y

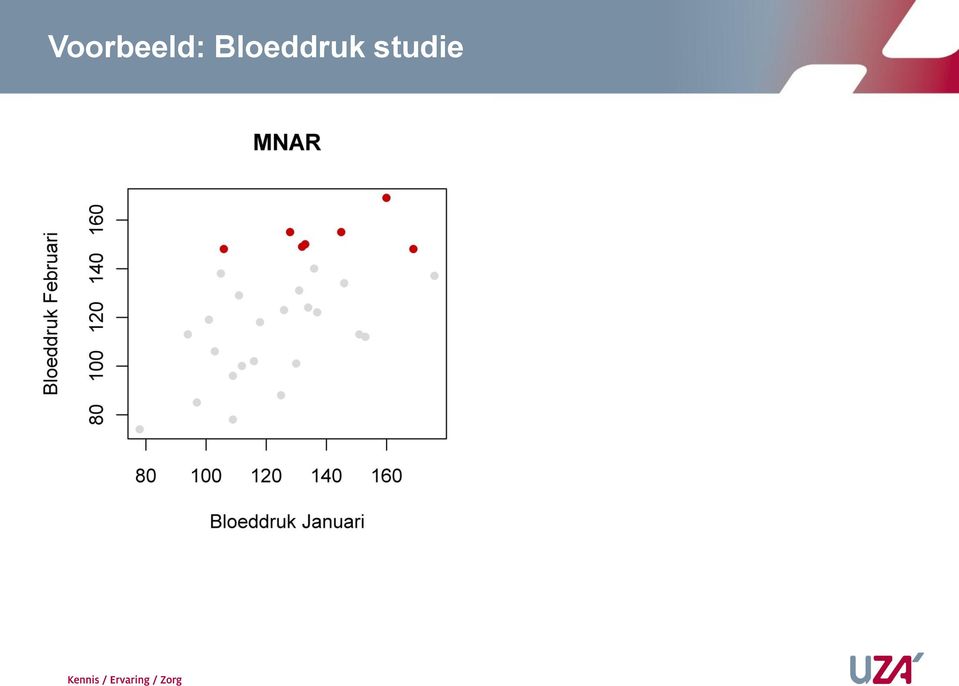
15 Voorbeeld: Bloeddruk studie Verloop van bloeddruk over de tijd 30 patiënten, maandelijkse meting Januari: Metingen voor alle 30 patiënten Februari: Enkel van patiënten met hoge bloeddruk worden de waarden genoteerd. MNAR

16 Voorbeeld: Bloeddruk studie Verloop van bloeddruk over de tijd 30 patiënten, maandelijkse meting Simulatie data van 30 patienten Gemiddelde BD: μ X = μ Y = 125 Standaard Deviatie: σ X = σ Y = 25 Correlatie ρ X,Y = 0.6


17 Voorbeeld: Bloeddruk studie Gemiddelde Januari Gemiddelde Februari SD Januari 23.0 SD Februari 24.7 Correlatie 0.57

18 Voorbeeld: Bloeddruk studie

19 Voorbeeld: Bloeddruk studie

20 Voorbeeld: Bloeddruk studie
21 Missing data in longitudinale studies Herhaalde metingen: Z 1, Z 2, Z p MCAR: Ontbreken van gegevens hangt niet af van scores in het verleden, heden en toekomst MAR: Ontbreken van gegevens hangt enkel af van het verleden (niet van heden en toekomst) MNAR: Ontbreken van gegevens hangt af van heden en/of toekomst
22 Missing data patroon Unit non response ID X1 X2 X3 X4 X5 X6 X7 X8 X Item non response ID X1 X2 X3 X4 X5 X6 X7 X8 X
23 Missing data patroon Univariaat Monotoon Willekeurig ID X1 X2 X3 X4 X5 X6 X7 X8 X ID X1 X2 X3 X4 X5 X6 X7 X8 X ID X1 X2 X3 X4 X5 X6 X7 X8 X
24 Identificatie missing data mechanisme en patroon Redenen van missingness bepaalt het missing data proces Verzamelen van gegevens over ontbrekende waarden is essentieel Niet alle statistische methoden geven unbiased resultaten onder alle missingness processen!
25 Overzicht Inleidend voorbeeld Missing data proces Missing data mechanisme Missing data patroon Methoden voor behandeling van missing data Vroeger Nu... Samenvatting en Conclusie
26 Statistische Methoden voor Missing Data Vroeger: Complete/Available case analysis Single imputation Mean/Median imputation Hot/Cold deck imputation Regression imputation Worst case analyse Last observation carried forward
27 Complete Case Analysis Enkel de patiënten zonder ontbrekende gegevens worden geïncludeerd in de analyse ( listwise deletion ) Default in veel statistische software pakketten (SPSS) Voordelen Eenvoudig Alle standaard technieken zijn toepasbaar Nadelen Verlies van power Biased testresultaten (tenzij MCAR)
28 Voorbeeld: Bloeddruk studie Complete Case
29 Voorbeeld: Bloeddruk studie Complete Case Volledig MCAR MAR MNAR Gem Februari (μ Y = 125) SD Februari (σ Y = 25) Correlatie (ρ X,Y = 0.6)
30 Simulatie-studie Schafer & Graham (2002) Genereer 1000 datasets met telkens 50 patienten volgens zelfde verdeling als bloeddruk studie Gemiddelde: μ X = μ Y = 125 Standaard Deviatie: σ X = σ Y = 25 Correlatie ρ X,Y = 0.6 Missingness: 70 % MCAR: willekeurig MAR: enkel hoge waarden voor X MNAR: enkel hoge waarden voor Y
31 Resultaat simulatie studie Complete case analyse Parameter schattingen: over 1000 simulaties Parameter MCAR MAR MNAR μ Y = σ Y = ρ X,Y = Schafer & Graham (2002)
32 Resultaat simulatie studie Complete case analyse Parameter schattingen: over 1000 simulaties Parameter MCAR MAR MNAR μ Y = σ Y = ρ X,Y = Betrouwbaarheid? 95% confidentieintervallen Coverage: Percentage van de 95%CI s die echte waarde bevatten Als data volledig: Coverage = 95%
33 Resultaat simulatie studie Complete case analyse Parameter schattingen Parameter MCAR MAR MNAR μ Y = σ Y = ρ X,Y = Coverage (Percentage van de 95%CIs die de echte waarde bevatten) Parameter MCAR MAR MNAR μ Y = σ Y = ρ X,Y = Schafer & Graham (2002)
34 Single Imputation De ontbrekende waarden worden vervangen door een goede schatting Resultaat: dataset zonder missing data Voorbeelden: Mean/Median imputation Hot/Cold deck imputation Last observation carried forward Worst case analyse Regression imputation
35 Single Imputation: Mean/Median imputation Ontbrekende gegevens worden vervangen door het gemiddelde of de mediaan van de geobserveerde data voor deze variabele Voordelen Alle patiënten worden geïncludeerd in de analyse Standaard technieken zijn toepasbaar op geïmputeerde data Nadelen Biased estimates (tenzij MCAR) Onderschatting van de variantie (ook bij MCAR!)
36 Voorbeeld: Bloeddruk studie Mean Imputation Volledig MCAR MAR MNAR Gem Februari (μ Y = 125) SD Februari (σ Y = 25) Correlatie (ρ X,Y = 0.6)
37 Resultaat simulatie studie Mean imputation Parameter schattingen Parameter MCAR MAR MNAR μ Y = σ Y = ρ X,Y = Coverage (Percentage van de 95%CIs die de echte waarde bevatten) Parameter MCAR MAR MNAR μ Y = σ Y = ρ X,Y = Schafer & Graham (2002)
38 Single Imputation: Hot deck imputation Vervang ontbrekende gegevens door waarde van andere (gelijkaardige) patiënt in de studie Voordelen Geen veronderstellingen over verdeling of model vereist Nadelen Bias als niet MCAR (geimputeerde data is enkel afkomstig van volledige patiënten) Vereist grote sample size, met weinig missing data Onderschatting van de variantie
 24.7 24.0 19.5 6.9 Correlatie (ρ X,Y = 0.6) 0.57 0.37 0.")
39 Voorbeeld: Bloeddruk studie Hot Deck imputation Volledig MCAR MAR MNAR Gem Februari (μ Y = 125) SD Februari (σ Y = 25) Correlatie (ρ X,Y = 0.6)
40 Resultaat simulatie studie Hot deck imputation Parameter schattingen Parameter MCAR MAR MNAR μ Y = σ Y = ρ X,Y = Coverage (Percentage van de 95%CIs die de echte waarde bevatten) Parameter MCAR MAR MNAR μ Y = σ Y = ρ X,Y = Schafer & Graham (2002)
41 Single Imputation: Regression imputation (Lineair) regressiemodel wordt gefit voor geobserveerde data en gebruikt om een voorspelling te doen voor ontbrekende gegevens Voordelen Goede predictie van de ontbrekende waarden als regressiemodel sterk is. Nadelen Onderschatting van de variantie Overschatting van relatie tussen de variabelen
42 Voorbeeld: Bloeddruk studie Regression Imputation Volledig MCAR MAR MNAR Gem Februari (μ Y = 125) SD Februari (σ Y = 25) Correlatie (ρ X,Y = 0.6)
43 Resultaat simulatie studie Regression Imputation Parameter schattingen Parameter MCAR MAR MNAR μ Y = σ Y = ρ X,Y = Coverage (Percentage van de 95%CIs die de echte waarde bevatten) Parameter MCAR MAR MNAR μ Y = σ Y = ρ X,Y = Schafer & Graham (2002)
44 Single Imputation: Stochastic regression imputation De ontbrekende gegevens worden vervangen door voorspelde waarden uit het regressiemodel + error term Voordelen Onzekerheid op de voorspelde waarden wordt voor een deel in rekening gebracht Betere schatting van de variantie Nadelen Sterke afhankelijkheid van het gekozen model
45 Voorbeeld: Bloeddruk studie Stochastic Regression Volledig MCAR MAR MNAR Gem Februari (μ Y = 125) SD Februari (σ Y = 25) Correlatie (ρ X,Y = 0.6)
46 Resultaat simulatie studie Stochastic regression Parameter schattingen Parameter MCAR MAR MNAR μ Y = σ Y = ρ X,Y = Coverage (Percentage van de 95% CIs die de echte waarde bevatten) Parameter MCAR MAR MNAR μ Y = σ Y = ρ X,Y = Schafer & Graham (2002)
47 Single Imputation: Worst case analysis In geval van ontbrekende outcome Vervang ontbrekende waarde door slechtste scenario (bv overlijden voor binaire survival outcome) Doel: aantonen dat censoring geen invloed heeft op de studieresultaten
48 Single Imputation: Last Observation Carried Forward In longitudinale studies Laatste geobserveerde waarde wordt geïmputeerd voor alle daaropvolgende ontbrekende waarden van deze patiënt

49 Single Imputation: Last Observation Carried Forward In longitudinale studies Laatste geobserveerde waarde wordt geïmputeerd voor alle daaropvolgende ontbrekende waarden van deze patiënt
50 Single Imputation Summary Voordelen Eenvoudig Analyse met standaard statistische technieken Nadelen Imputatie kan bias veroorzaken onder alle missing data mechanismen Onderschatting van de variantie
51 Statistische Methoden voor Missing Data Vroeger: Complete/Available case analysis Single imputation Mean/Median imputation Hot/Cold deck imputation Last observation carried forward Worst case analyse Regression imputation MCAR
52 Statistische Methoden voor Missing Data Vroeger: Nu: Complete/Available case analysis Single imputation Mean/Median imputation Hot/Cold deck imputation Last observation carried forward Worst case analyse Regression imputation Multiple imputation Likelihood based methode Selectie modellen Pattern mixture modellen MCAR MAR MNAR
53 Multiple Imputation (Rubin, 1987) Genereer m nieuwe datasets met imputatie van de ontbrekende waarden Oorspronkelijke variabiliteit blijft behouden + Onzekerheid schatting ontbrekende waarden
54 Multiple Imputation (Rubin, 1987) Genereer m nieuwe datasets met imputatie van de ontbrekende waarden Oorspronkelijke variabiliteit blijft behouden + Onzekerheid schatting ontbrekende waarden Imputed Data 1 Originele data Imputed Data 2 Imputed Data 3
55 Multiple Imputation (Rubin, 1987) Genereer m nieuwe datasets met imputatie van de ontbrekende waarden Oorspronkelijke variabiliteit blijft behouden + Onzekerheid schatting ontbrekende waarden Imputed Data 1 Analyse 1 Originele data Imputed Data 2 Analyse 2 Imputed Data 3 Analyse 3
56 Multiple Imputation (Rubin, 1987) Genereer m nieuwe datasets met imputatie van de ontbrekende waarden Oorspronkelijke variabiliteit blijft behouden + Onzekerheid schatting ontbrekende waarden Imputed Data 1 Analyse 1 Originele data Imputed Data 2 Analyse 2 Totaal Resultaat Imputed Data 3 Analyse 3
57 Multiple Imputation (Rubin, 1987) Genereer m nieuwe datasets met imputatie van de ontbrekende waarden Oorspronkelijke variabiliteit blijft behouden + Onzekerheid schatting ontbrekende waarden Imputed Data 1 Analyse 1 Originele data Stap 1 Imputed Data 2 Analyse 2 Totaal Resultaat Imputed Data 3 Analyse 3
58 MI Stap 1: Imputation Eenvoudige missingness patronen/ Monotone missingness Parametrisch: Regressie model Cfr. Stochastic regression imputation Niet-parametrisch: Propensity scores Propensity score berekend met logistisch regressiemodel voor kans op missing Verdeel data in groepen op basis van propensity scores Trek random sample uit groep voor ontbrekende waarden
59 MI Stap 1: Imputation Eenvoudige missingness patronen/ Monotone missingness Parametrisch: Regressie model Cfr. Stochastic regression imputation Niet-parametrisch: Propensity scores Propensity score berekend met logistisch regressiemodel voor kans op missing Verdeel data in groepen op basis van propensity scores Trek random sample uit groep voor ontbrekende waarden Selectie van predictoren Relevante parameters voor onderzoeksvraag Parameters die gerelateerd zijn aan het optreden van missing
60 MI Stap 1: Imputation Willekeurige missingness: MCMC methode Step 0: Schat gemiddelde en covariantiematrix (bv met complete case analysis) Imputation step: simuleer data op basis van geschat gemiddelde en covariantiematrix Posterior step: Schat gemiddelde en covariantiematrix op basis van (geimputeerde) data Herhaal tot convergentie
61 MI Stap 1: Imputation Hoeveel imputaties (m) nodig? 3 à 10 is voldoende Efficientie = (1+λ/m) -1 Rubin (1987) Waarbij λ = percentage missingness Bv 25% missing, m = 5 efficientie = 95%
62 Multiple Imputation (Rubin, 1987) Genereer m nieuwe datasets met imputatie van de ontbrekende waarden Oorspronkelijke variabiliteit blijft behouden + Onzekerheid schatting ontbrekende waarden Imputed Data 1 Analyse 1 Originele data Stap 1 Imputed Stap 2 Data 2 Analyse 2 Totaal Resultaat Imputed Data 3 Analyse 3
63 MI Stap 2: Analyse Voer standaard statistische analyse uit op elke geïmputeerde dataset Lineaire Regressie Logistische Regressie Cox Proportional Hazards Model Mixed Effects Model Parameter schattingen: Q (1), Q (2),, Q (m) Varianties: U (1), U (2),, U (m)
64 Multiple Imputation (Rubin, 1987) Genereer m nieuwe datasets met imputatie van de ontbrekende waarden Oorspronkelijke variabiliteit blijft behouden + Onzekerheid schatting ontbrekende waarden Imputed Data 1 Analyse 1 Originele data Stap 1 Imputed Stap 2 Analyse Stap 3 Data 2 2 Totaal Resultaat Imputed Data 3 Analyse 3
65 MI Stap 3: Pool resultaten Combineer parameter schattingen tot globale parameter schatting: Variabiliteit: Gemiddelde within-imputation variabiliteit Between-imputation variabiliteit Totale variabiliteit
66 Multiple Imputation Voordelen: Intuitief Unbiased parameter schattingen onder MAR en MCAR Rekening houdend met natuurlijke variabiliteit + variabiliteit door onzekerheid van schattingen Gebruiksvriendelijke software R: library mice SAS: PROC MI en PROC MIANALYZE SPSS: Add-on Missing Values STATA: mi impute, ICE
67 Bloeddruk studie: Multiple Imputation ID Bloeddruk_visit1 Bloeddruk_visit library(mice)
68 Bloeddruk studie: Multiple Imputation ID Bloeddruk_visit1 Bloeddruk_visit library(mice) imp <- mice(data, method="norm", m=10) fitmean <- with(imp, mean(bdfeb)) fitreg <- with(imp, lm(bdfeb~bdjan)) est <- pool(fitreg)
69 Bloeddruk studie: Multiple Imputation ID Bloeddruk_visit1 Bloeddruk_visit PROC MI DATA=BDdata OUT = impdata NIMPUTE = 10; VAR BDjan BDfeb; MONOTONE; RUN; PROC MEANS DATA=impdata; VAR BDjan BDFeb; BY _imputation_; RUN; PROC REG DATA=impdata OUTEST=outreg COVOUT; MODEL BDFeb = BDJan; BY _imputation_; RUN; PROC MIANALYZE DATA=outreg; MODELEFFECTS Intercept BDJan; RUN;
70 Bloeddruk studie: Multiple Imputation ID Bloeddruk_visit1 Bloeddruk_visit m = 10
71 Bloeddruk studie: Multiple Imputation Imp Gem Var Gemiddelde? M = Variantie? Within Imputatie U = Between Imputatie B = 32.3 Totale Variantie T = U + B*(1+1/10) = Standaard Deviatie? SD = 25.9
72 Bloeddruk studie: Multiple Imputation Lineaire regressie Imp Beta SE Regressie Coefficiënt? β = 0.29 Standard error? 0.23
73 Resultaat simulatie studie Multiple Imputation Parameter schattingen Parameter MCAR MAR MNAR μ Y = σ Y = ρ X,Y = Coverage (Percentage van de 95% CIs die de echte waarde bevatten) Parameter MCAR MAR MNAR μ Y = σ Y = ρ X,Y = Schafer & Graham (2002)
74 Likelihood based methoden Voor grote datasets kan MI zeer traag en computerintensief worden Alternatief: Likelihood based methoden Specifieer model voor outcome en missing proces MAR/MCAR: Parameters in outcome model zijn niet betrokken in missingness proces en missingness model hoeft dus niet gespecifieerd te worden EM algoritme: E-step: Schatting log-likelihood op basis van gemiddelde en covariantie matrix M-step: Maximaliseer log-likelihood Herhaal stap E en M tot convergentie
75 Likelihood based methoden Software SAS: PROC MIXED, PROC NLMIXED, PROC MI R: library lme4 SPSS: vanaf versie 12 mixed models Stata: xtmixed
76 Resultaat simulatie studie Maximum Likelihood Parameter schattingen Parameter MCAR MAR MNAR μ Y = σ Y = ρ X,Y = Coverage (Percentage van de 95% CIs die de echte waarde bevatten) Parameter MCAR MAR MNAR μ Y = σ Y = ρ X,Y = Schafer & Graham (2002)
77 Wat bij MNAR? Modelleren van gezamenlijke verdeling Selectie modellen (Diggle & Kenward, 1994) f(y,x,m) = f(y,x) f(m Y,X) Pattern-mixture modellen (Little, 1993; Hedeker & Gibbons,1997) f(y,x,m) = f(y,x M) f(m)
78 Samenvatting en Conclusie Identificatie missing data proces MCAR MAR MNAR Verzamel gegevens over missingness Modelleer het proces Bij niet MCAR Gebruik Multiple imputation of likelihood based methode! Sensitiviteitsanalyse Voorkomen is beter dan genezen!
79 Referenties Haukoos, J.S., Newgard, C.D. (2007). Advanced statistics: missing data in clinical research part 1: an introduction and conceptual framework. Academic Emergency Medicine, 14, Newgard, C.D., Haukoos, J.S. (2007). Advanced statistics: Missing data in clinical research part 2: Multiple imputation. Academic Emergency Medecine, 14, Schafer, J.L., Graham, J.W. (2002) Missing data: Our view of the state of the art. Psychological methods, 7 (2), Rubin, D.B. (1987). Multiple imputation for nonresponse in surveys. New York: Wiley Rubin, D.B. (1996). Multiple imputation after 18+ years. Journal of the American Statistical Association, 91, Little, R.J.A. (1993). Pattern mixture models for multivariate incomplete data. Journal of the American Statistical Association. 88: Diggle, P.J., Kenward, M.G. (1994). Informative dropout in longitudinal data analysis (with discussion). Applied Statistics. 43: 49-93
MISSING DATA van gatenkaas naar valide uitkomsten
 MISSING DATA van gatenkaas naar valide uitkomsten Sander M.J. van Kuijk Afdeling Klinische Epidemiologie en Medical Technology Assessment sander.van.kuijk@mumc.nl Inhoud Masterclass Theorie over missing
MISSING DATA van gatenkaas naar valide uitkomsten Sander M.J. van Kuijk Afdeling Klinische Epidemiologie en Medical Technology Assessment sander.van.kuijk@mumc.nl Inhoud Masterclass Theorie over missing
Missing Data: Multipele Imputatie
 Missing Data: Multipele Imputatie Mark Huisman Rijksuniversiteit Groningen Statistiek in de Praktijk 30 maart 2006 Missing Data: Multipele Imputatie 1 Inhoud 1. Omgaan met ontbrekende scores: Imputeren
Missing Data: Multipele Imputatie Mark Huisman Rijksuniversiteit Groningen Statistiek in de Praktijk 30 maart 2006 Missing Data: Multipele Imputatie 1 Inhoud 1. Omgaan met ontbrekende scores: Imputeren
Samenvatting Nederlands
 Samenvatting Nederlands 178 Samenvatting Mis het niet! Incomplete data kan waardevolle informatie bevatten In epidemiologisch onderzoek wordt veel gebruik gemaakt van vragenlijsten om data te verzamelen.
Samenvatting Nederlands 178 Samenvatting Mis het niet! Incomplete data kan waardevolle informatie bevatten In epidemiologisch onderzoek wordt veel gebruik gemaakt van vragenlijsten om data te verzamelen.
Adviseren over onderzoeksmethoden: Ontbrekende waarnemingen, uitbijters en nonrespons
 Adviseren over onderzoeksmethoden:, uitbijters en nonrespons Statistiek versus Onderzoeksmethodologie 19 november 2004 : Missing Values Missing Cases Nonrespons: Unit nonrespons Item nonrespons Uitbijters
Adviseren over onderzoeksmethoden:, uitbijters en nonrespons Statistiek versus Onderzoeksmethodologie 19 november 2004 : Missing Values Missing Cases Nonrespons: Unit nonrespons Item nonrespons Uitbijters
Het analyseren van onvolledige longitudinale gegevens : wat is de invloed van gegevens die we niet hebben?
 Het analyseren van onvolledige longitudinale gegevens : wat is de invloed van gegevens die we niet hebben? 14 november 2007 Research Club, Universitair Ziekenhuis Antwerpen Caroline Beunckens caroline.beunckens@uhasselt.be
Het analyseren van onvolledige longitudinale gegevens : wat is de invloed van gegevens die we niet hebben? 14 november 2007 Research Club, Universitair Ziekenhuis Antwerpen Caroline Beunckens caroline.beunckens@uhasselt.be
Bij medisch-wetenschappelijk onderzoek ontbreken
 Stand van zaken Methodologie van onderzoek Rekenen met ontbrekende gegevens Ralph C.A. Rippe, Martin den Heijer en Saskia le Cessie Ontbrekende gegevens in medisch-wetenschappelijk onderzoek zijn soms
Stand van zaken Methodologie van onderzoek Rekenen met ontbrekende gegevens Ralph C.A. Rippe, Martin den Heijer en Saskia le Cessie Ontbrekende gegevens in medisch-wetenschappelijk onderzoek zijn soms
MULTIPELE IMPUTATIE IN VOGELVLUCHT
 MULTIPELE IMPUTATIE IN VOGELVLUCHT Stef van Buuren We hebben het er liever niet over, maar allemaal worden we geplaagd door ontbrekende gegevens. Het liefst moffelen we problemen veroorzaakt door ontbrekende
MULTIPELE IMPUTATIE IN VOGELVLUCHT Stef van Buuren We hebben het er liever niet over, maar allemaal worden we geplaagd door ontbrekende gegevens. Het liefst moffelen we problemen veroorzaakt door ontbrekende
HOOFDSTUK VII REGRESSIE ANALYSE
 HOOFDSTUK VII REGRESSIE ANALYSE 1 DOEL VAN REGRESSIE ANALYSE De relatie te bestuderen tussen een response variabele en een verzameling verklarende variabelen 1. LINEAIRE REGRESSIE Veronderstel dat gegevens
HOOFDSTUK VII REGRESSIE ANALYSE 1 DOEL VAN REGRESSIE ANALYSE De relatie te bestuderen tussen een response variabele en een verzameling verklarende variabelen 1. LINEAIRE REGRESSIE Veronderstel dat gegevens
9. Multipele imputatie van ontbrekende scores
 9. Multipele imputatie van ontbrekende scores M. Huisman Samenvatting Multipele imputatie is een techniek die al een aantal jaren bekend is, maar pas de laatste jaren voor een breder publiek van toegepaste
9. Multipele imputatie van ontbrekende scores M. Huisman Samenvatting Multipele imputatie is een techniek die al een aantal jaren bekend is, maar pas de laatste jaren voor een breder publiek van toegepaste
Masterclass: advanced statistics. Bianca de Greef Sander van Kuijk Afdeling KEMTA
 Masterclass: advanced statistics Bianca de Greef Sander van Kuijk Afdeling KEMTA Inhoud Masterclass Deel 1 (theorie): Achtergrond regressie Deel 2 (voorbeeld): Keuzes Output Model Model Dependent variable
Masterclass: advanced statistics Bianca de Greef Sander van Kuijk Afdeling KEMTA Inhoud Masterclass Deel 1 (theorie): Achtergrond regressie Deel 2 (voorbeeld): Keuzes Output Model Model Dependent variable
College 2 Enkelvoudige Lineaire Regressie
 College Enkelvoudige Lineaire Regressie - Leary: Hoofdstuk 7 tot p. 170 (Advanced Correlational Strategies) - MM&C: Hoofdstuk 10 (Inference for Regression) - Aanvullende tekst 3 Jolien Pas ECO 011-01 Correlatie:
College Enkelvoudige Lineaire Regressie - Leary: Hoofdstuk 7 tot p. 170 (Advanced Correlational Strategies) - MM&C: Hoofdstuk 10 (Inference for Regression) - Aanvullende tekst 3 Jolien Pas ECO 011-01 Correlatie:
9. Lineaire Regressie en Correlatie
 9. Lineaire Regressie en Correlatie Lineaire verbanden In dit hoofdstuk worden methoden gepresenteerd waarmee je kwantitatieve respons variabelen (afhankelijk) en verklarende variabelen (onafhankelijk)
9. Lineaire Regressie en Correlatie Lineaire verbanden In dit hoofdstuk worden methoden gepresenteerd waarmee je kwantitatieve respons variabelen (afhankelijk) en verklarende variabelen (onafhankelijk)
Inhoud. Data. Analyse van tijd tot event data: van Edward Kaplan & Paul Meier tot David Cox
 van tijd tot event data: van Edward Kaplan & Paul Meier tot David Cox Bram Ramaekers Bianca de Greef KEMTA Masterclass Inhoud Data Kaplan-Meier curve Hazard rate Log-rank test Hazard ratio Cox regressie
van tijd tot event data: van Edward Kaplan & Paul Meier tot David Cox Bram Ramaekers Bianca de Greef KEMTA Masterclass Inhoud Data Kaplan-Meier curve Hazard rate Log-rank test Hazard ratio Cox regressie
Survival Analyse. Help! Statistiek! Survival Analyse: Overzicht. Voorbeeld: Whiplash onderzoek. Voorbeeld: Intensive Care Unit data
 Help! Statistiek! Doel: Informeren over statistiek in klinisch onderzoek. Tijd: Doorlopende serie laagdrempelige lezingen, voor iedereen vrij toegankelijk. Derde woensdag in de maand, -3 uur 9 september:
Help! Statistiek! Doel: Informeren over statistiek in klinisch onderzoek. Tijd: Doorlopende serie laagdrempelige lezingen, voor iedereen vrij toegankelijk. Derde woensdag in de maand, -3 uur 9 september:
Tentamen Inleiding Intelligente Data Analyse Datum: Tijd: , BBL 420 Dit is geen open boek tentamen.
 Tentamen Inleiding Intelligente Data Analyse Datum: 19-12-2002 Tijd: 9.00-12.00, BBL 420 Dit is geen open boek tentamen. Algemene aanwijzingen 1. U mag ten hoogste één A4 met aantekeningen raadplegen.
Tentamen Inleiding Intelligente Data Analyse Datum: 19-12-2002 Tijd: 9.00-12.00, BBL 420 Dit is geen open boek tentamen. Algemene aanwijzingen 1. U mag ten hoogste één A4 met aantekeningen raadplegen.
Classification - Prediction
 Classification - Prediction Tot hiertoe: vooral classification Naive Bayes k-nearest Neighbours... Op basis van predictor variabelen X 1, X 2,..., X p klasse Y (= discreet) proberen te bepalen. Training
Classification - Prediction Tot hiertoe: vooral classification Naive Bayes k-nearest Neighbours... Op basis van predictor variabelen X 1, X 2,..., X p klasse Y (= discreet) proberen te bepalen. Training
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor T (2S070) op vrijdag 8 oktober 1999, uur De u
 op vrijdag 8 oktober 1999, uur De u") TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor T (2S070) op vrijdag 8 oktober 1999, 14.00-17.00 uur De uitwerkingen van de opgaven dienen duidelijk geformuleerd
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor T (2S070) op vrijdag 8 oktober 1999, 14.00-17.00 uur De uitwerkingen van de opgaven dienen duidelijk geformuleerd
Examen Statistische Modellen en Data-analyse. Derde Bachelor Wiskunde. 14 januari 2008
 Examen Statistische Modellen en Data-analyse Derde Bachelor Wiskunde 14 januari 2008 Vraag 1 1. Stel dat ɛ N 3 (0, σ 2 I 3 ) en dat Y 0 N(0, σ 2 0) onafhankelijk is van ɛ = (ɛ 1, ɛ 2, ɛ 3 ). Definieer
Examen Statistische Modellen en Data-analyse Derde Bachelor Wiskunde 14 januari 2008 Vraag 1 1. Stel dat ɛ N 3 (0, σ 2 I 3 ) en dat Y 0 N(0, σ 2 0) onafhankelijk is van ɛ = (ɛ 1, ɛ 2, ɛ 3 ). Definieer
Toets deel 2 Data-analyse en retrieval Vrijdag 1 Juli 2016:
 Toets deel 2 Data-analyse en retrieval Vrijdag 1 Juli 2016: 11.00-13.00 Algemene aanwijzingen 1. Het is toegestaan een aan beide zijden beschreven A4 met aantekeningen te raadplegen. 2. Het is toegestaan
Toets deel 2 Data-analyse en retrieval Vrijdag 1 Juli 2016: 11.00-13.00 Algemene aanwijzingen 1. Het is toegestaan een aan beide zijden beschreven A4 met aantekeningen te raadplegen. 2. Het is toegestaan
EEN COMBINATIE VAN MULTIPLE IMPUTATION (MI) EN LATENTEKLASSENANALYSE (LC) OM TE CORRIGEREN VOOR MEETFOUT
 EN LATENTEKLASSENANALYSE (LC) OM TE CORRIGEREN VOOR MEETFOUT") EEN COMBINATIE VAN MULTIPLE IMPUTATION (MI) EN LATENTEKLASSENANALYSE (LC) OM TE CORRIGEREN VOOR MEETFOUT LAURA BOESCHOTEN (UVT & CBS) DANIEL OBERSKI (UU) TON DE WAAL (CBS & UVT) JEROEN VERMUNT (UVT) Data
EEN COMBINATIE VAN MULTIPLE IMPUTATION (MI) EN LATENTEKLASSENANALYSE (LC) OM TE CORRIGEREN VOOR MEETFOUT LAURA BOESCHOTEN (UVT & CBS) DANIEL OBERSKI (UU) TON DE WAAL (CBS & UVT) JEROEN VERMUNT (UVT) Data
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica. Tentamen Statistiek 2 voor TeMa (2S195) op dinsdag , uur.
 op dinsdag , uur.") TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor TeMa (S95) op dinsdag 3-03-00, 9- uur. Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor TeMa (S95) op dinsdag 3-03-00, 9- uur. Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en
mlw stroom 2.2 Biostatistiek en Epidemiologie College 9: Herhaalde metingen (2) Syllabus Afhankelijke Data Hoofdstuk 4, 5.1, 5.2
 Syllabus Afhankelijke Data Hoofdstuk 4, 5.1, 5.2") mlw stroom 2.2 Biostatistiek en Epidemiologie College 9: Herhaalde metingen (2) Syllabus Afhankelijke Data Hoofdstuk 4, 5.1, 5.2 Bjorn Winkens Methodologie en Statistiek Universiteit Maastricht 21 maart
mlw stroom 2.2 Biostatistiek en Epidemiologie College 9: Herhaalde metingen (2) Syllabus Afhankelijke Data Hoofdstuk 4, 5.1, 5.2 Bjorn Winkens Methodologie en Statistiek Universiteit Maastricht 21 maart
Oplossingen hoofdstuk XI
 Oplossingen hoofdstuk XI. Hierbij vind je de resultaten van het onderzoek naar de relatie tussen een leestest en een schoolrapport voor lezen. Deze gegevens hebben betrekking op een regressieanalyse bij
Oplossingen hoofdstuk XI. Hierbij vind je de resultaten van het onderzoek naar de relatie tussen een leestest en een schoolrapport voor lezen. Deze gegevens hebben betrekking op een regressieanalyse bij
variantie: achtergronden en berekening
 variantie: achtergronden en berekening Hugo Quené opleiding Taalwetenschap Universiteit Utrecht 8 sept 1995 aangepast 8 mei 007 1 berekening variantie Als je de variantie met de hand moet uitrekenen, is
variantie: achtergronden en berekening Hugo Quené opleiding Taalwetenschap Universiteit Utrecht 8 sept 1995 aangepast 8 mei 007 1 berekening variantie Als je de variantie met de hand moet uitrekenen, is
Herkansing Inleiding Intelligente Data Analyse Datum: Tijd: , BBL 508 Dit is geen open boek tentamen.
 Herkansing Inleiding Intelligente Data Analyse Datum: 3-3-2003 Tijd: 14.00-17.00, BBL 508 Dit is geen open boek tentamen. Algemene aanwijzingen 1. U mag ten hoogste één A4 met aantekeningen raadplegen.
Herkansing Inleiding Intelligente Data Analyse Datum: 3-3-2003 Tijd: 14.00-17.00, BBL 508 Dit is geen open boek tentamen. Algemene aanwijzingen 1. U mag ten hoogste één A4 met aantekeningen raadplegen.
11. Multipele Regressie en Correlatie
 11. Multipele Regressie en Correlatie Meervoudig regressie model Nu gaan we kijken naar een relatie tussen een responsvariabele en meerdere verklarende variabelen. Een bivariate regressielijn ziet er in
11. Multipele Regressie en Correlatie Meervoudig regressie model Nu gaan we kijken naar een relatie tussen een responsvariabele en meerdere verklarende variabelen. Een bivariate regressielijn ziet er in
SPSS. Statistiek : SPSS
 SPSS - hoofdstuk 1 : 1.4. fase 4 : verrichten van metingen en / of verzamelen van gegevens Gegevens gevonden bij een onderzoek worden systematisch weergegeven in een datamatrix bij SPSS De datamatrix Gebruik
SPSS - hoofdstuk 1 : 1.4. fase 4 : verrichten van metingen en / of verzamelen van gegevens Gegevens gevonden bij een onderzoek worden systematisch weergegeven in een datamatrix bij SPSS De datamatrix Gebruik
College 3 Interne consistentie; Beschrijvend onderzoek
 College 3 Interne consistentie; Beschrijvend onderzoek Inleiding M&T 2012 2013 Hemmo Smit Overzicht van dit college Kwaliteit van een meetinstrument (herhaling) Interne consistentie: Cronbach s alpha Voorbeeld:
College 3 Interne consistentie; Beschrijvend onderzoek Inleiding M&T 2012 2013 Hemmo Smit Overzicht van dit college Kwaliteit van een meetinstrument (herhaling) Interne consistentie: Cronbach s alpha Voorbeeld:
EIND TOETS TOEGEPASTE BIOSTATISTIEK I. 30 januari 2009
 EIND TOETS TOEGEPASTE BIOSTATISTIEK I 30 januari 2009 - Dit tentamen bestaat uit vier opgaven onderverdeeld in totaal 2 subvragen. - Geef bij het beantwoorden van de vragen een zo volledig mogelijk antwoord.
EIND TOETS TOEGEPASTE BIOSTATISTIEK I 30 januari 2009 - Dit tentamen bestaat uit vier opgaven onderverdeeld in totaal 2 subvragen. - Geef bij het beantwoorden van de vragen een zo volledig mogelijk antwoord.
Hoofdstuk 8: Multipele regressie Vragen
 Hoofdstuk 8: Multipele regressie Vragen 1. Wat is het verschil tussen de pearson correlatie en de multipele correlatie R? 2. Voor twee modellen berekenen we de adjusted R2 : Model 1 heeft een adjusted
Hoofdstuk 8: Multipele regressie Vragen 1. Wat is het verschil tussen de pearson correlatie en de multipele correlatie R? 2. Voor twee modellen berekenen we de adjusted R2 : Model 1 heeft een adjusted
mlw stroom 2.1: Statistisch modelleren
 mlw stroom 2.1: Statistisch modelleren College 5: Regressie en correlatie (2) Rosner 11.5-11.8 Arnold Kester Capaciteitsgroep Methodologie en Statistiek Universiteit Maastricht Postbus 616, 6200 MD Maastricht
mlw stroom 2.1: Statistisch modelleren College 5: Regressie en correlatie (2) Rosner 11.5-11.8 Arnold Kester Capaciteitsgroep Methodologie en Statistiek Universiteit Maastricht Postbus 616, 6200 MD Maastricht
Principe Maken van een Monte Carlo data-set populatie-parameters en standaarddeviaties standaarddeviatie van de bepaling statistische verdeling
 Monte Carlo simulatie In MW\Pharm versie 3.30 is een Monte Carlo simulatie-module toegevoegd. Met behulp van deze Monte Carlo procedure kan onder meer de betrouwbaarheid van de berekeningen van KinPop
Monte Carlo simulatie In MW\Pharm versie 3.30 is een Monte Carlo simulatie-module toegevoegd. Met behulp van deze Monte Carlo procedure kan onder meer de betrouwbaarheid van de berekeningen van KinPop
Disclosure Belangen Spreker
 1 Geen (potentiële) belangenverstengeling Disclosure Belangen Spreker Voor bijeenkomst mogelijk relevante relaties: Sponsoring of onderzoeksgeld - Honorarium of andere (financiële ) vergoedingen Aandeelhouder
1 Geen (potentiële) belangenverstengeling Disclosure Belangen Spreker Voor bijeenkomst mogelijk relevante relaties: Sponsoring of onderzoeksgeld - Honorarium of andere (financiële ) vergoedingen Aandeelhouder
Een gegeneraliseerde aanpak voor automatische foutlocalisatie. Sander Scholtus
 Een gegeneraliseerde aanpak voor automatische foutlocalisatie Sander Scholtus (s.scholtus@cbs.nl) Automatische controle en correctie Doel: geautomatiseerd verbeteren fouten in microdata Twee stappen: detecteren
Een gegeneraliseerde aanpak voor automatische foutlocalisatie Sander Scholtus (s.scholtus@cbs.nl) Automatische controle en correctie Doel: geautomatiseerd verbeteren fouten in microdata Twee stappen: detecteren
Zowel correlatie als regressie meten statistische samenhang Correlatie: geen oorzakelijk verband verondersteld: X Y
 1 Regressie analyse Zowel correlatie als regressie meten statistische samenhang Correlatie: geen oorzakelijk verband verondersteld: X Y Regressie: wel een oorzakelijk verband verondersteld: X Y Voorbeeld
1 Regressie analyse Zowel correlatie als regressie meten statistische samenhang Correlatie: geen oorzakelijk verband verondersteld: X Y Regressie: wel een oorzakelijk verband verondersteld: X Y Voorbeeld
Toegepaste data-analyse: oefensessie 2
 Toegepaste data-analyse: oefensessie 2 Depressie 1. Beschrijf de clustering van de dataset en geef aan op welk niveau de verschillende variabelen behoren Je moet weten hoe de data geclusterd zijn om uit
Toegepaste data-analyse: oefensessie 2 Depressie 1. Beschrijf de clustering van de dataset en geef aan op welk niveau de verschillende variabelen behoren Je moet weten hoe de data geclusterd zijn om uit
Help! Statistiek! Groeicurven. Doel van de analyse van de groeicurven. Vergelijken van groeicurven in groepen A en B. Voorbeeld
 Help! Statistiek! Groeicurven Doorlopende serie laagdrempelige lezingen, voor iedereen vrij toegankelijk. Doel: Informeren over statistiek in klinisch onderzoek. : lengte, gewicht, BMI, concentratie van
Help! Statistiek! Groeicurven Doorlopende serie laagdrempelige lezingen, voor iedereen vrij toegankelijk. Doel: Informeren over statistiek in klinisch onderzoek. : lengte, gewicht, BMI, concentratie van
College 7. Regressie-analyse en Variantie verklaren. Inleiding M&T Hemmo Smit
 College 7 Regressie-analyse en Variantie verklaren Inleiding M&T 2012 2013 Hemmo Smit Neem mee naar tentamen Geslepen potlood + gum Collegekaart (alternatief: rijbewijs, ID-kaart, paspoort) (Grafische)
College 7 Regressie-analyse en Variantie verklaren Inleiding M&T 2012 2013 Hemmo Smit Neem mee naar tentamen Geslepen potlood + gum Collegekaart (alternatief: rijbewijs, ID-kaart, paspoort) (Grafische)
Cursus Statistiek Parametrische en non-parametrische testen. Fellowonderwijs Intensive Care UMC St Radboud
 Cursus Statistiek Parametrische en non-parametrische testen Fellowonderwijs Intensive Care UMC St Radboud Vergelijken gemiddelde met hypothetische waarde 13 24 19 18 11 22 10 17 14 31 21 18 22 12 18 11
Cursus Statistiek Parametrische en non-parametrische testen Fellowonderwijs Intensive Care UMC St Radboud Vergelijken gemiddelde met hypothetische waarde 13 24 19 18 11 22 10 17 14 31 21 18 22 12 18 11
Tentamen Biostatistiek 1 voor BMT (2DM40) woensdag 2 november 2011, uur
 woensdag 2 november 2011, uur") Faculteit der Wiskunde en Informatica Tentamen Biostatistiek 1 voor BMT (2DM40) woensdag 2 november 2011, 9.00-12.00 uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en van een onbeschreven
Faculteit der Wiskunde en Informatica Tentamen Biostatistiek 1 voor BMT (2DM40) woensdag 2 november 2011, 9.00-12.00 uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en van een onbeschreven
1. Reductie van error variantie en dus verhogen van power op F-test
 Werkboek 2013-2014 ANCOVA Covariantie analyse bestaat uit regressieanalyse en variantieanalyse. Er wordt een afhankelijke variabele (intervalniveau) voorspeld uit meerdere onafhankelijke variabelen. De
Werkboek 2013-2014 ANCOVA Covariantie analyse bestaat uit regressieanalyse en variantieanalyse. Er wordt een afhankelijke variabele (intervalniveau) voorspeld uit meerdere onafhankelijke variabelen. De
Toetsende Statistiek, Week 2. Van Steekproef naar Populatie: De Steekproevenverdeling
 Toetsende Statistiek, Week 2. Van Steekproef naar Populatie: De Steekproevenverdeling Moore, McCabe & Craig: 3.3 Toward Statistical Inference From Probability to Inference 5.1 Sampling Distributions for
Toetsende Statistiek, Week 2. Van Steekproef naar Populatie: De Steekproevenverdeling Moore, McCabe & Craig: 3.3 Toward Statistical Inference From Probability to Inference 5.1 Sampling Distributions for
werkcollege 8 correlatie, regressie - D&P5: Summarizing Bivariate Data relatie tussen variabelen scattergram cursus Statistiek
 cursus 23 mei 2012 werkcollege 8 correlatie, regressie - D&P5: Summarizing Bivariate Data relatie tussen variabelen onderzoek streeft naar inzicht in relatie tussen variabelen bv. tussen onafhankelijke
cursus 23 mei 2012 werkcollege 8 correlatie, regressie - D&P5: Summarizing Bivariate Data relatie tussen variabelen onderzoek streeft naar inzicht in relatie tussen variabelen bv. tussen onafhankelijke
SPSS Introductiecursus. Sanne Hoeks Mattie Lenzen
 SPSS Introductiecursus Sanne Hoeks Mattie Lenzen Statistiek, waarom? Doel van het onderzoek om nieuwe feiten van de werkelijkheid vast te stellen door middel van systematisch onderzoek en empirische verzamelen
SPSS Introductiecursus Sanne Hoeks Mattie Lenzen Statistiek, waarom? Doel van het onderzoek om nieuwe feiten van de werkelijkheid vast te stellen door middel van systematisch onderzoek en empirische verzamelen
Tentamen Biostatistiek 1 voor BMT (2DM40), op maandag 5 januari 2009 14.00-17.00 uur
, op maandag 5 januari 2009 14.00-17.00 uur") Faculteit der Wiskunde en Informatica Tentamen Biostatistiek voor BMT (2DM4), op maandag 5 januari 29 4.-7. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en van een onbeschreven
Faculteit der Wiskunde en Informatica Tentamen Biostatistiek voor BMT (2DM4), op maandag 5 januari 29 4.-7. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en van een onbeschreven
Adviseren over onderzoeksmethoden: Het meten en analyseren van verandering
 Adviseren over onderzoeksmethoden: Het meten en analyseren van verandering 26 november 2004 Definition Bij variantie-analyse noemt men een factor met een vast aantal categoriën een fixed effect. Een factor
Adviseren over onderzoeksmethoden: Het meten en analyseren van verandering 26 november 2004 Definition Bij variantie-analyse noemt men een factor met een vast aantal categoriën een fixed effect. Een factor
Summary in Dutch 179
 Samenvatting Een belangrijke reden voor het uitvoeren van marktonderzoek is het proberen te achterhalen wat de wensen en ideeën van consumenten zijn met betrekking tot een produkt. De conjuncte analyse
Samenvatting Een belangrijke reden voor het uitvoeren van marktonderzoek is het proberen te achterhalen wat de wensen en ideeën van consumenten zijn met betrekking tot een produkt. De conjuncte analyse
Samenvatting (Summary in Dutch)
") In dit proefschrift worden een aantal psychometrische methoden beschreven waarmee de accuratesse en efficientie van psychodiagnostiek in de klinische praktijk verbeterd kan worden. Psychodiagnostiek wordt
In dit proefschrift worden een aantal psychometrische methoden beschreven waarmee de accuratesse en efficientie van psychodiagnostiek in de klinische praktijk verbeterd kan worden. Psychodiagnostiek wordt
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica
 TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor TeMa (S95) Avondopleiding. donderdag 6-6-3, 9.-. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor TeMa (S95) Avondopleiding. donderdag 6-6-3, 9.-. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
Verband tussen twee variabelen
 Verband tussen twee variabelen Inleiding Dit practicum sluit aan op hoofdstuk I-3 van het statistiekboek en geeft uitleg over het maken van kruistabellen, het berekenen van de correlatiecoëfficiënt en
Verband tussen twee variabelen Inleiding Dit practicum sluit aan op hoofdstuk I-3 van het statistiekboek en geeft uitleg over het maken van kruistabellen, het berekenen van de correlatiecoëfficiënt en
Over het gebruik van continue normering Timo Bechger Bas Hemker Gunter Maris
 POK Memorandum 2009-1 Over het gebruik van continue normering Timo Bechger Bas Hemker Gunter Maris POK Memorandum 2009-1 Over het gebruik van continue normering Timo Bechger Bas Hemker Gunter Maris Cito
POK Memorandum 2009-1 Over het gebruik van continue normering Timo Bechger Bas Hemker Gunter Maris POK Memorandum 2009-1 Over het gebruik van continue normering Timo Bechger Bas Hemker Gunter Maris Cito
Gegevensverwerving en verwerking
 Gegevensverwerving en verwerking Staalname - aantal stalen/replicaten - grootte staal - apparatuur Experimentele setup Bibliotheek Statistiek - beschrijvend - variantie-analyse - correlatie - regressie
Gegevensverwerving en verwerking Staalname - aantal stalen/replicaten - grootte staal - apparatuur Experimentele setup Bibliotheek Statistiek - beschrijvend - variantie-analyse - correlatie - regressie
TYPE EXAMENVRAGEN VOOR TOEGEPASTE STATISTIEK
 TYPE EXAMENVRAGEN VOOR TOEGEPASTE STATISTIEK Prof. Dr. M. Vandebroek 1. Een aantal proefpersonen werd gevraagd een frisdrank te beoordelen door aan te geven in hoeverre ze het eens zijn met de volgende
TYPE EXAMENVRAGEN VOOR TOEGEPASTE STATISTIEK Prof. Dr. M. Vandebroek 1. Een aantal proefpersonen werd gevraagd een frisdrank te beoordelen door aan te geven in hoeverre ze het eens zijn met de volgende
Item-responstheorie (IRT)
") Item-responstheorie (IRT) niet direct voor een dubbeltje, maar wel erg cool op het podium Ruth van Nispen 1 Caroline Terwee 2 1 Afdeling Oogheelkunde 2 Afdeling Epidemiologie en Biostatistiek VU medisch
Item-responstheorie (IRT) niet direct voor een dubbeltje, maar wel erg cool op het podium Ruth van Nispen 1 Caroline Terwee 2 1 Afdeling Oogheelkunde 2 Afdeling Epidemiologie en Biostatistiek VU medisch
Zomerschool Vakdidactisch Onderzoek Leuven, 8-10 september 2010 Sessie 8: Analyse van kwantitatieve data
 Zomerschool Vakdidactisch Onderzoek Leuven, 8-10 september 2010 Sessie 8: Analyse van kwantitatieve data An Carbonez Leuven Statistics Research Centre Katholieke Universiteit Leuven Voorstelling van de
Zomerschool Vakdidactisch Onderzoek Leuven, 8-10 september 2010 Sessie 8: Analyse van kwantitatieve data An Carbonez Leuven Statistics Research Centre Katholieke Universiteit Leuven Voorstelling van de
REACH. Meetgegevens zijn nuttig onder REACH
 Meetgegevens zijn nuttig onder REACH Maar... Blootstellingschatting g onder REACH Schatten of meten? Voorkeur kwaliteit Efficientie/gemaki Goede Betrouwbaar Hoog Metingen Representatief Stof zelf Voldoende
Meetgegevens zijn nuttig onder REACH Maar... Blootstellingschatting g onder REACH Schatten of meten? Voorkeur kwaliteit Efficientie/gemaki Goede Betrouwbaar Hoog Metingen Representatief Stof zelf Voldoende
Inhoud. Neuronen. Synapsen. McCulloch-Pitts neuron. Sigmoids. De bouwstenen van het zenuwstelsel: neuronen en synapsen
 Tom Heskes IRIS, NIII Inhoud De bouwstenen van het zenuwstelsel: neuronen en synapsen Complex gedrag uit eenvoudige elementen McCulloch-Pitts neuronen Hopfield netwerken Computational neuroscience Lerende
Tom Heskes IRIS, NIII Inhoud De bouwstenen van het zenuwstelsel: neuronen en synapsen Complex gedrag uit eenvoudige elementen McCulloch-Pitts neuronen Hopfield netwerken Computational neuroscience Lerende
Hoofdstuk 10: Regressie
 Hoofdstuk 10: Regressie Inleiding In dit deel zal uitgelegd worden hoe we statistische berekeningen kunnen maken als sprake is van één kwantitatieve responsvariabele en één kwantitatieve verklarende variabele.
Hoofdstuk 10: Regressie Inleiding In dit deel zal uitgelegd worden hoe we statistische berekeningen kunnen maken als sprake is van één kwantitatieve responsvariabele en één kwantitatieve verklarende variabele.
INLEIDING EEN OVERZICHT VAN CORRECTIEMETHODEN
 INLEIDING Als je geïnteresseerd bent in de vraag welke van twee behandelingen of geneesmiddelen het beste werkt, zijn er grofweg twee manieren om dat te onderzoeken: experimenteel en observationeel. Bij
INLEIDING Als je geïnteresseerd bent in de vraag welke van twee behandelingen of geneesmiddelen het beste werkt, zijn er grofweg twee manieren om dat te onderzoeken: experimenteel en observationeel. Bij
Examen G0N34 Statistiek
 Naam: Richting: Examen G0N34 Statistiek 7 juni 2010 Enkele richtlijnen : Wie de vragen aanneemt en bekijkt, moet minstens 1 uur blijven zitten. Je mag gebruik maken van een rekenmachine, het formularium
Naam: Richting: Examen G0N34 Statistiek 7 juni 2010 Enkele richtlijnen : Wie de vragen aanneemt en bekijkt, moet minstens 1 uur blijven zitten. Je mag gebruik maken van een rekenmachine, het formularium
Aanpassingen takenboek! Statistische toetsen. Deze persoon in een verdeling. Iedereen in een verdeling
 Kwantitatieve Data Analyse (KDA) Onderzoekspracticum Sessie 2 11 Aanpassingen takenboek! Check studienet om eventuele verbeteringen te downloaden! Huidige versie takenboek: 09 Gjalt-Jorn Peters gjp@ou.nl
Kwantitatieve Data Analyse (KDA) Onderzoekspracticum Sessie 2 11 Aanpassingen takenboek! Check studienet om eventuele verbeteringen te downloaden! Huidige versie takenboek: 09 Gjalt-Jorn Peters gjp@ou.nl
Cursus TEO: Theorie en Empirisch Onderzoek. Practicum 2: Herhaling BIS 11 februari 2015
 Cursus TEO: Theorie en Empirisch Onderzoek Practicum 2: Herhaling BIS 11 februari 2015 Centrale tendentie Centrale tendentie wordt meestal afgemeten aan twee maten: Mediaan: de middelste waarneming, 50%
Cursus TEO: Theorie en Empirisch Onderzoek Practicum 2: Herhaling BIS 11 februari 2015 Centrale tendentie Centrale tendentie wordt meestal afgemeten aan twee maten: Mediaan: de middelste waarneming, 50%
Kwantitatieve modellen. Harry B.G. Ganzeboom 18 april 2016 College 1: Meetkwaliteit
 Kwantitatieve modellen voor BCO PMC Harry B.G. Ganzeboom 18 april 2016 College 1: Meetkwaliteit Drie colleges Validiteits- en betrouwbaarheidsanalyse Causale analyse met confounding en mediatie Causale
Kwantitatieve modellen voor BCO PMC Harry B.G. Ganzeboom 18 april 2016 College 1: Meetkwaliteit Drie colleges Validiteits- en betrouwbaarheidsanalyse Causale analyse met confounding en mediatie Causale
introductie populatie- steekproef- steekproevenverdeling pauze parameters aannames ten slotte
 toetsende statistiek week 1: kansen en random variabelen week 2: de steekproevenverdeling Moore, McCabe, and Craig. Introduction to the Practice of Statistics Chapter 5: Sampling Distributions 5.1: The
toetsende statistiek week 1: kansen en random variabelen week 2: de steekproevenverdeling Moore, McCabe, and Craig. Introduction to the Practice of Statistics Chapter 5: Sampling Distributions 5.1: The
Beschrijvende statistiek
 Beschrijvende statistiek Beschrijvende en toetsende statistiek Beschrijvend Samenvatting van gegevens in de steekproef van onderzochte personen (gemiddelde, de standaarddeviatie, tabel, grafiek) Toetsend
Beschrijvende statistiek Beschrijvende en toetsende statistiek Beschrijvend Samenvatting van gegevens in de steekproef van onderzochte personen (gemiddelde, de standaarddeviatie, tabel, grafiek) Toetsend
20. Multilevel lineaire modellen
 20. Multilevel lineaire modellen Hiërarchische gegevens Veel fenomenen zijn ingebed in een bredere context. Variabelen kunnen dus ook hiërarchisch zijn, ingebed zijn in variabelen op hogere niveaus. Deze
20. Multilevel lineaire modellen Hiërarchische gegevens Veel fenomenen zijn ingebed in een bredere context. Variabelen kunnen dus ook hiërarchisch zijn, ingebed zijn in variabelen op hogere niveaus. Deze
Simulaties een revolutie in de didactiek van de statistiek
 Simulaties een revolutie in Simulaties de didactiek van de statistiek een revolutie in de didactiek van de statistiek Carel van de Giessen NVvWL november 2015 Van Althuis German Tank problem 1? German
Simulaties een revolutie in Simulaties de didactiek van de statistiek een revolutie in de didactiek van de statistiek Carel van de Giessen NVvWL november 2015 Van Althuis German Tank problem 1? German
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica. Tentamenopgaven Statistiek (2DD71) op xx-xx-xxxx, xx.00-xx.00 uur.
 op xx-xx-xxxx, xx.00-xx.00 uur.") VOORAF: Hieronder staat een aantal opgaven over de stof. Veel meer dan op het tentamen zelf gevraagd zullen worden. Op het tentamen zullen in totaal 20 onderdelen gevraagd worden. TECHNISCHE UNIVERSITEIT
VOORAF: Hieronder staat een aantal opgaven over de stof. Veel meer dan op het tentamen zelf gevraagd zullen worden. Op het tentamen zullen in totaal 20 onderdelen gevraagd worden. TECHNISCHE UNIVERSITEIT
Les 1: de normale distributie
 Les 1: de normale distributie Elke Debrie 1 Statistiek 2 e Bachelor in de Biomedische Wetenschappen 18 oktober 2018 1 Met dank aan Koen Van den Berge Indeling lessen Elke bullet point is een week. R en
Les 1: de normale distributie Elke Debrie 1 Statistiek 2 e Bachelor in de Biomedische Wetenschappen 18 oktober 2018 1 Met dank aan Koen Van den Berge Indeling lessen Elke bullet point is een week. R en
Hartpatiënten Stoppen met Roken De invloed van eigen effectiviteit, actieplannen en coping plannen op het stoppen met roken
 1 Hartpatiënten Stoppen met Roken De invloed van eigen effectiviteit, actieplannen en coping plannen op het stoppen met roken Smoking Cessation in Cardiac Patients Esther Kers-Cappon Begeleiding door:
1 Hartpatiënten Stoppen met Roken De invloed van eigen effectiviteit, actieplannen en coping plannen op het stoppen met roken Smoking Cessation in Cardiac Patients Esther Kers-Cappon Begeleiding door:
Wat gaan we doen? Help! Statistiek! Wat is een lineaire relatie? De rechte-lijn-vergelijking: Y = a + b X. Relatie tussen gewicht en lengte
 Help! Statistiek! Wat gaan we doen? Doel: Informeren over statistiek in klinisch onderzoek. Tijd: Doorlopende serie laagdrempelige lezingen, voor iedereen vrij toegankelijk. Derde woensdag in de maand,
Help! Statistiek! Wat gaan we doen? Doel: Informeren over statistiek in klinisch onderzoek. Tijd: Doorlopende serie laagdrempelige lezingen, voor iedereen vrij toegankelijk. Derde woensdag in de maand,
Data analyse Inleiding statistiek
 Data analyse Inleiding statistiek Terugblik - Inductieve statistiek Afleiden van eigenschappen van een populatie op basis van een beperkt aantal metingen (steekproef) Kennis gemaakt met kans & kansverdelingen
Data analyse Inleiding statistiek Terugblik - Inductieve statistiek Afleiden van eigenschappen van een populatie op basis van een beperkt aantal metingen (steekproef) Kennis gemaakt met kans & kansverdelingen
werkcollege 6 - D&P9: Estimation Using a Single Sample
 cursus 9 mei 2012 werkcollege 6 - D&P9: Estimation Using a Single Sample van frequentie naar dichtheid we bepalen frequenties van meetwaarden plot in histogram delen door totaal aantal meetwaarden > fracties
cursus 9 mei 2012 werkcollege 6 - D&P9: Estimation Using a Single Sample van frequentie naar dichtheid we bepalen frequenties van meetwaarden plot in histogram delen door totaal aantal meetwaarden > fracties
Citation for published version (APA): Agelink van Rentergem Zandvliet, J. A. (2018). Statistical advances in clinical neuropsychology.
: Agelink van Rentergem Zandvliet, J. A. (2018). Statistical advances in clinical neuropsychology.") UvA-DARE (Digital Academic Repository) Statistical advances in clinical neuropsychology Agelink van Rentergem Zandvliet, J.A. Link to publication Citation for published version (APA): Agelink van Rentergem
UvA-DARE (Digital Academic Repository) Statistical advances in clinical neuropsychology Agelink van Rentergem Zandvliet, J.A. Link to publication Citation for published version (APA): Agelink van Rentergem
Tentamen Biostatistiek 1 voor BMT (2DM40) woensdag 27 oktober 2010, uur
 woensdag 27 oktober 2010, uur") Faculteit der Wiskunde en Informatica Tentamen Biostatistiek voor BMT (2DM4) woensdag 27 oktober 2, 9.-2. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en van een onbeschreven
Faculteit der Wiskunde en Informatica Tentamen Biostatistiek voor BMT (2DM4) woensdag 27 oktober 2, 9.-2. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en van een onbeschreven
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica. Tentamen Statistiek 2 voor TeMa (2S195) op dinsdag ,
 op dinsdag ,") TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek 2 voor TeMa (2S95) op dinsdag 5-03-2005, 9.00-22.00 uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek 2 voor TeMa (2S95) op dinsdag 5-03-2005, 9.00-22.00 uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
Bij herhaalde metingen ANOVA komt het effect van het experiment naar voren bij de variantie binnen participanten. Bij de gewone ANOVA is dit de SS R
 14. Herhaalde metingen Introductie Bij herhaalde metingen worden er bij verschillende condities in een experiment dezelfde proefpersonen gebruikt of waarbij dezelfde proefpersonen op verschillende momenten
14. Herhaalde metingen Introductie Bij herhaalde metingen worden er bij verschillende condities in een experiment dezelfde proefpersonen gebruikt of waarbij dezelfde proefpersonen op verschillende momenten
Geautomatiseerde medicatiereviews bij polyfarmacie patiënten in de eerstelijn: een retrospectieve studie Eerstelijnsgeneeskunde (ELG) Radboudumc
 Radboudumc") Geautomatiseerde medicatiereviews bij polyfarmacie patiënten in de eerstelijn: een retrospectieve studie Eerstelijnsgeneeskunde (ELG) Radboudumc Jorrit Harms OSV: Dr. Kees van Boven Inhoud Achtergrond
Geautomatiseerde medicatiereviews bij polyfarmacie patiënten in de eerstelijn: een retrospectieve studie Eerstelijnsgeneeskunde (ELG) Radboudumc Jorrit Harms OSV: Dr. Kees van Boven Inhoud Achtergrond
Statistiek in de alfa en gamma studies. Aansluiting wiskunde VWO-WO 16 april 2018
 Statistiek in de alfa en gamma studies Aansluiting wiskunde VWO-WO 16 april 2018 Wie ben ik? Marieke Westeneng Docent bij afdeling Methoden en Statistiek Faculteit Sociale Wetenschappen Universiteit Utrecht
Statistiek in de alfa en gamma studies Aansluiting wiskunde VWO-WO 16 april 2018 Wie ben ik? Marieke Westeneng Docent bij afdeling Methoden en Statistiek Faculteit Sociale Wetenschappen Universiteit Utrecht
(slope in het Engels) en het snijpunt met de y-as, b 0
 en het snijpunt met de y-as, b 0") 8. Regressie Een introductie Al vaak is genoemd dat statistische modellen allemaal neerkomen op uitkomst = model + error. Dit model kun je ook gebruiken om de uitkomst te voorspellen, met een correlatie
8. Regressie Een introductie Al vaak is genoemd dat statistische modellen allemaal neerkomen op uitkomst = model + error. Dit model kun je ook gebruiken om de uitkomst te voorspellen, met een correlatie
Regression Analysis for Interval-Valued Data
 Regression Analysis for Interval-Valued Data Mousa Negash 431898 July 8, 2018 Abstract In dit paper worden verschillende regressiemethoden uitgevoerd op symbolische data om vervolgens te oordelen welke
Regression Analysis for Interval-Valued Data Mousa Negash 431898 July 8, 2018 Abstract In dit paper worden verschillende regressiemethoden uitgevoerd op symbolische data om vervolgens te oordelen welke
DANKBAARHEID, PSYCHOLOGISCHE BASISBEHOEFTEN EN LEVENSDOELEN 1
 DANKBAARHEID, PSYCHOLOGISCHE BASISBEHOEFTEN EN LEVENSDOELEN 1 Dankbaarheid in Relatie tot Intrinsieke Levensdoelen: Het mediërende Effect van Psychologische Basisbehoeften Karin Nijssen Open Universiteit
DANKBAARHEID, PSYCHOLOGISCHE BASISBEHOEFTEN EN LEVENSDOELEN 1 Dankbaarheid in Relatie tot Intrinsieke Levensdoelen: Het mediërende Effect van Psychologische Basisbehoeften Karin Nijssen Open Universiteit
Kansrekening en Statistiek
 Kansrekening en Statistiek College 16 Donderdag 4 November 1 / 25 2 Statistiek Indeling: Schatten Correlatie 2 / 25 Schatten 3 / 25 Schatters: maximum likelihood schatters Def. Zij Ω de verzameling van
Kansrekening en Statistiek College 16 Donderdag 4 November 1 / 25 2 Statistiek Indeling: Schatten Correlatie 2 / 25 Schatten 3 / 25 Schatters: maximum likelihood schatters Def. Zij Ω de verzameling van
Enkelvoudige ANOVA Onderzoeksvraag Voorwaarden
 Er is onderzoek gedaan naar rouw na het overlijden van een huisdier (contactpersoon: Karolijne van der Houwen (Klinische Psychologie)). Mensen konden op internet een vragenlijst invullen. Daarin werd gevraagd
Er is onderzoek gedaan naar rouw na het overlijden van een huisdier (contactpersoon: Karolijne van der Houwen (Klinische Psychologie)). Mensen konden op internet een vragenlijst invullen. Daarin werd gevraagd
Single and Multi-Population Mortality Models for Dutch Data
 Single and Multi-Population Mortality Models for Dutch Data Wilbert Ouburg Universiteit van Amsterdam 7 Juni 2013 Eerste begeleider: dr. K. Antonio Tweede begeleider: prof. dr. M. Vellekoop Wilbert Ouburg
Single and Multi-Population Mortality Models for Dutch Data Wilbert Ouburg Universiteit van Amsterdam 7 Juni 2013 Eerste begeleider: dr. K. Antonio Tweede begeleider: prof. dr. M. Vellekoop Wilbert Ouburg
Samenvatting. Inleiding
 Samenvatting Het percentage volwassenen met een hoog risico op een angststoornis of depressie ligt in de gemeenten Roosendaal (9.7%) en Rucphen (11.0%) significant en relevant hoger dan landelijk (7.1%).
Samenvatting Het percentage volwassenen met een hoog risico op een angststoornis of depressie ligt in de gemeenten Roosendaal (9.7%) en Rucphen (11.0%) significant en relevant hoger dan landelijk (7.1%).
Biostatistiek en epidemiologie (4sp)
") Biostatistiek en epidemiologie (4sp) ECTS-fiche 13/1/2017 Statistiek 1. voorbeeldvraag van Statistiek over randomisatie a. 1:1 verdeling is meestal beste voor vergelijken b. 2:1 randomisatie is een vereiste
Biostatistiek en epidemiologie (4sp) ECTS-fiche 13/1/2017 Statistiek 1. voorbeeldvraag van Statistiek over randomisatie a. 1:1 verdeling is meestal beste voor vergelijken b. 2:1 randomisatie is een vereiste
Technische appendix bij DNBulletin Voor lagere werkloosheid is meer economische groei nodig. Variable Coefficient Std. Error t-statistic Prob.
 Technische appendix bij DNBulletin Voor lagere werkloosheid is meer economische groei nodig Schatting Okun s law; Nederland, periode 1979-2017 Variabelen Afhankelijke variabele UD= jaar op jaarmutatie
Technische appendix bij DNBulletin Voor lagere werkloosheid is meer economische groei nodig Schatting Okun s law; Nederland, periode 1979-2017 Variabelen Afhankelijke variabele UD= jaar op jaarmutatie
ANOVA in SPSS. Hugo Quené. opleiding Taalwetenschap Universiteit Utrecht Trans 10, 3512 JK Utrecht 12 maart 2003
 ANOVA in SPSS Hugo Quené hugo.quene@let.uu.nl opleiding Taalwetenschap Universiteit Utrecht Trans 10, 3512 JK Utrecht 12 maart 2003 1 vooraf In dit voorbeeld gebruik ik fictieve gegevens, ontleend aan
ANOVA in SPSS Hugo Quené hugo.quene@let.uu.nl opleiding Taalwetenschap Universiteit Utrecht Trans 10, 3512 JK Utrecht 12 maart 2003 1 vooraf In dit voorbeeld gebruik ik fictieve gegevens, ontleend aan
Stochastiek 2. Inleiding in the Mathematische Statistiek. staff.fnwi.uva.nl/j.h.vanzanten
 Stochastiek 2 Inleiding in the Mathematische Statistiek staff.fnwi.uva.nl/j.h.vanzanten 1 / 12 H.1 Introductie 2 / 12 Wat is statistiek? - 2 Statistiek is de kunst van het (wiskundig) modelleren van situaties
Stochastiek 2 Inleiding in the Mathematische Statistiek staff.fnwi.uva.nl/j.h.vanzanten 1 / 12 H.1 Introductie 2 / 12 Wat is statistiek? - 2 Statistiek is de kunst van het (wiskundig) modelleren van situaties
Samenvatting. geweest als de gemaakte keuzes, namelijk opereren. Het model had daarom voor deze patiënten weinig toegevoegde waarde.
 Klinische predictiemodellen combineren patiëntgegevens om de kans te voorspellen dat een ziekte aanwezig is (diagnose) of dat een bepaalde ziekte status zich zal voordoen (prognose). De voorspelde kans
Klinische predictiemodellen combineren patiëntgegevens om de kans te voorspellen dat een ziekte aanwezig is (diagnose) of dat een bepaalde ziekte status zich zal voordoen (prognose). De voorspelde kans
De Samenhang tussen Dagelijkse Stress, Emotionele Intimiteit en Affect bij Partners met een. Vaste Relatie
 De Samenhang tussen Dagelijkse Stress, Emotionele Intimiteit en Affect bij Partners met een Vaste Relatie The Association between Daily Stress, Emotional Intimacy and Affect with Partners in a Commited
De Samenhang tussen Dagelijkse Stress, Emotionele Intimiteit en Affect bij Partners met een Vaste Relatie The Association between Daily Stress, Emotional Intimacy and Affect with Partners in a Commited
HOOFDSTUK VIII VARIANTIE ANALYSE (ANOVA)
") HOOFDSTUK VIII VARIANTIE ANALYSE (ANOVA) DATA STRUKTUUR Afhankelijke variabele: Eén kontinue variabele Onafhankelijke variabele(n): - één discrete variabele: één gecontroleerde factor - twee discrete variabelen:
HOOFDSTUK VIII VARIANTIE ANALYSE (ANOVA) DATA STRUKTUUR Afhankelijke variabele: Eén kontinue variabele Onafhankelijke variabele(n): - één discrete variabele: één gecontroleerde factor - twee discrete variabelen:
Examen Statistiek I Feedback
 Examen Statistiek I Feedback Bij elke vraag is alternatief A correct. Bij de trekking van een persoon uit een populatie beschouwt men de gebeurtenissen A (met bril), B (hooggeschoold) en C (mannelijk).
Examen Statistiek I Feedback Bij elke vraag is alternatief A correct. Bij de trekking van een persoon uit een populatie beschouwt men de gebeurtenissen A (met bril), B (hooggeschoold) en C (mannelijk).
Tentamen Biostatistiek 1 voor BMT (2DM40) woensdag 28 oktober 2009, 9.00-12.00 uur
 woensdag 28 oktober 2009, 9.00-12.00 uur") Faculteit der Wiskunde en Informatica Tentamen Biostatistiek voor BMT (DM4) woensdag 8 oktober 9, 9.-. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en van een onbeschreven Statistisch
Faculteit der Wiskunde en Informatica Tentamen Biostatistiek voor BMT (DM4) woensdag 8 oktober 9, 9.-. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en van een onbeschreven Statistisch
Kansrekening en statistiek wi2105in deel 2 16 april 2010, uur
 Kansrekening en statistiek wi205in deel 2 6 april 200, 4.00 6.00 uur Bij dit examen is het gebruik van een (evt. grafische) rekenmachine toegestaan. Tevens krijgt u een formuleblad uitgereikt na afloop
Kansrekening en statistiek wi205in deel 2 6 april 200, 4.00 6.00 uur Bij dit examen is het gebruik van een (evt. grafische) rekenmachine toegestaan. Tevens krijgt u een formuleblad uitgereikt na afloop
College 6. Samenhang tussen variabelen. Inleiding M&T Hemmo Smit
 College 6 Samenhang tussen variabelen Inleiding M&T 2012 2013 Hemmo Smit Overzicht van deze cursus 1. Grondprincipes van de wetenschap 2. Observeren en meten 3. Interne consistentie; Beschrijvend onderzoek
College 6 Samenhang tussen variabelen Inleiding M&T 2012 2013 Hemmo Smit Overzicht van deze cursus 1. Grondprincipes van de wetenschap 2. Observeren en meten 3. Interne consistentie; Beschrijvend onderzoek
Methoden van het Wetenschappelijk. Onderzoek. Zin en onzin van statistiek
 Methoden van het Wetenschappelijk Onderzoek Zin en onzin van statistiek Statistiek komt ernstig over of niet Deze tandpasta helpt tegen caries in 1 op 2 gevallen. Het werd slechts geprobeerd op 4 personen.
Methoden van het Wetenschappelijk Onderzoek Zin en onzin van statistiek Statistiek komt ernstig over of niet Deze tandpasta helpt tegen caries in 1 op 2 gevallen. Het werd slechts geprobeerd op 4 personen.
Voorbeeld regressie-analyse
 Voorbeeld regressie-analyse In dit voorbeeld wordt gebruik gemaakt van het SPSS data-bestand vb_regr.sav (dit bestand kan gedownload worden via de on-line helpdesk). We schatten een model waarin de afhankelijke
Voorbeeld regressie-analyse In dit voorbeeld wordt gebruik gemaakt van het SPSS data-bestand vb_regr.sav (dit bestand kan gedownload worden via de on-line helpdesk). We schatten een model waarin de afhankelijke
Gezinsinkomen en kansenongelijkheid Cijfers bij beschouwend artikel Didactief mei 2018
 Gezinsinkomen en kansenongelijkheid Cijfers bij beschouwend artikel Didactief mei 2018 De slides illustreren achtereenvolgens: 1 De overheid demonstreert een sterk verband tussen gezinsinkomen en bereikt
Gezinsinkomen en kansenongelijkheid Cijfers bij beschouwend artikel Didactief mei 2018 De slides illustreren achtereenvolgens: 1 De overheid demonstreert een sterk verband tussen gezinsinkomen en bereikt