Cursus Inleiding Bayesiaanse statistiek. Docent: drs. Rob Flohr
|
|
|
- Irena Marina Hermans
- 7 jaren geleden
- Aantal bezoeken:
Transcriptie
1 Cursus Inleiding Bayesiaanse statistiek Docent: drs. Rob Flohr 1

2 Les 1 (0) Vooraf: waar gaat het vak statistiek eigenlijk over, wat houdt het in, wat voor soort kennis over de werkelijkheid levert het op? (Dat laatste wordt ook wel aangeduid als de epistemologische basis van de statistiek: 'epistemologie' betekent letterlijk kennisleer en gaat o.a. over het soort kennis dat aan de orde is). Op deze vraag kunnen verschillende antwoorden gegeven worden, bijvoorbeeld 'het toepassen van de geschikte statistische procedures op de data om bepaalde conclusies te kunnen trekken of bepaalde beslissingen (bijv. wel of niet verwerpen van een nulhypothese) te kunnen nemen'. Mede op basis van Joseph Lee Rodgers (2010). The Epistemology of Mathematical and Statistical Modeling. A Quiet Methodological revolution. American Psychologist, Vol. 65, No. 1, 1-12, kies ik een andere invalshoek, namelijk die van het modelbegrip. Je kunt de aard en inhoud van het vak statistiek dan als volgt omschrijven: We hebben data verkregen over een bepaald verschijnsel of 'systeem' in de werkelijkheid. De data zijn een uitdrukking van dat systeem en dat proces van uitdrukken interpreteren we vanuit een stochastisch referentiekader, d.w.z. dat de data worden gegenereerd door een specifieke kansverdeling die het systeem in kwestie adequaat beschrijft. Vanwege dat stochastisch element - de betreffende kansverdeling - ligt het niet vast welke data er op een bepaald moment vanuit het systeem verkregen worden, dat wordt bepaald door toeval, wat we zullen waarnemen is daardoor tot op zekere hoogte onvoorspelbaar (data zijn niet deterministisch maar stochastisch bepaald). Het betreffende systeem wordt gekarakteriseerd door grootheden die we parameters noemen en die specifieke waarden hebben zoals een bepaald gemiddelde, een bepaalde proportie of spreiding etc. We benaderen het 'systeem' met behulp van een model waarbij we onze data aan de hand van een of meer specifieke kansverdelingen relateren aan de parameters van het systeem. De specifieke kansverdeling wordt namelijk, zoals hierboven reeds genoemd, verondersteld de data (vanuit het 'systeem') te genereren en daarom is het van essentieel belang dat de betreffende kansverdeling goed past bij de aard van het 'systeem'. Er zijn vele soorten kansverdelingen ontwikkeld en elke kansverdeling past bij een bepaald type 'systeem' (bijvoorbeeld de houdbaarheidstermijn van een griepvaccin, het aantal verkeersongelukken op een bepaalde snelweg, het gewicht van een populatie slechtvalken etc.). Elke kansverdeling heeft een of meerdere parameters die dan op basis van de data geschat kunnen worden. Het model is in principe wiskundig van aard maar door het toevoegen van een stochastisch element wordt het een statistisch model (zie hieronder). 2
 te kunnen nemen'. Mede op basis van Joseph Lee Rodgers (2010). The Epistemology of Mathematical and Statistical Modeling.")
3 * op basis van de data construeren we een model * doel van een model: het beschrijven van het data-genererende proces * een model heeft een of meerdere parameters * deze parameters worden geschat op basis van de data * daartoe gebruiken we de likelihood functie: een kansdichtheidsfunctie van de data gegeven verschillende parameter-waarden (de likelihoodfunctie bevat de informatie die de data ons verschaft over de onbekende parameters; zie bijv. Lesaffre & Lawson, pp ) Op basis van het model schatten we de waarden van de parameters (de karakteristieken van het systeem). Omdat we die parameterwaarden alleen maar kunnen schatten ( de echte parameterwaarden kennen we niet en zullen we ook nooit kennen) hebben we te maken met onzekerheid. Dit element van onzekerheid (stochastisch element) maakt het model een statistisch model (denk aan de 'error'- term in een regressievergelijking). Het vak statistiek houdt zich in de kern bezig met het kwantificeren van die onzekerheid, dus de onzekerheid die inherent is aan uitspraken over de parameterwaarden van het systeem. Dat kwantificeren van onzekerheid omtrent de parameterschatting - gevolg van het feit dat we slechts over een beperkte hoeveelheid informatie (data) beschikken - kunnen we tot uitdrukking brengen door middel van een betrouwbaarheidsinterval. Om zo'n betrouwbaarheidsinterval te kunnen bepalen hebben we een kansverdeling nodig die we moeten relateren aan de verkregen data. We kunnen deze kansverdeling verkrijgen: a) langs Bayesiaanse weg: door een prior kansverdeling te kiezen en deze te actualiseren op basis van de verkregen data, kunnen we een posterior kansverdeling afleiden volgens de 'probability calculus' (de axioma's en afleidingsregels van de kansrekening). Op basis van deze posterior kansverdeling kunnen we vervolgens een betrouwbaarheidsinterval ('credible interval' in Bayesiaanse termen) afleiden b) langs frequentistische weg: de steekproevenverdeling ('sampling distribution') is de kansverdeling op grond waarvan we een betrouwbaarheidsinterval kunnen bepalen. Om zo'n steekproevenverdeling te verkrijgen, moeten we eerst een nulhypothese toetsen. De steekproevenverdeling is namelijk gebaseerd op de volgende redenering: we kiezen een bepaalde nulhypothesewaarde - hetgeen inhoudt dat de parameter als een deterministische grootheid wordt opgevat en niet als een stochast - en we gaan vervolgens na in hoeverre de verkregen data verenigbaar zijn met die nulhypothesewaarde (in de zin dat, uitgaande van de juistheid van de nulhypothesewaarde en van het - hypothetisch - vele malen herhalen van de procedure van dataverzameling en het vergelijken van de data met de nulhypothesewaarde, we nagaan in hoeveel procent van de gevallen we een uitkomst vinden die minstens zo extreem is als de in werkelijkheid verkregen data). Je zou dus kunnen zeggen dat de nulhypothesetoetsing slechts een hulpmiddel of instrument is om een betrouwbaarheidsinterval te kunnen bepalen. 3
 hebben we te maken met onzekerheid.")
4 Een voorbeeld ter illustratie. er is een munt uit de Romeinse tijd opgegraven en we willen weten hoe zuiver die munt is (bijvoorbeeld omdat we weten dat in die tijd belangrijke beslissingen werden genomen door zo'n munt op te gooien). We gooien de munt 20 keer en we vinden 5 keer kop. Het systeem: de fysieke eigenschappen van de munt Parameter: de proportie kop Data: 5 keer kop uit 20 worpen Kansverdeling: binomiale kansverdeling Hieronder zullen we dit vraagstuk zowel frequentistisch als Bayesiaans analyseren. (Filosofische) uitgangspunten van frequentistische en Bayesiaanse statistiek a) frequentistisch: alleen de data (observaties) zijn stochastisch van aard; de verdeling van de uitkomsten van een experiment of van de resultaten van 'random draws' is gebaseerd op toeval ('chance'). Dit betekent dat alle andere zaken zoals de kans op een bepaalde uitkomst in een experiment maar ook het proces dat de data genereert, deterministisch en niet stochastisch van aard zijn. Verder is de freq. redeneerwijze gebaseerd op het concept van de limiet van een relatieve frequentie (invulling van het begrip kans) hetgeen betekent dat een grote hoeveelheid observaties wordt verondersteld. b) Bayesiaans: alles wat we niet kennen wordt als stochastisch van aard beschouwd, dus niet alleen de data maar ook de kans op een bepaalde uitkomst maar ook het proces dat de data genereert. het begrip kans wordt opgevat als een 'personal degree of belief', gebaseerd op zowel reeds beschikbare kennis als recente observaties. Daarbij wordt een onderscheid gemaakt tussen subjectieve Bayesiaanse statistiek (alle informatie mag voor een prior gebruikt worden) en objectieve Bayesiaanse statistiek (alleen informatie die formeel-wiskundig afgeleid kan worden uit het probleem mag voor priors gebruikt worden). Uit het bovenstaande blijkt dat een model tenminste bestaat uit de data, een of meer parameters en een of meer kansverdelingen. Voor Bayesiaanse modellen komen daar nog een of meer 'prior'- kansverdelingen bij (voor elke parameter een aparte 'prior'). Een belangrijk verschil tussen beide benaderingen is dat een parameter binnen de frequentistische benadering als een vaste maar onbekende grootheid, maar binnen de Bayesiaanse benadering als een kansvariabele (stochast) wordt opgevat. Tenslotte: merk op dat: a) een statistisch model (bijv. een lineair regressiemodel) een model is dat op verschillende manieren geanalyseerd kan worden, zoals frequentistisch of Bayesiaans. Een statistisch model op zich is dus noch frequentistisch, noch Bayesiaans. b) een gekozen model statistisch geëvalueerd moet worden, met name ten aanzien van *'model fit' : hoe goed past het model bij de data?, denk in dit verband aan residuenanalyse en R^2-4

5 waarde bij lineaire regressie en aan de 'predictive posterior distribution' bij Bayesiaanse analyses. **'parsimony'/complexiteit. Over het algemeen geldt: streef naar een zo eenvoudig model wanneer de verklarings-/voorspellingskracht hetzelfde is of nauwelijks meer toeneemt. R.Fisher, een van de grondleggers van de frequentistische statistiek sprak over data in termen van 'statistical currency'. Met je data kun je parameters schatten maar voor elke extra parameter die je schat lever je wel in: het aantal vrijheidsgraden neemt af en zo hou je minder data over voor andere zaken zoals het checken van de 'model fit'. Hoe meer parameters je in je model stopt (denk bijv. aan het aantal onafhankelijke variabelen/'predictors' i.g.v. een regressiemodel), hoe beter in het algemeen je model past bij de data. Maar ook, hoe meer bronnen van onzekerheid ('error') gaan meespelen (elke parameter moet immers geschat worden) en dus hoe minder precies bijvoorbeeld je voorspellingen zullen zijn. Het gaat dus om een uitruil ('trade off') van 'model fit' en 'parsimony'. c) we nooit direct toegang hebben tot de werkelijkheid/een 'systeem'. Dat brengt met zich mee dat we te maken hebben met verschillende soorten fouten, 'errors'. Zo is er de 'sampling error': omdat de data langs stochastische weg gegenereerd worden, kunnen de data per steekproef wat verschillen. Dat betekent dat we voor een specifieke dataset niet weten hoe adequaat onze data het systeem (en onze steekproefgrootheden- bijv. het steekproefgemiddelde- de corresponderende parameter) adequaat weerspiegelen. In de frequentistische statistiek komt deze 'sampling error' tot uitdrukking in de stadaardfout ('standard error'), zijnde de standaarddeviatie van de steekproevenverdeling ('sampling distribution'). De steekproevenverdeling is een kansverdeling die de mogelijke uitkomsten van een steekproefgrootheid (meestal het asteekproefgemidelde) beschrijft met de bijbehorende kansen. De steekproevenverdeling is theoretisch gefundeerd in de Centrale Limiet Stelling maar kan ook empirisch - bijv. via 'bootstrapping' - afgeleid worden. Een beperking is dat slechts voor een beperkt aantal steekproefgrootheden zo'n steekproevenverdeling langs theoretische weg afgeleid kan worden (wat algemener geformuleerd: het is vaak een probleem om een geschikte kansverdeling te vinden waarmee overschrijdingskansen kunnen worden berekend). In de Bayesiaanse statistiek komt de 'sampling error' tot uitdrukking in de standaarddeviatie van de 'posterior' kansverdeling. In principe zijn hier geen beperkingen aanwezig t.a.v. het aantal mogelijke steekproefgrootheden. Verder kun je de verkregen data beschouwen als de 'rijkdom' waarover de onderzoeker beschikt (vgl. Fisher's 'statistical currency'). Dat betekent dat de kwaliteit van de data een grote rol speelt. In dit verband hebben we te maken met de mogelijkheid van 'measurement errors'. Zo dien je aandacht te besteden aan de betrouwbaarheid van je metingen en ingeval van scores die verkregen zijn via vragenlijsten dien je na te gaan in hoeveer de geobserveerde scores overeenkomen met de werkelijke scores(de score die een respondent invult en de score die echt geldt). Dit hangt onder meer samen met de deugdelijkhied van de theoretische begrippen ('constructen') die in de vragenlijst worden gebruikt: zijn de begrippen goed gedefinieerd?, zijn ze theoretische goed onderbouwd?, zijn ze adequaat geoperationaliseerd? Daarnaast zijn er nog andere vormen van zogeheten 'non-sampling errors' zoals 'missing data errors', 'coverage errors' (populatie en/of steekproef zijn niet goed in kaart gebracht), errors vanwege het 5

6 niet goed behandelen van de data enz. Over verschillende soorten van onzekerheid: (ontleend aan Directoraat-Generaal Rijkswaterstaat (2002): Bayesiaanse statistiek voor de analyse van extreme waarden, pp ). Lelystad jan. 2002) (I) Statistical inference gaat over: kwantificeren van onzekerheid ter toelichting: zie Kéry (2010), p. 14 : over onderscheid kansrekening en statistiek (in de context van : statistiek -> kwantificeren va onzekerheid) kansrekening: je specificeert een kansverdeling (bijv. binomiale verdeling i.v.m. gooien van een munt) en je specificeert een parameterwaarde. Op basis daarvan bereken je de kansen op alle mogelijke uitkomsten van de kansvariabele (o.a. kans op 3x kop en 7x munt bij proportie kop=0.5). statistiek: je begint met de data (bijv. je hebt 3x kop en 7x munt gegooid) en op basis van een model (hier binomiaal) en van de data (en eventueel van een prior belief) schat je de parameterwaarde (hier: de proportie kop van de betreffende munt). Let wel: die proportie zul je nooit te weten komen, die kun je alleen schatten (= onzekerheid). De onzekerheid kun je kwantificeren in de vorm van een..% betrouwbaarheids- resp. credible interval. (II) Bayesiaans vs frequentistisch: Frequentistisch: Je kiest een nulhypothese en je gaat m.b.v. een overschrijdingskans ( p-waarde) na in welke mate de gevonden data verenigbaar zijn met die nulhypothese. Het komt erop neer dat je de volgende kans bepaalt: PD H 0 Bayesiaans: Op basis van de posterior bepaal je de volgende kans: P H D voorbeeld van kikker en vijver (McCarthy 2013: p. 4) gebruiken om specifieke aard van freq. resp. Bayesiaanse manier van redeneren te illustreren) N.a.v. Kéry (2010) pp
 kansrekening: je specificeert een kansverdeling (bijv. binomi")
7 statistics: how to learn about parameter values in a stochastic system freq. en bayes. : gemeenschappelijk: in beide benaderingen worden de data opgevat als "the observed realizations of stochastic systems that contain one or several random processes". verschillen: 1) mbt parameters (= "quantities used to describe these random processes": "key descriptors" van een stochastisch systeem): freq.: parameters are fixed and unknown quantities; Bayes.: parameters are unobserved realizations of random processes (dus bij Bayes. heb je observed (data) and unobserved (parameters) realizations of random processes. Omdat in de Bayesiaanse statistiek de parameters worden behandeld als kansvariabelen, kunnen we op basis van de data en het statistisch model de parameterwaarden schatten. 2) mbt onzekerheid: Hoe wordt die tot uitdrukking gebracht? -> (a) freq.: "uncertainty is evaluated and described in terms of the frequency of hypothetical replicates (hoewel je slechts over één dataset beschkit) (b) Bayes. "uncertainty is evaluated using the posterior distribution of a parameter (= voorwaardelijke kansverdeling van de parameter gegeven: - de data - het model - de prior) 3) mbt begrip kans: freq. : kans = relatieve frequentie van een bepaalde karakteristiek van de data Bayes. : kans = uitdrukking van iemands onzekerheid omtrent een parameterwaarde NB a) freq. : alleen de data zijn random grootheden b) Bayes. : directe kansuitspraken over parameterwaarden zijn mogelijk ( de parameters zijn kansvariabelen) c) Bayes. : fundamenteel onderscheid tussen observable quantities (data) and unobservable quantities (parameters) 4) wat betreft de discussie rond de voor-en nadelen van priors: zie Kéry (2010) pag. 18 5) voor bondige karakteristiek van de Bayesiaanse analyse, zie Kéry (2010) pag. 20 6) MCMC-simulaties: technieken om trekkingen uit de posterior verdeling te simuleren, gegeven een 7
 and unobserved (parameters) realizations of random processes.")
8 model, een likelihood en de data. Uiteindelijk verkrijgen we op deze manier een steekproef uit de posterior verdeling Zie Kéry (2010) p. 20 en a) statistiek: komt in essentie neer op het kwantificeren van onzekerheid (zie boven) b) de manier waarop binnen de frequentistische statistiek dit aspect van onzekerheid vorm wordt gegeven (dmv p-waarde en frequentie van 'hypothetical replicates' ) heeft als nadeel dat het een binaire of dichotome wijze van redeneren tot gevolg heeft (wel of niet nulhypothese verwerpen) c) een dichotome wijze van denken staat op gespannen voet met denken in termen van onzekerheid; het verdient de voorkeur om onzekerheid uit te drukken dmv een interval (betrouwbaarheids- of credible interval) Beliefs (-> uncertainty) enerzijds en data (-> variation) anderzijds Belief: gedachte, aanname, opvatting, inschatting over iets in de werkelijkheid voorbeelden van beliefs: - de parameter-waarde van de stochastische variabele aantal keren kop (of munt) : wat is de proportie kop? - de mate van vooruitgang bij een TBS-patient enz. Twee manieren om Beliefs en data op elkaar te betrekken: frequentistisch (NHST) en Bayesiaans nadelen Bayes: 1) veel rekenwerk -> software 2) bepalen prior voor uitleg regel van Bayes zie boek en artikel Rob Flohr: uitleg theorema van Bayes: P h i e P e h Ph e P Ph e Pe hi Phi n Pe hk Phk k 1 prior en posterior prior en posterior toelichten aan de hand van driedeurenprobleem 8
 c) een dichotome wijze van denken staat op gespannen voet met denken in termen van")
9 Gebruik van R-software (packages, website: CRAN, pdf-manuals etc.) Voorbeeld: belief: in welke mate is deze munt zuiver? (=voorbeeld van parameter estimation value: de echte/ware proportie kop (of munt) van deze munt. drie doeleinden van statistical inference: 1) estimating parameter values 2) predicting missing data 3) model selection (model comparison) R version ( ) -- "Trick or Treat" Copyright (C) 2012 The R Foundation for Statistical Computing ISBN Platform: x86_64-w64-mingw32/x64 (64-bit) R is free software and comes with ABSOLUTELY NO WARRANTY. You are welcome to redistribute it under certain conditions. Type 'license()' or 'licence()' for distribution details. R is a collaborative project with many contributors. Type 'contributors()' for more information and 'citation()' on how to cite R or R packages in publications. Type 'demo()' for some demos, 'help()' for on-line help, or 'help.start()' for an HTML browser interface to help. Type 'q()' to quit R. [Previously saved workspace restored] > #Voorbeeld les 1 NHL 22 april 2014 > #Belief: betreft de (mate van) zuiverheid van een (oude) munt > #data: 20 keer gooien met de munt levert 5 keer kop op > #Volgens NHST: > pbinom(5,20,0.5) [1] > #P-waarde = 2 x 2069 is ongeveer 42 < 5 -> reject H0: munt is niet zuiver Beter (i.v.m. beschikbaarheid betrouwbaarheidsinterval) is via: > binom.test(5,20,0.5) Exact binomial test data: 5 and 20 number of successes = 5, number of trials = 20, p-value = 4139 alternative hypothesis: true probability of success is not equal to percent confidence interval: sample estimates: probability of success

10 > #Bayesiaans met discrete prior: > #Prior: P(pi=0.5)=0.40, P(pi=0.4)=0.30, P(pi=0.6)=0.30 > local({pkg <- select.list(sort(.packages(all.available = TRUE)),graphics=TRUE) + if(nchar(pkg)) library(pkg, character.only=true)}) Attaching package: Bolstad The following object(s) are masked _by_.globalenv : binodp Warning message: package Bolstad was built under R version > library(bolstad) > pi=c(0.4,0.5,0.6) > pi.prior=c(0.30,0.40,0.30) > results=binodp(5,20,pi,pi.prior) Conditional distribution of x given pi and n: e e e e e e-04 0 Joint distribution: [1,] 0 1e-04 9e [2,] 0 0e+00 1e [3,] 0 0e+00 0e [1,] e+00 0e+00 0 [2,] e-04 0e+00 0 [3,] e-04 1e-04 0 Marginal distribution of x: [1,] 0 2e [1,] e
 Conditional distribution of x given pi and n: 0 1 2 3 4 5 6 7 8 9 10 0.4 0 5e-04 031 123 350 746 0.1244 0.1659 0.1797 0.1597 0.1171 0.5 0 0e+00 002 011 046 148 370 739 0.1201 0.1602 0.1762 0.")
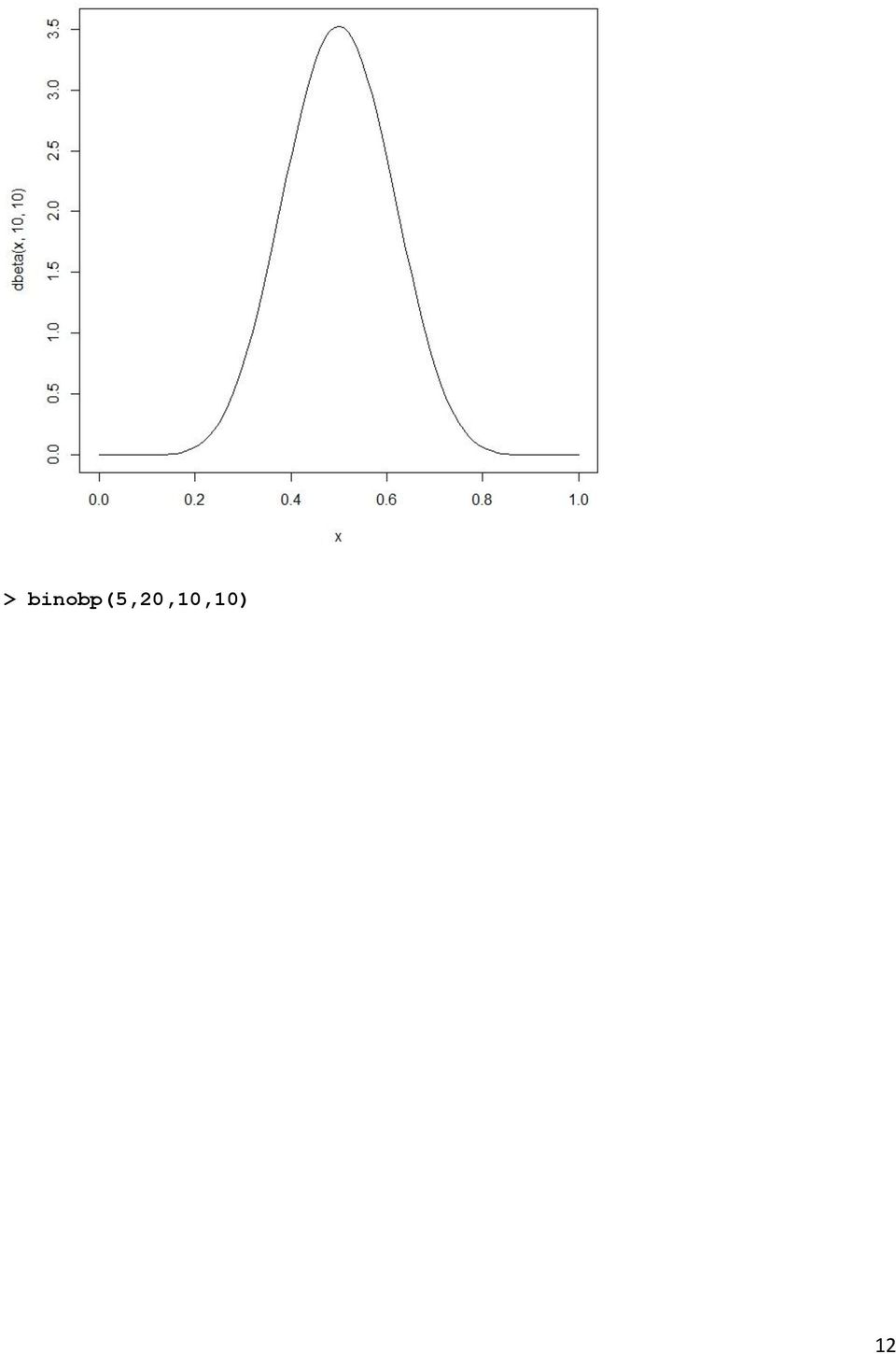
11 Prior Likelihood Posterior > #Continue prior: beta verdeling (10,10) > x=seq(0,1) > curve(dbeta(x,10,10)) 11

12 > binobp(5,20,10,10) 12
13 Posterior Mean : Posterior Variance : Posterior Std. Deviation : Prob. Quantile > Of m.b.v. LearnBayes-package: > library(learnbayes) > quantile1=list(p=5,x=0.40) > quantile2=list(p=0.95,x=0.60) > beta.select(quantile1,quantile2) [1]
 > quantile1=list(p=5,x=0.40) > quantile2=list(p=0.95,x=0.")
14 > x=seq(0,1) > curve(dbeta(x,33.43,33.43)) > local({pkg <- select.list(sort(.packages(all.available = TRUE)),graphics=TRUE) + if(nchar(pkg)) library(pkg, character.only=true)}) Attaching package: Bolstad The following object(s) are masked _by_.globalenv : binodp Warning message: package Bolstad was built under R version > library(bolstad) > binobp(5,20,33.43,33.43) Posterior Mean : Posterior Variance :

15 Posterior Std. Deviation : Prob. Quantile > Met gebruik van niet-informatieve prior (uniforme verdeling): 15

16 > local({pkg <- select.list(sort(.packages(all.available = TRUE)),graphics=TRUE) + if(nchar(pkg)) library(pkg, character.only=true)}) Attaching package: Bolstad The following object(s) are masked _by_.globalenv : binodp Warning message: package Bolstad was built under R version > library(bolstad) > x=seq(0,1) > curve(dbeta(x,1,1)) > binobp(5,20,1,1) Posterior Mean : Posterior Variance : Posterior Std. Deviation : Prob. Quantile % 'credible interval': zie rode getallen 16

17 Bij toename steekproefomvang: > binom.test(50,200,0.5) Exact binomial test data: 50 and 200 number of successes = 50, number of trials = 200, p-value = 8.393e-13 alternative hypothesis: true probability of success is not equal to percent confidence interval: sample estimates: probability of success 0.25 > binom.test(500,2000,0.5) Exact binomial test data: 500 and

18 number of successes = 500, number of trials = 2000, p-value < 2.2e-16 alternative hypothesis: true probability of success is not equal to percent confidence interval: sample estimates: probability of success 0.25 > local({pkg <- select.list(sort(.packages(all.available = TRUE)),graphics=TRUE) + if(nchar(pkg)) library(pkg, character.only=true)}) Attaching package: Bolstad The following object(s) are masked _by_.globalenv : binodp Warning message: package Bolstad was built under R version > library(bolstad) > binobp(50,200,1,1) Posterior Mean : Posterior Variance : Posterior Std. Deviation : Prob. Quantile
 > binobp(50,200,1,1) Posterior Mean : 0.2524752 Posterior Variance : 009297 Posterior Std. Deviation : 304912 Prob. Quantile ------ --------- 05 0.1788719 1 0.1853667 25 0.")
19 > binobp(500,2000,1,1) Posterior Mean : Posterior Variance : 9.37e-05 Posterior Std. Deviation : Prob. Quantile > 19

20 20

21 Huiswerkopgave voor les 2 In een onderzoek onder 1000 kinderen, uitgevoerd in het Verenigd Koninkrijk in juni 2005, voorafgaand aan het verschijnen van J.K. Rowlings Harry Potter and the Half Blood Prince, gaf 40 procent van de kinderen aan dat ze een exemplaar van het nieuwe boek tijdens het eerste weekend na publicatie zouden gaan bemachtigen. De uitgever van de Harry Potter boeken was uitgegaan van een populatieproportie van 38%. a) Vraag vanuit de klassieke statistiek: Houdt de uitkomst van de steekproef onder 1000 kinderen in dat de verwachting van de uitgever te laag was? Verklaar je antwoord. Omdat er al meerdere boeken in de Harry Potter-reeks verschenen waren, had de uitgever haar verwachting op basis van eerder verkregen informatie geformuleerd. Stel dat de uitgever was uitgegaan van de volgende discrete prior kansen: P P P b) Vraag vanuit de Bayesiaanse statistiek: Wat is de posterior kans op een proportie van 0.38 resp in de populatie van kinderen die een exemplaar van het nieuwe boek tijdens het eerste weekend na publicatie zouden gaan bemachtigen? Uitwerking: a) > binom.test(400,1000,0.38) Exact binomial test data: 400 and 1000 number of successes = 400, number of trials = 1000, p-value = alternative hypothesis: true probability of success is not equal to percent confidence interval: sample estimates: probability of success 0.4 Het antwoord is nee, omdat de steekproefuitkomst van 400 uit gezien de relatief hoge p-waarde van geen onwaarschijnlijke (uitzonderlijke of extreme) uitkomst is wanneer in werkelijkheid de populatieproportie 0.38 zou zijn. Of. vanuit het 95% betrouwbaarheidsinterval redenerend: wanneer we dit experiment (telkens aan 1000 kinderen vragen of ze het boek wel of niet gaan bemachtigen) vele malen zouden herhalen, dan zal de echte populatieproportie in 95% van alle gevallen tussen en liggen. En we zien dat de waarde van de nulhypothese 0.38 binnen dat interval ligt. b) 21
22 > local({pkg <- select.list(sort(.packages(all.available = TRUE)),graphics=TRUE) + if(nchar(pkg)) library(pkg, character.only=true)}) Attaching package: Bolstad The following object(s) are masked _by_.globalenv : binodp Warning message: package Bolstad was built under R version > library(bolstad) > pi=c(0.36,0.38,0.40) > pi.prior=c(5,0.75,0.20) > results=binodp(400,1000,pi,pi.prior) Conditional distribution of x given pi and n: Joint distribution: [1,] [2,] [3,] Marginal distribution of x: [1,] Prior Likelihood Posterior e e e
23 Of zonder Bolstad-package en direct vanuit R, op basis van P h i e P e h Ph e P Ph e Pe hi Phi n Pe hk Phk k 1 Prior kansen: P P P Likelihood: P 400 / > dbinom(400,1000,0.36) 23
24 [1] P 400 / > dbinom(400,1000,0.38) [1] P 400 / > dbinom(400,1000,0.40) [1] > prior x likelihood: voor : 5 x = voor : 0.75 x = voor : 0.20 x = posterior kansen: P / P / P /
25 Les 2 onderwerpen: 1) discrete en continue prior kansverdelingen 2) begrippen: conjugate prior en Bayesiaanse evenredigheid 3) Monte Carlo simulaties en Markov Chain Monte Carlo simulaties 4) installatie plus instructie R en gebruik van R-packages; MCMCpack in het bijzonder ad 1) continue kansvariabelen (met als voorbeeld: de beta-verdeling, zie lesmateriaal les 1 op 22 april) vanaf continue prior voorbeeld Harry Potter met uniforme prior (beta(1,1)-verdeling) In een onderzoek onder 1000 kinderen, uitgevoerd in het Verenigd Koninkrijk in juni 2005, voorafgaand aan het verschijnen van J.K. Rowlings Harry Potter and the Half Blood Prince, gaf 40 procent van de kinderen aan dat ze een exemplaar van het nieuwe boek tijdens het eerste weekend na publicatie zouden gaan bemachtigen. > local({pkg <- select.list(sort(.packages(all.available = TRUE)),graphics=TRUE) + if(nchar(pkg)) library(pkg, character.only=true)}) Attaching package: Bolstad The following object(s) are masked _by_.globalenv : binodp Warning message: package Bolstad was built under R version > library(bolstad) > binobp(400,1000,1,1) Posterior Mean : Posterior Variance : Posterior Std. Deviation : 1547 Prob. Quantile
26 > Vergelijk de uitkomsten van beide benaderingen: - klassiek 95% betrouwbaarheidsinterval : (zie uitwerking huiswerkopgave voor les 2) - Bayesiaans 95% 'credible interval' : / De uitkomsten liggen dicht bij elkaar (dit vanwege a) uniforme prior en b) relatief grote steekproef : n=1000) (bij toename van de steekproefomvang convergeren verschillende priors in de richting van eenzelfde posterior, zie boek De Bayesiaanse benadering, par. 4.4, pp ) Echter: a) de betekenis is verschillend!! b) bij een informatieve prior verandert het beeld; voorbeeld Harry Potter met informatieve prior (beta(606.78, )-verdeling) 26
27 In een onderzoek onder 1000 kinderen, uitgevoerd in het Verenigd Koninkrijk in juni 2005, voorafgaand aan het verschijnen van J.K. Rowlings Harry Potter and the Half Blood Prince, gaf 40 procent van de kinderen aan dat ze een exemplaar van het nieuwe boek tijdens het eerste weekend na publicatie zouden gaan bemachtigen. Stel dat de uitgever op basis van eerdere gegevens verwacht dat de kans 0.90 is dat de populatieproportie zal liggen tussen 36% en 40%. > local({pkg <- select.list(sort(.packages(all.available = TRUE)),graphics=TRUE) + if(nchar(pkg)) library(pkg, character.only=true)}) > library(learnbayes) > quantile1=list(p=5,x=0.36) > quantile2=list(p=0.95,x=0.40) > beta.select(quantile1,quantile2) [1] > local({pkg <- select.list(sort(.packages(all.available = TRUE)),graphics=TRUE) + if(nchar(pkg)) library(pkg, character.only=true)}) Attaching package: Bolstad The following object(s) are masked _by_.globalenv : binodp Warning message: package Bolstad was built under R version > library(bolstad) > binobp(400,1000,606.78,990.50) Posterior Mean : Posterior Variance : 9.14e-05 Posterior Std. Deviation : Prob. Quantile > 27
28 ad 2) begrippen: conjugate prior en Bayesiaanse evenredigheid In het geval van continue kansvariabelen wordt de formule: g L x1,..., xn h x1,..., xn g Lx1,..., xn d waarbij de noemer g Lx,..., xn 1 d de 'normalizing constant' wordt genoemd: het product van de prior en de likelihoodfunctie moet geïntegreerd worden over de parameter(s). Begrip conjugate prior: prior en posterior verdeling zijn van dezelfde familie. Voordeel: er hoeft niet geïntegreerd te worden, de parameters van de prior kansverdeling worden langs theoretische weg aangepast/ 'vervoegd' Een aantal conjugate priors staan hieronder (de lijst is niet volledig): Prior Likelihood Posterior Beta Binomiaal Beta Beta Negatief binomiaal Beta Gamma Poisson Gamma 28
29 Beta Geometrisch Beta Gamma Exponentieel Gamma Normaal Normaal (onbekende posterior ) Normaal Inverse Gamma 2 Normaal (onbekende ) Inverse Gamma Normaal/Gamma 2 Normaal (onbekende en ) Normaal/Gamma Dirichlet Multinomiaal Dirichlet N.B. In het geval van een conjugate prior is het in principe mogelijk om de posterior kansverdeling langs analytische/theoretische weg te vinden, alleen vraagt het veel rekenwerk, zie bijv. De Bayesiaanse benadering, p en Vandaar dat we ook in dat geval gebruik maken van software. In andere gevallen is het niet of zeer moeilijk om de posterior langs analytische/theoretische weg (d.w.z. met behulp van integraalrekening) te vinden en dan maken we gebruik van simulaties (zie punt 3) Voorbeeld van gebruik van software om langs theoretische weg en op basis van een conjugate prior en normaal verdeelde likelihood het populatiegemiddelde van de normaal verdeelde posterior kansverdeling te vinden. > local({pkg <- select.list(sort(.packages(all.available = TRUE)),graphics=TRUE) + if(nchar(pkg)) library(pkg, character.only=true)}) Attaching package: Bolstad The following object(s) are masked _by_.globalenv : binodp Warning message: package Bolstad was built under R version > library(bolstad) > help(normnp) starting httpd help server... done de data: 100 aselecte trekkingen uit een normale verdeling met gemiddelde 68 en stand.dev. 4 > y=rnorm(100,68,4) > y [1]
30 [9] [17] [25] [33] [41] [49] [57] [65] [73] [81] [89] [97] > normnp(y,72,6,4,n.mu=200,plot=t) y=data 72=prior mean (gemiddelde van de normaal verdeelde prior) 6=prior standaarddeviatie 4=bekende standaarddeviatie n.mu= aantal mogelijke waarden van het prior gemiddelde Known standard deviation :4 Posterior mean : Posterior std. deviation : Prob. Quantile > 30
31 > Om integratie van de noemer te omzeilen wordt gebruik gemaakt van het Bayesiaanse evenredigheidsprincipe: het product van prior en likelihood is evenredig aan de posteriorkansen (zie o.a. mijn artikel over het driedeurenprobleem). Dit wordt aangegeven door: posterior prior likelihood Anders gezegd, het product van prior en likelihood levert geen posterior kansen op maar verschaft wel informatie over de relatieve posterior kansen, ofwel: informatie over de vorm van de posterior kansverdeling. Zo kan bijvoorbeeld nagegaan worden waar maxima en minima zich bevinden. (Om de kansen zelf te kunnen berekenen moeten we het product van prior en likelihood nog delen door een constante in de noemer. Door die constante (normalizing constant) wordt de som van alle 31
32 posterior kansen gelijk aan 1). Zie verder onder punt 3). ad 3) Monte Carlo simulaties en Markov Chain Monte Carlo simulaties Monte Carlo simulaties: kansproblemen oplossen door het schatten van een kansverdeling op basis van vele random (aselecte) trekkingen. (O.a. Bootstrap en permutatietoets; voor permutatietoets, zie ook De Bayesiaanse benadering, par. 2.4, p , zie ook de lijst van correcties bij mijn boek) Voorbeeld van een Monte Carlo simulatie: loting dienstplichtigen VS Vietnamoorlog 1970 (permutatietoets); elke dag van het jaar, incl. 29 februari, wordt in een capsule gestopt (dus 366 capsules), en daarna in een grote ton die grondig wordt geschud. De capsule die het eerst uit de ton wordt gehaald krijgt nr. 1 en de datum die in die capsule zat krijgt ook nr. 1 (bijv. 6 mei). En zo gaat het verder, dag nr. 2 is bijv. 22 november etc. Vervolgens worden alle dienstplichtigen die op dag nr. 1 geboren zijn opgeroepen om naar Vietnam te gaan, dan de dienstplichtigen die op 22 november geboren zijn enz. Omdat elke dag van het jaar een nummer heeft, heeft elke maand een som en een gemiddelde. na de loting kwamen de volgende cijfers naar voren: Gemiddelde lotingsnummers per maand: jan feb maart april mei juni juli aug sept okt nov dec Direct na de loting ontstond twijfel omtrent de eerlijkheid van deze procedure. We kunnen de volgende berekeningen maken: Algemeen gemiddelde (en ook verwachtingswaarde van het maandgemiddelde): 1 somrr na t 2 n 1 1 a tn n n 2 2 Kijken we naar de rangorde van hoog naar laag op basis van de maandgemiddelden dan zien we (beginnend met jan. op de 5e plaats, februari op de vierde plaats, maart op de eerste plaats etc.):
33 De verwachtingswaarde van het verschil tussen het gemiddelde van de eerste en van de tweede zes rangnummers is nul omdat het algemeen gemiddelde 1 somrr na t 2 n 1 1 a tn n n 2 2 voor beide helften zou moeten gelden. Hier volgt een eenvoudig model om m.b.v. Monte Carlo simulaties vast te stellen hoe (on)waarschijnlijk de lotingsuitkomst is: > vietnam=c(5,4,1,3,2,6,8,9,10,7,11,12) > loting=function(v)mean(v[1:6])-mean(v[7:12]) > loting(vietnam) [1] (= ) 2 2 > mc1970=c(replicate(100000,loting(sample(vietnam,replace=f)))) > frequencies=table(mc1970) > frequencies mc rel. freq. : 101 / = ± 01 Monte Carlo simulaties worden in de statistiek gebruikt om niet gebonden te zijn aan de theoretische aannames die voor de standaard significantietoetsen gelden. Resampling Methods Doel permutatietoets: schatten van de waarschijnlijkheid van een specifieke permutatie Doel Bootstrap (-> herkomst naam): schatten van de variatie (sampling error) ofwel de standaardfout (= standaarddeviatie van de steekproevenverdeling/sampling distribution) 33
34 Tweede voorbeeld van Resampling methods: (uit artikel Rob Flohr 2014, binnenkort te verschijnen in Stenden publicatiebundel) Bootstrap Het volgende voorbeeld 1 moge dit verduidelijken: Het betreft een experiment naar het omstanderseffect. Er zijn twee experimentele condities. In de ene zitten proefpersonen alleen, in de andere met een tweede (nep)proefpersoon. Nadat de proefleider de kamer heeft verlaten hoort de proefpersoon een enorme klap en veel herrie en geschreeuw op de gang. De afhankelijke variabele is nu of de proefpersoon komt kijken, en hoe lang het duurt voordat de proefpersoon komt kijken. De hypothese is dat proefpersonen die alleen zitten vaker en sneller reageren. We kijken naar de reactietijden van de proefpersonen die alleen zaten en de proefpersonen die gezelschap hadden, zie tabel 1 Tabel 1. Experiment omtrent het omstanderseffect. Tijd tot reactie (in seconden) Alleen (= 1) Gezelschap (= 2) 8,05 8,59 9,19 8,69 5,46 8,73 8,38 8,80 6,31 8,81 8,53 8,82 6,75 8,84 7,48 9,06 6,72 9,24 8,00 9,28 5,99 7,89 8,16 5,33 8,93 9,21 8,19 8,34 5,06 We zien dat het steekproefgemiddelde van groep 2 (8,886) inderdaad groter is dan dat van groep 1 (7,742) maar de statistisch relevante vraag luidt: is dat verschil (8,886-7,742 = 1,144) ook statistisch significant? Dat wil zeggen, stel dat er in werkelijkheid geen verschil in reactietijd tussen beide groepen bestaat (nulhypothese: populatiegemiddelde van groep 2 minus populatiegemiddelde van groep 1 is gelijk aan nul) en stel dat we dit experiment vele malen zouden herhalen, hoe uitzonderlijk is onze steekproefuitkomst van 1,144 dan? (preciezer: hoe groot is de kans op een uitkomst van 1,144 of meer?, dit is de zogeheten p-waarde of overschrijdingskans). Wanneer onze steekproefuitkomst uitzonderlijk genoemd mag worden (preciezer: wanneer de p-waarde kleiner of gelijk is aan het significantieniveau α, in veel gevallen 5% ), dan hebben we reden om de 1 Het voorbeeld is ontleend aan Van Peet, Namesnik & Hox (2012). 34
35 nulhypothese te verwerpen. 2 Toepassing van de t -toets voor het verschil tussen twee gemiddelden (in dit geval voor populaties met ongelijke varianties) geeft een zeer kleine p-waarde (ongeveer 002) en op grond daarvan verwerpen we de nulhypothese. De standaardfout is gelijk aan 0,314 (Van Peet e.a. 2012: 134). Ik kom uit op een standaardfout van 0.313, nl. via: x SE = > SE = (aan gezien de nulhypothese waarde nul is: er is geen verschil tussen beide groepen) Berekening m.b.v. R: alleen=c(8.05,9.19,5.46,8.38,6.31,8.53,6.75,7.48,6.72,8,5.99,7.89,8.16, 5.33,8.93,9.21,8.19,8.34,5.06) > gezelsch=c(8.59,8.69,8.73,8.8,8.81,8.82,8.84,9.06,9.24,9.28) > mean(alleen) [1] > mean(gezelsch) [1] > var.test(alleen,gezelsch) F test to compare two variances data: alleen and gezelsch F = , num df = 18, denom df = 9, p-value = 9.002e-06 alternative hypothesis: true ratio of variances is not equal to 1 95 percent confidence interval: sample estimates: ratio of variances > t.test(alleen,gezelsch,var.equal=f) Welch Two Sample t-test data: alleen and gezelsch t = , df = 204, p-value = alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: sample estimates: mean of x mean of y We gaan vervolgens de standaardfout schatten met behulp van de bootstrap. Daar is overigens ook alle reden toe aangezien er twijfel bestaat omtrent een van de aannamen voor de t -toets (namelijk normaal verdeelde populaties) (Van Peet e.a. 2012: 229). De uitvoering van de bootstrap m.b.v. R gaat als volgt: eerst zetten we de data in twee datavectoren, we noemen ze groep1 en groep2. Vervolgens laten we de computer, op basis van deze data, een groot aantal malen het verschil van beide 2 Er valt nog wel wat meer te zeggen over de interpretatie van een toetsing op significantie, en ook over het veelvuldig voorkomen van incorrecte interpretaties hiervan, maar in het bestek van dit artikel zal ik hier niet op ingaan. Voor meer informatie, zie bijvoorbeeld Flohr (2012), hoofdstuk 2. 35
36 steekproefgemiddelden uitrekenen en tenslotte bekijken we de hieruit resulterende verdeling van al die verschillen om onze conclusies te kunnen formuleren. groep1=c(8.05,9.19,5.46,8.38,6.31,8.53,6.75,7.48,6.72,8,5.99,7.89,8.16, 5.33,8.93,9.21,8.19,8.34,5.06) > groep2=c(8.59,8.69,8.73,8.8,8.81,8.82,8.84,9.06,9.24,9.28) > mean(groep1) [1] > mean(groep2) [1] > u=c(replicate(10000,mean(sample(groep2,replace=t))- mean(sample(groep1,replace=t)))) > sd(u) [1] We zien dat: a) de standaarddeviatie van de bootstrap-verdeling (0,3049) en de eerder langs theoretische weg berekende standaardfout (de standaarddeviatie van de steekproevenverdeling) (0,314 resp ) dicht bij elkaar liggen en b) dat de bootstrap-verdeling de normale verdeling sterk benadert, zie figuur 1 en figuur 2 Op basis hiervan kunnen we een 95% betrouwbaarheidsinterval als volgt bepalen: Figuur 1. Histogram van de bootstrapverdeling 36
37 Figuur 2. Normaal kwantieldiagram van de bootstrapverdeling > mean(groep2)-mean(groep1) [1] > (1.96* ) [1] > (1.96* ) [1] Het 95% betrouwbaarheidsinterval ( / ) bevat de nulhypothesewaarde van nul (er is geen verschil tussen de twee populatiegemiddelden) bij lange na niet zodat we besluiten de nulhypothese te verwerpen. Dit is het equivalent van de verwerping van de nulhypothese op basis van de zeer lage p- waarde die hierboven naar voren kwam. 3 Markov Chain Monte Carlo (MCMC) simulaties: Omdat directe trekking uit de 'target distribution' (de posterior kansverdeling) soms niet mogelijk is worden de trekkingen gekoppeld: elke trekking is (alleen) afhankelijk van de voorgaande trekking, dit levert een Markov keten op (vgl. de ' random walk' zoals de wandeling van de dronkaard). Voordeel: onder bepaalde voorwaarden convergeert een Markov keten naar een stabiele verdeling die de gewenste posterior verdeling benadert. Er bestaan verschillende algoritmen om zo'n MCMC-simulatie uit te voeren, wij zullen de binnen de Bayesiaanse statistiek dominante Gibbs sampler gebruiken (is een variant op het zogeheten Metropolis- Hastings aloritme). De Gibbs sampler (vandaar de benaming BUGS: Bayesian Inference Using the Gibbs Sampler) kan gebruikt worden wanneer de posterior verdeling volledig bepaald wordt door de betreffende conditionele kansverdelingen. 3 Van Peet c.s. komen op basis van de bootstrap-module in SPSS tot de volgende uitkomsten: geschatte standaardfout: en 95% bootstrap-betrouwbaarheidsinterval: / (Van Peet, Namesnik & Hox 2012: 230). Overigens voert de bootstrap-module in SPSS de bootstrap-procedure niet direct uit (zoals in R) maar wordt een groot aantal malen de t-test uitgevoerd en worden de aldus geproduceerde t-waarden gebruikt voor de empirische bootstrap-verdeling. 37
38 We zullen tijdens deze cursus niet verder op de theoretische aspecten van de Gibbs sampler ingaan. Er zijn verschillende softwaremogelijkheden om MCMC-simulaties uit te voeren, wij zullen ons beperken tot R-packages en het programma WinBUGS (zijn momenteel beide op de computers van de NHL geïnstalleerd). VOORBEELDEN VAN TOEPASSINGEN VAN MCMC-pack: A) Normaal verdeelde prior en normaal verdeelde data (het voorbeeld onder punt 2) hierboven, p. 5-7) > local({pkg <- select.list(sort(.packages(all.available = TRUE)),graphics=TRUE) + if(nchar(pkg)) library(pkg, character.only=true)}) Loading required package: coda Loading required package: lattice Loading required package: MASS ## ## Markov Chain Monte Carlo Package (MCMCpack) ## Copyright (C) Andrew D. Martin, Kevin M. Quinn, and Jong Hee Park ## ## Support provided by the U.S. National Science Foundation ## (Grants SES and SES ) ## Warning messages: 1: package MCMCpack was built under R version : package coda was built under R version : package lattice was built under R version > library(mcmcpack) > help(mcnormalnormal) starting httpd help server... done de data: 100 aselecte trekkingen uit een normale verdeling met gemiddelde 68 en stand.dev. 4 > y=rnorm(100,68,4) > y [1] [9] [17] [25] [33] [41] [49] [57] [65]
39 [73] [81] [89] [97] > MCnormalnormal(y,16,72,36,5000) y = de data 16 = de (bekende) variantie van de data y, dus 4^2=16 72 = de prior mean (het gemiddelde van de normaal verdeelde prior) 36 = de variantie van de normaal verdeelde prior 5000 = het aantal MCMC-trekkingen Markov Chain Monte Carlo (MCMC) output: Start = 1 End = 5000 Thinning interval = 1 mu [1,] [2,] [3,] [4,] [5,] [6,] [7,] [8,] [9,] [10,] [11,] [12,] [13,] [14,] [15,] [16,] [17,] [18,] [19,] [20,] [4994,] [4995,] [4996,] [4997,] [4998,] [4999,] [5000,] attr(,"title") [1] "MCnormalnormal Posterior Sample" > summary(mcnormalnormal(y,16,72,36,5000)) Iterations = 1:5000 Thinning interval = 1 39
40 Number of chains = 1 Sample size per chain = Empirical mean and standard deviation for each variable, plus standard error of the mean: Mean SD Naive SE Time-series SE Quantiles for each variable: 2.5% 25% 50% 75% 97.5% B) Voorbeeld Huiswerkopgave over Harry Potter m.b.v. MCMC-simulaties: Met MCMCpack: > local({pkg <- select.list(sort(.packages(all.available = TRUE)),graphics=TRUE) + if(nchar(pkg)) library(pkg, character.only=true)}) Loading required package: coda Loading required package: lattice Loading required package: MASS ## ## Markov Chain Monte Carlo Package (MCMCpack) ## Copyright (C) Andrew D. Martin, Kevin M. Quinn, and Jong Hee Park ## ## Support provided by the U.S. National Science Foundation ## (Grants SES and SES ) ## Warning messages: 1: package MCMCpack was built under R version : package coda was built under R version : package lattice was built under R version > library(mcmcpack) > harrypotter=mcbinomialbeta(y=400,n=1000,alpha=1,beta=1,mc=10000) > summary(harrypotter) Iterations = 1:10000 Thinning interval = 1 Number of chains = 1 Sample size per chain = Empirical mean and standard deviation for each variable, plus standard error of the mean: Mean SD Naive SE Time-series SE Quantiles for each variable: 2.5% 25% 50% 75% 97.5%
Omdat we de werkelijkheid altijd moeten vereenvoudigen ('stileren') hebben we te maken met het modelbegrip.
 hebben we te maken met het modelbegrip.") Vooraf: waar gaat het vak statistiek eigenlijk over, wat houdt het in, wat voor soort kennis over de werkelijkheid levert het op? (Dat laatste wordt ook wel aangeduid als de epistemologische basis van
Vooraf: waar gaat het vak statistiek eigenlijk over, wat houdt het in, wat voor soort kennis over de werkelijkheid levert het op? (Dat laatste wordt ook wel aangeduid als de epistemologische basis van
Vandaag. Onderzoeksmethoden: Statistiek 3. Recap 2. Recap 1. Recap Centrale limietstelling T-verdeling Toetsen van hypotheses
 Vandaag Onderzoeksmethoden: Statistiek 3 Peter de Waal (gebaseerd op slides Peter de Waal, Marjan van den Akker) Departement Informatica Beta-faculteit, Universiteit Utrecht Recap Centrale limietstelling
Vandaag Onderzoeksmethoden: Statistiek 3 Peter de Waal (gebaseerd op slides Peter de Waal, Marjan van den Akker) Departement Informatica Beta-faculteit, Universiteit Utrecht Recap Centrale limietstelling
Hoofdstuk 3 Statistiek: het toetsen
 Hoofdstuk 3 Statistiek: het toetsen 3.1 Schatten: Er moet een verbinding worden gelegd tussen de steekproefgrootheden en populatieparameters, willen we op basis van de een iets kunnen zeggen over de ander.
Hoofdstuk 3 Statistiek: het toetsen 3.1 Schatten: Er moet een verbinding worden gelegd tussen de steekproefgrootheden en populatieparameters, willen we op basis van de een iets kunnen zeggen over de ander.
Hoofdstuk 5 Een populatie: parametrische toetsen
 Hoofdstuk 5 Een populatie: parametrische toetsen 5.1 Gemiddelde, variantie, standaardafwijking: De variantie is als het ware de gemiddelde gekwadrateerde afwijking van het gemiddelde. Hoe groter de variantie
Hoofdstuk 5 Een populatie: parametrische toetsen 5.1 Gemiddelde, variantie, standaardafwijking: De variantie is als het ware de gemiddelde gekwadrateerde afwijking van het gemiddelde. Hoe groter de variantie
Toetsende Statistiek, Week 2. Van Steekproef naar Populatie: De Steekproevenverdeling
 Toetsende Statistiek, Week 2. Van Steekproef naar Populatie: De Steekproevenverdeling Moore, McCabe & Craig: 3.3 Toward Statistical Inference From Probability to Inference 5.1 Sampling Distributions for
Toetsende Statistiek, Week 2. Van Steekproef naar Populatie: De Steekproevenverdeling Moore, McCabe & Craig: 3.3 Toward Statistical Inference From Probability to Inference 5.1 Sampling Distributions for
toetsende statistiek deze week: wat hebben we al geleerd? Frank Busing, Universiteit Leiden
 toetsende statistiek week 1: kansen en random variabelen week 2: de steekproevenverdeling week 3: schatten en toetsen: de z-toets week 4: het toetsen van gemiddelden: de t-toets Moore, McCabe, and Craig.
toetsende statistiek week 1: kansen en random variabelen week 2: de steekproevenverdeling week 3: schatten en toetsen: de z-toets week 4: het toetsen van gemiddelden: de t-toets Moore, McCabe, and Craig.
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor T (2S070) op vrijdag 8 oktober 1999, uur De u
 op vrijdag 8 oktober 1999, uur De u") TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor T (2S070) op vrijdag 8 oktober 1999, 14.00-17.00 uur De uitwerkingen van de opgaven dienen duidelijk geformuleerd
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor T (2S070) op vrijdag 8 oktober 1999, 14.00-17.00 uur De uitwerkingen van de opgaven dienen duidelijk geformuleerd
Examen G0N34 Statistiek
 Naam: Richting: Examen G0N34 Statistiek 8 september 2010 Enkele richtlijnen : Wie de vragen aanneemt en bekijkt, moet minstens 1 uur blijven zitten. Je mag gebruik maken van een rekenmachine, het formularium
Naam: Richting: Examen G0N34 Statistiek 8 september 2010 Enkele richtlijnen : Wie de vragen aanneemt en bekijkt, moet minstens 1 uur blijven zitten. Je mag gebruik maken van een rekenmachine, het formularium
introductie Wilcoxon s rank sum toets Wilcoxon s signed rank toets introductie Wilcoxon s rank sum toets Wilcoxon s signed rank toets
 toetsende statistiek week 1: kansen en random variabelen week : de steekproevenverdeling week 3: schatten en toetsen: de z-toets week : het toetsen van gemiddelden: de t-toets week 5: het toetsen van varianties:
toetsende statistiek week 1: kansen en random variabelen week : de steekproevenverdeling week 3: schatten en toetsen: de z-toets week : het toetsen van gemiddelden: de t-toets week 5: het toetsen van varianties:
 Vertaling van enkele termen uit de kansrekening en statistiek alternative hypothesis alternatieve hypothese approximate methods benaderende methoden asymptotic variance asymptotische variantie asymptotically
Vertaling van enkele termen uit de kansrekening en statistiek alternative hypothesis alternatieve hypothese approximate methods benaderende methoden asymptotic variance asymptotische variantie asymptotically
HOOFDSTUK 6: INTRODUCTIE IN STATISTISCHE GEVOLGTREKKINGEN
 HOOFDSTUK 6: INTRODUCTIE IN STATISTISCHE GEVOLGTREKKINGEN Inleiding Statistische gevolgtrekkingen (statistical inference) gaan over het trekken van conclusies over een populatie op basis van steekproefdata.
HOOFDSTUK 6: INTRODUCTIE IN STATISTISCHE GEVOLGTREKKINGEN Inleiding Statistische gevolgtrekkingen (statistical inference) gaan over het trekken van conclusies over een populatie op basis van steekproefdata.
Meervoudige ANOVA Onderzoeksvraag Voorwaarden
 Er is onderzoek gedaan naar rouw na het overlijden van een huisdier (contactpersoon: Karolijne van der Houwen (Klinische Psychologie)). Mensen konden op internet een vragenlijst invullen. Daarin werd gevraagd
Er is onderzoek gedaan naar rouw na het overlijden van een huisdier (contactpersoon: Karolijne van der Houwen (Klinische Psychologie)). Mensen konden op internet een vragenlijst invullen. Daarin werd gevraagd
Data analyse Inleiding statistiek
 Data analyse Inleiding statistiek 1 Terugblik - Inductieve statistiek Afleiden van eigenschappen van een populatie op basis van een beperkt aantal metingen (steekproef) Kennis gemaakt met kans & kansverdelingen»
Data analyse Inleiding statistiek 1 Terugblik - Inductieve statistiek Afleiden van eigenschappen van een populatie op basis van een beperkt aantal metingen (steekproef) Kennis gemaakt met kans & kansverdelingen»
Voorbeeldtentamen Statistiek voor Psychologie
 Voorbeeldtentamen Statistiek voor Psychologie 1) Vul de volgende uitspraak aan, zodat er een juiste bewering ontstaat: De verdeling van een variabele geeft een opsomming van de categorieën en geeft daarbij
Voorbeeldtentamen Statistiek voor Psychologie 1) Vul de volgende uitspraak aan, zodat er een juiste bewering ontstaat: De verdeling van een variabele geeft een opsomming van de categorieën en geeft daarbij
We berekenen nog de effectgrootte aan de hand van formule 4.2 en rapporteren:
 INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 4 1. Toets met behulp van SPSS de hypothese van Evelien in verband met de baardlengte van metalfans. Ga na of je dezelfde conclusies
INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 4 1. Toets met behulp van SPSS de hypothese van Evelien in verband met de baardlengte van metalfans. Ga na of je dezelfde conclusies
Cursus TEO: Theorie en Empirisch Onderzoek. Practicum 2: Herhaling BIS 11 februari 2015
 Cursus TEO: Theorie en Empirisch Onderzoek Practicum 2: Herhaling BIS 11 februari 2015 Centrale tendentie Centrale tendentie wordt meestal afgemeten aan twee maten: Mediaan: de middelste waarneming, 50%
Cursus TEO: Theorie en Empirisch Onderzoek Practicum 2: Herhaling BIS 11 februari 2015 Centrale tendentie Centrale tendentie wordt meestal afgemeten aan twee maten: Mediaan: de middelste waarneming, 50%
TECHNISCHE UNIVERSITEIT EINDHOVEN
 TECHNISCHE UNIVERSITEIT EINDHOVEN Tentamen Biostatistiek voor BMT (2S390) op 17-11-2003 U mag alleen gebruik maken van een onbeschreven Statistisch Compendium (dikt. nr. 2218) en van een zakrekenmachine.
TECHNISCHE UNIVERSITEIT EINDHOVEN Tentamen Biostatistiek voor BMT (2S390) op 17-11-2003 U mag alleen gebruik maken van een onbeschreven Statistisch Compendium (dikt. nr. 2218) en van een zakrekenmachine.
Enkelvoudige ANOVA Onderzoeksvraag Voorwaarden
 Er is onderzoek gedaan naar rouw na het overlijden van een huisdier (contactpersoon: Karolijne van der Houwen (Klinische Psychologie)). Mensen konden op internet een vragenlijst invullen. Daarin werd gevraagd
Er is onderzoek gedaan naar rouw na het overlijden van een huisdier (contactpersoon: Karolijne van der Houwen (Klinische Psychologie)). Mensen konden op internet een vragenlijst invullen. Daarin werd gevraagd
9. Lineaire Regressie en Correlatie
 9. Lineaire Regressie en Correlatie Lineaire verbanden In dit hoofdstuk worden methoden gepresenteerd waarmee je kwantitatieve respons variabelen (afhankelijk) en verklarende variabelen (onafhankelijk)
9. Lineaire Regressie en Correlatie Lineaire verbanden In dit hoofdstuk worden methoden gepresenteerd waarmee je kwantitatieve respons variabelen (afhankelijk) en verklarende variabelen (onafhankelijk)
Hoofdstuk 7: Statistische gevolgtrekkingen voor distributies
 Hoofdstuk 7: Statistische gevolgtrekkingen voor distributies 7.1 Het gemiddelde van een populatie Standaarddeviatie van de populatie en de steekproef In het vorige deel is bij de significantietoets uitgegaan
Hoofdstuk 7: Statistische gevolgtrekkingen voor distributies 7.1 Het gemiddelde van een populatie Standaarddeviatie van de populatie en de steekproef In het vorige deel is bij de significantietoets uitgegaan
Kansrekening en Statistiek
 Kansrekening en Statistiek College 12 Donderdag 21 Oktober 1 / 38 2 Statistiek Indeling: Stochast en populatie Experimenten herhalen Wet van de Grote Getallen Centrale Limietstelling 2 / 38 Deductieve
Kansrekening en Statistiek College 12 Donderdag 21 Oktober 1 / 38 2 Statistiek Indeling: Stochast en populatie Experimenten herhalen Wet van de Grote Getallen Centrale Limietstelling 2 / 38 Deductieve
werkcollege 6 - D&P9: Estimation Using a Single Sample
 cursus 9 mei 2012 werkcollege 6 - D&P9: Estimation Using a Single Sample van frequentie naar dichtheid we bepalen frequenties van meetwaarden plot in histogram delen door totaal aantal meetwaarden > fracties
cursus 9 mei 2012 werkcollege 6 - D&P9: Estimation Using a Single Sample van frequentie naar dichtheid we bepalen frequenties van meetwaarden plot in histogram delen door totaal aantal meetwaarden > fracties
HOOFDSTUK 7: STATISTISCHE GEVOLGTREKKINGEN VOOR DISTRIBUTIES
 HOOFDSTUK 7: STATISTISCHE GEVOLGTREKKINGEN VOOR DISTRIBUTIES 7.1 Het gemiddelde van een populatie Standaarddeviatie van de populatie en de steekproef In het vorige deel is bij de significantietoets uitgegaan
HOOFDSTUK 7: STATISTISCHE GEVOLGTREKKINGEN VOOR DISTRIBUTIES 7.1 Het gemiddelde van een populatie Standaarddeviatie van de populatie en de steekproef In het vorige deel is bij de significantietoets uitgegaan
Antwoordvel Versie A
 Antwoordvel Versie A Interimtoets Toegepaste Biostatistiek 13 december 013 Naam:... Studentnummer:...... Antwoorden: Vraag Antwoord Antwoord Antwoord Vraag Vraag A B C D A B C D A B C D 1 10 19 11 0 3
Antwoordvel Versie A Interimtoets Toegepaste Biostatistiek 13 december 013 Naam:... Studentnummer:...... Antwoorden: Vraag Antwoord Antwoord Antwoord Vraag Vraag A B C D A B C D A B C D 1 10 19 11 0 3
Toetsende Statistiek Week 3. Statistische Betrouwbaarheid & Significantie Toetsing
 Toetsende Statistiek Week 3. Statistische Betrouwbaarheid & Significantie Toetsing M, M & C, Chapter 6, Introduction to Inference 6.1 Estimating with Confidence 6.2 Tests of Significance 6.3 Use and Abuse
Toetsende Statistiek Week 3. Statistische Betrouwbaarheid & Significantie Toetsing M, M & C, Chapter 6, Introduction to Inference 6.1 Estimating with Confidence 6.2 Tests of Significance 6.3 Use and Abuse
Hierbij is het steekproefgemiddelde x_gemiddeld= en de steekproefstandaardafwijking
 Opdracht 9a ----------- t-procedures voor een enkelvoudige steekproef Voor de meting van de leesvaardigheid van kinderen wordt als toets de Degree of Reading Power (DRP) gebruikt. In een onderzoek onder
Opdracht 9a ----------- t-procedures voor een enkelvoudige steekproef Voor de meting van de leesvaardigheid van kinderen wordt als toets de Degree of Reading Power (DRP) gebruikt. In een onderzoek onder
Hoofdstuk 6 Twee populaties: parametrische toetsen
 Hoofdstuk 6 Twee populaties: parametrische toetsen 6.1 De t-toets voor het verschil tussen twee gemiddelden: In veel onderzoekssituaties zijn we vooral in de verschillen tussen twee populaties geïnteresseerd.
Hoofdstuk 6 Twee populaties: parametrische toetsen 6.1 De t-toets voor het verschil tussen twee gemiddelden: In veel onderzoekssituaties zijn we vooral in de verschillen tussen twee populaties geïnteresseerd.
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica. Tentamen Statistiek 2 voor TeMa (2S195) op dinsdag , uur.
 op dinsdag , uur.") TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor TeMa (S95) op dinsdag 3-03-00, 9- uur. Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor TeMa (S95) op dinsdag 3-03-00, 9- uur. Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en
Kansrekening en Statistiek
 Kansrekening en Statistiek College 12 Vrijdag 16 Oktober 1 / 38 2 Statistiek Indeling vandaag: Normale verdeling Wet van de Grote Getallen Centrale Limietstelling Deductieve statistiek Hypothese toetsen
Kansrekening en Statistiek College 12 Vrijdag 16 Oktober 1 / 38 2 Statistiek Indeling vandaag: Normale verdeling Wet van de Grote Getallen Centrale Limietstelling Deductieve statistiek Hypothese toetsen
introductie populatie- steekproef- steekproevenverdeling pauze parameters aannames ten slotte
 toetsende statistiek week 1: kansen en random variabelen week 2: de steekproevenverdeling Moore, McCabe, and Craig. Introduction to the Practice of Statistics Chapter 5: Sampling Distributions 5.1: The
toetsende statistiek week 1: kansen en random variabelen week 2: de steekproevenverdeling Moore, McCabe, and Craig. Introduction to the Practice of Statistics Chapter 5: Sampling Distributions 5.1: The
ALLEDAAGSE DINGEN VANUIT STATISTISCH PERSPECTIEF. Hoe statistiek onze kijk op wetenschap, mens en wereld veranderd heeft. College 3 10 november 2016
 ALLEDAAGSE DINGEN VANUIT STATISTISCH PERSPECTIEF Hoe statistiek onze kijk op wetenschap, mens en wereld veranderd heeft College 3 10 november 2016 VIER HOOFDONDERWERPEN (III) Statistiek: wijze van redeneren
ALLEDAAGSE DINGEN VANUIT STATISTISCH PERSPECTIEF Hoe statistiek onze kijk op wetenschap, mens en wereld veranderd heeft College 3 10 november 2016 VIER HOOFDONDERWERPEN (III) Statistiek: wijze van redeneren
Hoofdstuk 5: Steekproevendistributies
 Hoofdstuk 5: Steekproevendistributies Inleiding Statistische gevolgtrekkingen worden gebruikt om conclusies over een populatie of proces te trekken op basis van data. Deze data wordt samengevat door middel
Hoofdstuk 5: Steekproevendistributies Inleiding Statistische gevolgtrekkingen worden gebruikt om conclusies over een populatie of proces te trekken op basis van data. Deze data wordt samengevat door middel
Toetsende Statistiek Week 5. De F-toets & Onderscheidend Vermogen
 M, M & C 7.3 Optional Topics in Comparing Distributions: F-toets 6.4 Power & Inference as a Decision 7.1 The power of the t-test 7.3 The power of the sample t- Toetsende Statistiek Week 5. De F-toets &
M, M & C 7.3 Optional Topics in Comparing Distributions: F-toets 6.4 Power & Inference as a Decision 7.1 The power of the t-test 7.3 The power of the sample t- Toetsende Statistiek Week 5. De F-toets &
Vandaag. Onderzoeksmethoden: Statistiek 2. Basisbegrippen. Theoretische kansverdelingen
 Vandaag Onderzoeksmethoden: Statistiek 2 Peter de Waal (gebaseerd op slides Peter de Waal, Marjan van den Akker) Departement Informatica Beta-faculteit, Universiteit Utrecht Theoretische kansverdelingen
Vandaag Onderzoeksmethoden: Statistiek 2 Peter de Waal (gebaseerd op slides Peter de Waal, Marjan van den Akker) Departement Informatica Beta-faculteit, Universiteit Utrecht Theoretische kansverdelingen
Hoofdstuk 12: Eenweg ANOVA
 Hoofdstuk 12: Eenweg ANOVA 12.1 Eenweg analyse van variantie Eenweg en tweeweg ANOVA Wanneer we verschillende populaties of behandelingen met elkaar vergelijken, dan zal er binnen de data altijd sprake
Hoofdstuk 12: Eenweg ANOVA 12.1 Eenweg analyse van variantie Eenweg en tweeweg ANOVA Wanneer we verschillende populaties of behandelingen met elkaar vergelijken, dan zal er binnen de data altijd sprake
werkcollege 6 - D&P10: Hypothesis testing using a single sample
 cursus huiswerk opgaven Ch.9: 1, 8, 11, 12, 20, 26, 36, 37, 71 werkcollege 6 - D&P10: Hypothesis testing using a single sample Activities 9.3 en 9.4 van schatting naar toetsing vorige bijeenkomst: populatie-kenmerk
cursus huiswerk opgaven Ch.9: 1, 8, 11, 12, 20, 26, 36, 37, 71 werkcollege 6 - D&P10: Hypothesis testing using a single sample Activities 9.3 en 9.4 van schatting naar toetsing vorige bijeenkomst: populatie-kenmerk
mlw stroom 2.2 Biostatistiek en Epidemiologie College 9: Herhaalde metingen (2) Syllabus Afhankelijke Data Hoofdstuk 4, 5.1, 5.2
 Syllabus Afhankelijke Data Hoofdstuk 4, 5.1, 5.2") mlw stroom 2.2 Biostatistiek en Epidemiologie College 9: Herhaalde metingen (2) Syllabus Afhankelijke Data Hoofdstuk 4, 5.1, 5.2 Bjorn Winkens Methodologie en Statistiek Universiteit Maastricht 21 maart
mlw stroom 2.2 Biostatistiek en Epidemiologie College 9: Herhaalde metingen (2) Syllabus Afhankelijke Data Hoofdstuk 4, 5.1, 5.2 Bjorn Winkens Methodologie en Statistiek Universiteit Maastricht 21 maart
Kansrekening en Statistiek
 Kansrekening en Statistiek College 8 Donderdag 13 Oktober 1 / 23 2 Statistiek Vandaag: Stochast en populatie Experimenten herhalen Wet van de Grote Getallen Centrale Limietstelling 2 / 23 Stochast en populatie
Kansrekening en Statistiek College 8 Donderdag 13 Oktober 1 / 23 2 Statistiek Vandaag: Stochast en populatie Experimenten herhalen Wet van de Grote Getallen Centrale Limietstelling 2 / 23 Stochast en populatie
Toetsen van Hypothesen. Het vaststellen van de hypothese
 Toetsen van Hypothesen Wisnet-hbo update maart 2008 1. en Het vaststellen van de hypothese De nulhypothese en de Alternatieve hypothese. Het gaat in deze paragraaf puur alleen om de formulering. Er wordt
Toetsen van Hypothesen Wisnet-hbo update maart 2008 1. en Het vaststellen van de hypothese De nulhypothese en de Alternatieve hypothese. Het gaat in deze paragraaf puur alleen om de formulering. Er wordt
. Dan geldt P(B) = a. 1 4. d. 3 8
 = a. 1 4. d. 3 8") Tentamen Statistische methoden 4052STAMEY juli 203, 9:00 2:00 Studienummers: Vult u alstublieft op het meerkeuzevragenformulier uw Delftse studienummer in (tbv automatische verwerking); en op het open
Tentamen Statistische methoden 4052STAMEY juli 203, 9:00 2:00 Studienummers: Vult u alstublieft op het meerkeuzevragenformulier uw Delftse studienummer in (tbv automatische verwerking); en op het open
Opgave 1: (zowel 2DM40 als 2S390)
") TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Biostatistiek voor BMT (DM4 en S39) op donderdag, 4.-7. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Biostatistiek voor BMT (DM4 en S39) op donderdag, 4.-7. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
Hoofdstuk 8 Het toetsen van nonparametrische variabelen
 Hoofdstuk 8 Het toetsen van nonparametrische variabelen 8.1 Non-parametrische toetsen: deze toetsen zijn toetsen waarbij de aannamen van normaliteit en intervalniveau niet nodig zijn. De aannamen zijn
Hoofdstuk 8 Het toetsen van nonparametrische variabelen 8.1 Non-parametrische toetsen: deze toetsen zijn toetsen waarbij de aannamen van normaliteit en intervalniveau niet nodig zijn. De aannamen zijn
Populaties beschrijven met kansmodellen
 Populaties beschrijven met kansmodellen Prof. dr. Herman Callaert Deze tekst probeert, met voorbeelden, inzicht te geven in de manier waarop je in de statistiek populaties bestudeert. Dat doe je met kansmodellen.
Populaties beschrijven met kansmodellen Prof. dr. Herman Callaert Deze tekst probeert, met voorbeelden, inzicht te geven in de manier waarop je in de statistiek populaties bestudeert. Dat doe je met kansmodellen.
11. Multipele Regressie en Correlatie
 11. Multipele Regressie en Correlatie Meervoudig regressie model Nu gaan we kijken naar een relatie tussen een responsvariabele en meerdere verklarende variabelen. Een bivariate regressielijn ziet er in
11. Multipele Regressie en Correlatie Meervoudig regressie model Nu gaan we kijken naar een relatie tussen een responsvariabele en meerdere verklarende variabelen. Een bivariate regressielijn ziet er in
Kruis per vraag slechts één vakje aan op het antwoordformulier.
 Toets Stroom 1.2 Methoden en Statistiek tul, MLW 7 april 2006 Deze toets bestaat uit 25 vierkeuzevragen. Kruis per vraag slechts één vakje aan op het antwoordformulier. Vraag goed beantwoord dan punt voor
Toets Stroom 1.2 Methoden en Statistiek tul, MLW 7 april 2006 Deze toets bestaat uit 25 vierkeuzevragen. Kruis per vraag slechts één vakje aan op het antwoordformulier. Vraag goed beantwoord dan punt voor
Zowel correlatie als regressie meten statistische samenhang Correlatie: geen oorzakelijk verband verondersteld: X Y
 1 Regressie analyse Zowel correlatie als regressie meten statistische samenhang Correlatie: geen oorzakelijk verband verondersteld: X Y Regressie: wel een oorzakelijk verband verondersteld: X Y Voorbeeld
1 Regressie analyse Zowel correlatie als regressie meten statistische samenhang Correlatie: geen oorzakelijk verband verondersteld: X Y Regressie: wel een oorzakelijk verband verondersteld: X Y Voorbeeld
ANOVA in SPSS. Hugo Quené. opleiding Taalwetenschap Universiteit Utrecht Trans 10, 3512 JK Utrecht 12 maart 2003
 ANOVA in SPSS Hugo Quené hugo.quene@let.uu.nl opleiding Taalwetenschap Universiteit Utrecht Trans 10, 3512 JK Utrecht 12 maart 2003 1 vooraf In dit voorbeeld gebruik ik fictieve gegevens, ontleend aan
ANOVA in SPSS Hugo Quené hugo.quene@let.uu.nl opleiding Taalwetenschap Universiteit Utrecht Trans 10, 3512 JK Utrecht 12 maart 2003 1 vooraf In dit voorbeeld gebruik ik fictieve gegevens, ontleend aan
Kansrekening en Statistiek
 Kansrekening en Statistiek College 14 Donderdag 28 Oktober 1 / 37 2 Statistiek Indeling: Hypothese toetsen Schatten 2 / 37 Vragen 61 Amerikanen werd gevraagd hoeveel % van de tijd zij liegen. Het gevonden
Kansrekening en Statistiek College 14 Donderdag 28 Oktober 1 / 37 2 Statistiek Indeling: Hypothese toetsen Schatten 2 / 37 Vragen 61 Amerikanen werd gevraagd hoeveel % van de tijd zij liegen. Het gevonden
c Voorbeeldvragen, Methoden & Technieken, Universiteit Leiden TS: versie 1 1 van 6
 c Voorbeeldvragen, Methoden & Technieken, Universiteit Leiden TS: versie 1 1 van 6 1. Iemand kiest geblinddoekt 4 paaseitjes uit een mand met oneindig veel paaseitjes. De helft is melkchocolade, de andere
c Voorbeeldvragen, Methoden & Technieken, Universiteit Leiden TS: versie 1 1 van 6 1. Iemand kiest geblinddoekt 4 paaseitjes uit een mand met oneindig veel paaseitjes. De helft is melkchocolade, de andere
Simulaties een revolutie in de didactiek van de statistiek
 Simulaties een revolutie in Simulaties de didactiek van de statistiek een revolutie in de didactiek van de statistiek Carel van de Giessen NVvWL november 2015 Van Althuis German Tank problem 1? German
Simulaties een revolutie in Simulaties de didactiek van de statistiek een revolutie in de didactiek van de statistiek Carel van de Giessen NVvWL november 2015 Van Althuis German Tank problem 1? German
toetskeuze schema verschillen in gemiddelden
 toetsende statistiek week 1: kansen en random variabelen week 2: de steekproevenverdeling week 3: schatten en toetsen: de z-toets week 4: het toetsen van gemiddelden: de t-toets week 5: het toetsen van
toetsende statistiek week 1: kansen en random variabelen week 2: de steekproevenverdeling week 3: schatten en toetsen: de z-toets week 4: het toetsen van gemiddelden: de t-toets week 5: het toetsen van
Voer de gegevens in in een tabel. Definieer de drie kolommen van de tabel en kies als kolomnamen groep, vooraf en achteraf.
 Opdracht 10a ------------ t-procedures voor gekoppelde paren t-procedures voor twee onafhankelijke steekproeven samengestelde t-procedures voor twee onafhankelijke steekproeven Twee groepen van 10 leraren
Opdracht 10a ------------ t-procedures voor gekoppelde paren t-procedures voor twee onafhankelijke steekproeven samengestelde t-procedures voor twee onafhankelijke steekproeven Twee groepen van 10 leraren
INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 5
 INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 5 1. De onderzoekers van een preventiedienst vermoeden dat werknemers in een bedrijf zonder liften fitter zijn dan werknemers
INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 5 1. De onderzoekers van een preventiedienst vermoeden dat werknemers in een bedrijf zonder liften fitter zijn dan werknemers
G0N11C Statistiek & data-analyse Project tweede zittijd
 G0N11C Statistiek & data-analyse Project tweede zittijd 2014-2015 Naam : Raimondi Michael Studierichting : Biologie Gebruik deze Word-template om een antwoord te geven op onderstaande onderzoeksvragen.
G0N11C Statistiek & data-analyse Project tweede zittijd 2014-2015 Naam : Raimondi Michael Studierichting : Biologie Gebruik deze Word-template om een antwoord te geven op onderstaande onderzoeksvragen.
Statistiek voor Natuurkunde Opgavenserie 1: Kansrekening
 Statistiek voor Natuurkunde Opgavenserie 1: Kansrekening Inleveren: 12 januari 2011, VOOR het college Afspraken Serie 1 mag gemaakt en ingeleverd worden in tweetallen. Schrijf duidelijk je naam, e-mail
Statistiek voor Natuurkunde Opgavenserie 1: Kansrekening Inleveren: 12 januari 2011, VOOR het college Afspraken Serie 1 mag gemaakt en ingeleverd worden in tweetallen. Schrijf duidelijk je naam, e-mail
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica. Tentamen Statistiek (2DD14) op vrijdag 17 maart 2006, 9.00-12.00 uur.
 op vrijdag 17 maart 2006, 9.00-12.00 uur.") TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek DD14) op vrijdag 17 maart 006, 9.00-1.00 uur. UITWERKINGEN 1. Methoden om schatters te vinden a) De aannemelijkheidsfunctie
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek DD14) op vrijdag 17 maart 006, 9.00-1.00 uur. UITWERKINGEN 1. Methoden om schatters te vinden a) De aannemelijkheidsfunctie
Oefenvragen bij Statistics for Business and Economics van Newbold
 Oefenvragen bij Statistics for Business and Economics van Newbold Hoofdstuk 1 1. Wat is het verschil tussen populatie en sample? De populatie is de complete set van items waar de onderzoeker in geïnteresseerd
Oefenvragen bij Statistics for Business and Economics van Newbold Hoofdstuk 1 1. Wat is het verschil tussen populatie en sample? De populatie is de complete set van items waar de onderzoeker in geïnteresseerd
2DM71: Eindtoets Biostatistiek, op dinsdag 20 Januari 2015, 13.30-16.30
 Faculteit der Wiskunde en Informatica 2DM71: Eindtoets Biostatistiek, op dinsdag 20 Januari 2015, 13.30-16.30 Opgave 1: (5 x 6 = 30 punten) (Bij deze opgave is gebruik van resultaten uit bijlage 1 noodzakelijk)
Faculteit der Wiskunde en Informatica 2DM71: Eindtoets Biostatistiek, op dinsdag 20 Januari 2015, 13.30-16.30 Opgave 1: (5 x 6 = 30 punten) (Bij deze opgave is gebruik van resultaten uit bijlage 1 noodzakelijk)
Wiskunde B - Tentamen 2
 Wiskunde B - Tentamen Tentamen van Wiskunde B voor CiT (57) Donderdag 4 april 005 van 900 tot 00 uur Dit tentamen bestaat uit 8 opgaven, 3 tabellen en formulebladen Vermeld ook je studentnummer op je werk
Wiskunde B - Tentamen Tentamen van Wiskunde B voor CiT (57) Donderdag 4 april 005 van 900 tot 00 uur Dit tentamen bestaat uit 8 opgaven, 3 tabellen en formulebladen Vermeld ook je studentnummer op je werk
1. Statistiek gebruiken 1
 Hoofdstuk 0 Inhoudsopgave 1. Statistiek gebruiken 1 2. Gegevens beschrijven 3 2.1 Verschillende soorten gegevens......................................... 3 2.2 Staafdiagrammen en histogrammen....................................
Hoofdstuk 0 Inhoudsopgave 1. Statistiek gebruiken 1 2. Gegevens beschrijven 3 2.1 Verschillende soorten gegevens......................................... 3 2.2 Staafdiagrammen en histogrammen....................................
Kansrekening en statistiek wi2105in deel 2 16 april 2010, uur
 Kansrekening en statistiek wi205in deel 2 6 april 200, 4.00 6.00 uur Bij dit examen is het gebruik van een (evt. grafische) rekenmachine toegestaan. Tevens krijgt u een formuleblad uitgereikt na afloop
Kansrekening en statistiek wi205in deel 2 6 april 200, 4.00 6.00 uur Bij dit examen is het gebruik van een (evt. grafische) rekenmachine toegestaan. Tevens krijgt u een formuleblad uitgereikt na afloop
Verklarende Statistiek: Toetsen. Zat ik nou in dat kritische gebied of niet?
 Verklarende Statistiek: Toetsen Zat ik nou in dat kritische gebied of niet? Toetsen, Overzicht Nulhypothese - Alternatieve hypothese (voorbeeld: toets voor p = p o in binomiale steekproef) Betrouwbaarheid
Verklarende Statistiek: Toetsen Zat ik nou in dat kritische gebied of niet? Toetsen, Overzicht Nulhypothese - Alternatieve hypothese (voorbeeld: toets voor p = p o in binomiale steekproef) Betrouwbaarheid
Aanpassingen takenboek! Statistische toetsen. Deze persoon in een verdeling. Iedereen in een verdeling
 Kwantitatieve Data Analyse (KDA) Onderzoekspracticum Sessie 2 11 Aanpassingen takenboek! Check studienet om eventuele verbeteringen te downloaden! Huidige versie takenboek: 09 Gjalt-Jorn Peters gjp@ou.nl
Kwantitatieve Data Analyse (KDA) Onderzoekspracticum Sessie 2 11 Aanpassingen takenboek! Check studienet om eventuele verbeteringen te downloaden! Huidige versie takenboek: 09 Gjalt-Jorn Peters gjp@ou.nl
Les 2: Toetsen van één gemiddelde
 Les 2: Toetsen van één gemiddelde Koen Van den Berge Statistiek 2 e Bachelor in de Biochemie & Biotechnologie 22 oktober 2018 Het statistisch testen van één gemiddelde is een veel voorkomende toepassing
Les 2: Toetsen van één gemiddelde Koen Van den Berge Statistiek 2 e Bachelor in de Biochemie & Biotechnologie 22 oktober 2018 Het statistisch testen van één gemiddelde is een veel voorkomende toepassing
Hoofdstuk 10: Regressie
 Hoofdstuk 10: Regressie Inleiding In dit deel zal uitgelegd worden hoe we statistische berekeningen kunnen maken als sprake is van één kwantitatieve responsvariabele en één kwantitatieve verklarende variabele.
Hoofdstuk 10: Regressie Inleiding In dit deel zal uitgelegd worden hoe we statistische berekeningen kunnen maken als sprake is van één kwantitatieve responsvariabele en één kwantitatieve verklarende variabele.
Data analyse Inleiding statistiek
 Data analyse Inleiding statistiek 1 Doel Beheersen van elementaire statistische technieken Toepassen van deze technieken op aardwetenschappelijke data 2 1 Leerstof Boek: : Introductory Statistics, door
Data analyse Inleiding statistiek 1 Doel Beheersen van elementaire statistische technieken Toepassen van deze technieken op aardwetenschappelijke data 2 1 Leerstof Boek: : Introductory Statistics, door
EIND TOETS TOEGEPASTE BIOSTATISTIEK I. 30 januari 2009
 EIND TOETS TOEGEPASTE BIOSTATISTIEK I 30 januari 2009 - Dit tentamen bestaat uit vier opgaven onderverdeeld in totaal 2 subvragen. - Geef bij het beantwoorden van de vragen een zo volledig mogelijk antwoord.
EIND TOETS TOEGEPASTE BIOSTATISTIEK I 30 januari 2009 - Dit tentamen bestaat uit vier opgaven onderverdeeld in totaal 2 subvragen. - Geef bij het beantwoorden van de vragen een zo volledig mogelijk antwoord.
werkcollege 7 - D&P10: Hypothesis testing using a single sample
 cursus 11 mei 2012 werkcollege 7 - D&P10: Hypothesis testing using a single sample huiswerk opgaven Ch.9: 1, 8, 11, 12, 20, 26, 36, 37, 71 Activities 9.3 en 9.4 experimenten zelf deelnemen als proefpersoon
cursus 11 mei 2012 werkcollege 7 - D&P10: Hypothesis testing using a single sample huiswerk opgaven Ch.9: 1, 8, 11, 12, 20, 26, 36, 37, 71 Activities 9.3 en 9.4 experimenten zelf deelnemen als proefpersoon
Klantonderzoek: statistiek!
 Klantonderzoek: statistiek! Statistiek bij klantonderzoek Om de resultaten van klantonderzoek juist te interpreteren is het belangrijk de juiste analyses uit te voeren. Vaak worden de mogelijkheden van
Klantonderzoek: statistiek! Statistiek bij klantonderzoek Om de resultaten van klantonderzoek juist te interpreteren is het belangrijk de juiste analyses uit te voeren. Vaak worden de mogelijkheden van
Tentamen Biostatistiek 1 voor BMT (2DM40) woensdag 2 november 2011, uur
 woensdag 2 november 2011, uur") Faculteit der Wiskunde en Informatica Tentamen Biostatistiek 1 voor BMT (2DM40) woensdag 2 november 2011, 9.00-12.00 uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en van een onbeschreven
Faculteit der Wiskunde en Informatica Tentamen Biostatistiek 1 voor BMT (2DM40) woensdag 2 november 2011, 9.00-12.00 uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en van een onbeschreven
Toets deel 2 Data-analyse en retrieval Vrijdag 1 Juli 2016:
 Toets deel 2 Data-analyse en retrieval Vrijdag 1 Juli 2016: 11.00-13.00 Algemene aanwijzingen 1. Het is toegestaan een aan beide zijden beschreven A4 met aantekeningen te raadplegen. 2. Het is toegestaan
Toets deel 2 Data-analyse en retrieval Vrijdag 1 Juli 2016: 11.00-13.00 Algemene aanwijzingen 1. Het is toegestaan een aan beide zijden beschreven A4 met aantekeningen te raadplegen. 2. Het is toegestaan
Voorbeelden van gebruik van 5 VUSTAT-apps
 Voorbeelden van gebruik van 5 VUSTAT-apps Piet van Blokland Begrijpen van statistiek door simulaties en visualisaties Hoe kun je deze apps gebruiken bij het statistiek onderwijs? De apps van VUSTAT zijn
Voorbeelden van gebruik van 5 VUSTAT-apps Piet van Blokland Begrijpen van statistiek door simulaties en visualisaties Hoe kun je deze apps gebruiken bij het statistiek onderwijs? De apps van VUSTAT zijn
Hoofdvraag. Hoe kan interne en externe data gebruikt worden voor ziektepreventie bij klanten van DFZ?
 Hoofdvraag Hoe kan interne en externe data gebruikt worden voor ziektepreventie bij klanten van DFZ? Data visualisatie (Grafieken, dashboards); Kwantitatieve analyse (cijfers, statistiek); Software Inzichten
Hoofdvraag Hoe kan interne en externe data gebruikt worden voor ziektepreventie bij klanten van DFZ? Data visualisatie (Grafieken, dashboards); Kwantitatieve analyse (cijfers, statistiek); Software Inzichten
introductie toetsen power pauze hypothesen schatten ten slotte introductie toetsen power pauze hypothesen schatten ten slotte
 toetsende statistiek week 1: kansen en random variabelen week 2: de steekproevenverdeling week 3: schatten en toetsen: de z-toets Moore, McCabe, and Craig. Introduction to the Practice of Statistics Chapter
toetsende statistiek week 1: kansen en random variabelen week 2: de steekproevenverdeling week 3: schatten en toetsen: de z-toets Moore, McCabe, and Craig. Introduction to the Practice of Statistics Chapter
Tentamen Inleiding Statistiek (WI2615) 10 april 2013, 9:00-12:00u
 10 april 2013, 9:00-12:00u") Technische Universiteit Delft Mekelweg 4 Faculteit Elektrotechniek, Wiskunde en Informatica 2628 CD Delft Tentamen Inleiding Statistiek (WI2615) 10 april 2013, 9:00-12:00u Formulebladen, rekenmachines,
Technische Universiteit Delft Mekelweg 4 Faculteit Elektrotechniek, Wiskunde en Informatica 2628 CD Delft Tentamen Inleiding Statistiek (WI2615) 10 april 2013, 9:00-12:00u Formulebladen, rekenmachines,
Bayesiaans leren. Les 2: Markov Chain Monte Carlo. Joris Bierkens. augustus Vakantiecursus 1/15
 Bayesiaans leren Les 2: Markov Chain Monte Carlo Joris Bierkens Vakantiecursus augustus 2019 1/15 Samenvatting en vooruitblik Veel statistische problemen kunnen we opvatten in een Bayesiaanse context n
Bayesiaans leren Les 2: Markov Chain Monte Carlo Joris Bierkens Vakantiecursus augustus 2019 1/15 Samenvatting en vooruitblik Veel statistische problemen kunnen we opvatten in een Bayesiaanse context n
Single and Multi-Population Mortality Models for Dutch Data
 Single and Multi-Population Mortality Models for Dutch Data Wilbert Ouburg Universiteit van Amsterdam 7 Juni 2013 Eerste begeleider: dr. K. Antonio Tweede begeleider: prof. dr. M. Vellekoop Wilbert Ouburg
Single and Multi-Population Mortality Models for Dutch Data Wilbert Ouburg Universiteit van Amsterdam 7 Juni 2013 Eerste begeleider: dr. K. Antonio Tweede begeleider: prof. dr. M. Vellekoop Wilbert Ouburg
Bayesiaans leren. Les 2: Markov Chain Monte Carlo. Joris Bierkens. augustus Vakantiecursus 1/15
 Bayesiaans leren Les 2: Markov Chain Monte Carlo Joris Bierkens Vakantiecursus augustus 209 /5 Samenvatting en vooruitblik Veel statistische problemen kunnen we opvatten in een Bayesiaanse context n π(θ)
Bayesiaans leren Les 2: Markov Chain Monte Carlo Joris Bierkens Vakantiecursus augustus 209 /5 Samenvatting en vooruitblik Veel statistische problemen kunnen we opvatten in een Bayesiaanse context n π(θ)
Voorbeeld regressie-analyse
 Voorbeeld regressie-analyse In dit voorbeeld wordt gebruik gemaakt van het SPSS data-bestand vb_regr.sav (dit bestand kan gedownload worden via de on-line helpdesk). We schatten een model waarin de afhankelijke
Voorbeeld regressie-analyse In dit voorbeeld wordt gebruik gemaakt van het SPSS data-bestand vb_regr.sav (dit bestand kan gedownload worden via de on-line helpdesk). We schatten een model waarin de afhankelijke
Deeltentamen 2 Algemene Statistiek Vrije Universiteit 18 december 2013
 Afdeling Wiskunde Volledig tentamen Algemene Statistiek Deeltentamen 2 Algemene Statistiek Vrije Universiteit 18 december 2013 Gebruik van een (niet-grafische) rekenmachine is toegestaan. Geheel tentamen:
Afdeling Wiskunde Volledig tentamen Algemene Statistiek Deeltentamen 2 Algemene Statistiek Vrije Universiteit 18 december 2013 Gebruik van een (niet-grafische) rekenmachine is toegestaan. Geheel tentamen:
Moderne Bayesiaanse statistiek:
 Evolutionary Ecology Group Stefan Van Dongen /46 Mezelf even voorstellen Biologie UA: 988-99 Biostatistiek UHasselt: 99-993 Pre-post doc UA Lund-Zweden: 993 00 Janssen Farmaceutica 00-003 Moderne Bayesiaanse
Evolutionary Ecology Group Stefan Van Dongen /46 Mezelf even voorstellen Biologie UA: 988-99 Biostatistiek UHasselt: 99-993 Pre-post doc UA Lund-Zweden: 993 00 Janssen Farmaceutica 00-003 Moderne Bayesiaanse
werkcollege 5 - P&D7: Population distributions - P&D8: Sampling variability and Sampling distributions
 cursus 4 mei 2012 werkcollege 5 - P&D7: Population distributions - P&D8: Sampling variability and Sampling distributions Huiswerk P&D, opgaven Chapter 6: 9, 19, 25, 33 P&D, opgaven Appendix A: 1, 9 doen
cursus 4 mei 2012 werkcollege 5 - P&D7: Population distributions - P&D8: Sampling variability and Sampling distributions Huiswerk P&D, opgaven Chapter 6: 9, 19, 25, 33 P&D, opgaven Appendix A: 1, 9 doen
6.1 Beschouw de populatie die wordt beschreven door onderstaande kansverdeling.
 Opgaven hoofdstuk 6 I Learning the Mechanics 6.1 Beschouw de populatie die wordt beschreven door onderstaande kansverdeling. De random variabele x wordt tweemaal waargenomen. Ga na dat, indien de waarnemingen
Opgaven hoofdstuk 6 I Learning the Mechanics 6.1 Beschouw de populatie die wordt beschreven door onderstaande kansverdeling. De random variabele x wordt tweemaal waargenomen. Ga na dat, indien de waarnemingen
Tentamen Biostatistiek 1 voor BMT (2DM40), op maandag 5 januari 2009 14.00-17.00 uur
, op maandag 5 januari 2009 14.00-17.00 uur") Faculteit der Wiskunde en Informatica Tentamen Biostatistiek voor BMT (2DM4), op maandag 5 januari 29 4.-7. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en van een onbeschreven
Faculteit der Wiskunde en Informatica Tentamen Biostatistiek voor BMT (2DM4), op maandag 5 januari 29 4.-7. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en van een onbeschreven
SPSS Introductiecursus. Sanne Hoeks Mattie Lenzen
 SPSS Introductiecursus Sanne Hoeks Mattie Lenzen Statistiek, waarom? Doel van het onderzoek om nieuwe feiten van de werkelijkheid vast te stellen door middel van systematisch onderzoek en empirische verzamelen
SPSS Introductiecursus Sanne Hoeks Mattie Lenzen Statistiek, waarom? Doel van het onderzoek om nieuwe feiten van de werkelijkheid vast te stellen door middel van systematisch onderzoek en empirische verzamelen
8. Analyseren van samenhang tussen categorische variabelen
 8. Analyseren van samenhang tussen categorische variabelen Er bestaat een samenhang tussen twee variabelen als de verdeling van de respons (afhankelijke) variabele verandert op het moment dat de waarde
8. Analyseren van samenhang tussen categorische variabelen Er bestaat een samenhang tussen twee variabelen als de verdeling van de respons (afhankelijke) variabele verandert op het moment dat de waarde
College 6 Eenweg Variantie-Analyse
 College 6 Eenweg Variantie-Analyse - Leary: Hoofdstuk 11, 1 (t/m p. 55) - MM&C: Hoofdstuk 1 (t/m p. 617), p. 63 t/m p. 66 - Aanvullende tekst 6, 7 en 8 Jolien Pas ECO 01-013 Het Experiment: een voorbeeld
College 6 Eenweg Variantie-Analyse - Leary: Hoofdstuk 11, 1 (t/m p. 55) - MM&C: Hoofdstuk 1 (t/m p. 617), p. 63 t/m p. 66 - Aanvullende tekst 6, 7 en 8 Jolien Pas ECO 01-013 Het Experiment: een voorbeeld
VOOR HET SECUNDAIR ONDERWIJS
 VOOR HET SECUNDAIR ONDERWIJS Steekproefmodellen en normaal verdeelde steekproefgrootheden 5. Werktekst voor de leerling Prof. dr. Herman Callaert Hans Bekaert Cecile Goethals Lies Provoost Marc Vancaudenberg
VOOR HET SECUNDAIR ONDERWIJS Steekproefmodellen en normaal verdeelde steekproefgrootheden 5. Werktekst voor de leerling Prof. dr. Herman Callaert Hans Bekaert Cecile Goethals Lies Provoost Marc Vancaudenberg
S0A17D: Examen Sociale Statistiek (deel 2)
") S0A17D: Examen Sociale Statistiek (deel 2) 21 juni 2011 Naam : Jaar en studierichting : Lees volgende aanwijzingen eerst voor het examen te beginnen : Wie de vragen aanneemt en bekijkt, moet minstens 1
S0A17D: Examen Sociale Statistiek (deel 2) 21 juni 2011 Naam : Jaar en studierichting : Lees volgende aanwijzingen eerst voor het examen te beginnen : Wie de vragen aanneemt en bekijkt, moet minstens 1
Statistiek in HBO scripties
 Statistiek in HBO scripties Wim Krijnen Lector Analyse Technieken voor Praktijkonderzoek Lectoraat Transparante Zorgverlening Hanze University of Applied Sciences January 29, 2015 Wim Krijnen Lector Analyse
Statistiek in HBO scripties Wim Krijnen Lector Analyse Technieken voor Praktijkonderzoek Lectoraat Transparante Zorgverlening Hanze University of Applied Sciences January 29, 2015 Wim Krijnen Lector Analyse
Samenvatting Statistiek
 Samenvatting Statistiek De hoofdstukken 1 t/m 3 gaan over kansrekening: het uitrekenen van kansen in een volledig gespecifeerd model, waarin de parameters bekend zijn en de kans op een gebeurtenis gevraagd
Samenvatting Statistiek De hoofdstukken 1 t/m 3 gaan over kansrekening: het uitrekenen van kansen in een volledig gespecifeerd model, waarin de parameters bekend zijn en de kans op een gebeurtenis gevraagd
TECHNISCHE UNIVERSITEIT EINDHOVEN
 TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Biostatistiek voor BMT (2DM4 en 2S39) op maandag 2--27, 4.-7. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Biostatistiek voor BMT (2DM4 en 2S39) op maandag 2--27, 4.-7. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
We illustreren deze werkwijze opnieuw a.h.v. de steekproef van de geboortegewichten
 Hoofdstuk 8 Betrouwbaarheidsintervallen In het vorige hoofdstuk lieten we zien hoe het mogelijk is om over een ongekende karakteristiek van een populatie hypothesen te formuleren. Een andere manier van
Hoofdstuk 8 Betrouwbaarheidsintervallen In het vorige hoofdstuk lieten we zien hoe het mogelijk is om over een ongekende karakteristiek van een populatie hypothesen te formuleren. Een andere manier van
Statistiek in een rechtzaak
 Statistiek in een rechtzaak Maarten van Kampen & Soon-Yip Wong 1 april 00 1 Schuldig of niet? Naar aanleiding van een recent krantenartikel over de rechtzaak omtrent Lucy B. willen wij onderzoeken wat
Statistiek in een rechtzaak Maarten van Kampen & Soon-Yip Wong 1 april 00 1 Schuldig of niet? Naar aanleiding van een recent krantenartikel over de rechtzaak omtrent Lucy B. willen wij onderzoeken wat
1. De volgende gemiddelden zijn gevonden in een experiment met de factor Conditie en de factor Sekse.
 Oefentoets 1 1. De volgende gemiddelden zijn gevonden in een experiment met de factor Conditie en de factor Sekse. Conditie = experimenteel Conditie = controle Sekse = Vrouw 23 33 Sekse = Man 20 36 Van
Oefentoets 1 1. De volgende gemiddelden zijn gevonden in een experiment met de factor Conditie en de factor Sekse. Conditie = experimenteel Conditie = controle Sekse = Vrouw 23 33 Sekse = Man 20 36 Van
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica. Tentamenopgaven Statistiek (2DD71) op xx-xx-xxxx, xx.00-xx.00 uur.
 op xx-xx-xxxx, xx.00-xx.00 uur.") VOORAF: Hieronder staat een aantal opgaven over de stof. Veel meer dan op het tentamen zelf gevraagd zullen worden. Op het tentamen zullen in totaal 20 onderdelen gevraagd worden. TECHNISCHE UNIVERSITEIT
VOORAF: Hieronder staat een aantal opgaven over de stof. Veel meer dan op het tentamen zelf gevraagd zullen worden. Op het tentamen zullen in totaal 20 onderdelen gevraagd worden. TECHNISCHE UNIVERSITEIT
College 2 Enkelvoudige Lineaire Regressie
 College Enkelvoudige Lineaire Regressie - Leary: Hoofdstuk 7 tot p. 170 (Advanced Correlational Strategies) - MM&C: Hoofdstuk 10 (Inference for Regression) - Aanvullende tekst 3 Jolien Pas ECO 011-01 Correlatie:
College Enkelvoudige Lineaire Regressie - Leary: Hoofdstuk 7 tot p. 170 (Advanced Correlational Strategies) - MM&C: Hoofdstuk 10 (Inference for Regression) - Aanvullende tekst 3 Jolien Pas ECO 011-01 Correlatie:
Extra Opgaven. 3. Van 10 personen meten we 100 keer de hartslag na het sporten. De gemiddelde hartslag van
 Extra Opgaven 1. Een persoon doet een HIV-test. Helaas is de uitslag positief. De test is echter niet perfect. De persoon vraagt zich af wat de kans is dat hij nu ook echt HIV heeft. Gegeven is: de kans
Extra Opgaven 1. Een persoon doet een HIV-test. Helaas is de uitslag positief. De test is echter niet perfect. De persoon vraagt zich af wat de kans is dat hij nu ook echt HIV heeft. Gegeven is: de kans
Tentamen Kansrekening en Statistiek MST 14 januari 2016, uur
 Tentamen Kansrekening en Statistiek MST 14 januari 2016, 14.00 17.00 uur Het tentamen bestaat uit 15 meerkeuzevragen 2 open vragen. Een formuleblad wordt uitgedeeld. Normering: 0.4 punt per MC antwoord
Tentamen Kansrekening en Statistiek MST 14 januari 2016, 14.00 17.00 uur Het tentamen bestaat uit 15 meerkeuzevragen 2 open vragen. Een formuleblad wordt uitgedeeld. Normering: 0.4 punt per MC antwoord
Inleiding Statistiek
 Inleiding Statistiek Practicum 1 Op dit practicum herhalen we wat Matlab. Vervolgens illustreren we het schatten van een parameter en het toetsen van een hypothese met een klein simulatie experiment. Het
Inleiding Statistiek Practicum 1 Op dit practicum herhalen we wat Matlab. Vervolgens illustreren we het schatten van een parameter en het toetsen van een hypothese met een klein simulatie experiment. Het