INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 8
|
|
|
- Vincent de Haan
- 6 jaren geleden
- Aantal bezoeken:
Transcriptie
 om met onze nieuwe auto een mooie plaats in de file te bemachtigen.")
1 INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 8 1. Eén van de nadelige gevolgen van de moderne welvaart is een monstrueus mobiliteitsprobleem. Om één of andere bizarre reden willen we graag allemaal om acht uur s ochtends in de wagen springen (liefst ook alleen) om met onze nieuwe auto een mooie plaats in de file te bemachtigen. Allerlei maatregelen ten spijt lijkt het probleem enkel nog groter te worden en duwen we meer en meer wagens tegelijkertijd de weg op. Eén van de maatregelen die worden getroffen in de hoop om mensen te behoeden voor de file is het melden van verkeersinformatie op de radio. Zo n verkeersbericht bevat, gezien de steeds uitdijende proporties, een overdosis aan informatie die soms moeilijk te onthouden is. Daarom probeert men de berichten te presenteren op een manier die de informatie beter verwerkbaar maakt. Om de optimale volgorde en formulering te vinden test een verkeersredactie een aantal berichten uit door een groep van 35 volwassenen achtereenvolgens verschillende verkeersberichten te laten beluisteren. In totaal zijn er zes inhoudelijk verschillende berichten die elk op drie manieren geformuleerd zijn en in willekeurige volgorde worden aangeboden. Na elk bericht volgt een korte pauze, waarna de deelnemers zoveel mogelijk elementen uit de verkeersinfo proberen te reproduceren. De resultaten van dit onderzoek vind je in het bestand opdr_verkeersinfo.sav op de website. Je vindt daarin per deelnemer het gemiddeld aantal elementen die hij of zij zich kon herinneren voor de drie verschillende formuleringen. Ga na welke formulering zorgt voor de beste reproductie. In dit onderzoek wordt als onafhankelijke variabele de formulering gemanipuleerd (nominaal). Afhankelijke variabele is de reproductie, gemeten in aantal herinnerde elementen uit de berichten (interval). Aangezien er drie formuleringen zijn, bestuderen we drie populaties. De steekproeven uit deze populaties zijn afhankelijk van elkaar getrokken, want het betreft telkens dezelfde 35 personen die achtereenvolgens de verschillende berichten te horen krijgen. Er is voldaan aan de assumpties voor parametrisch toetsen, dus we kunnen een repeated measures ANOVA selecteren om deze resultaten te bekijken. De assumptie van sfericiteit zullen we tijdens de analyse bekijken. Open het databestand en kies Analyze > General Linear Model > Repeated measures. Vul de dialoogvensters in zoals in de afbeelding.

2 Kies eventueel ook een plot en de nodige opties via de knoppen Plots en Options. In de tabel met beschrijvende statistieken zien we dat formulering 2 blijkbaar een hogere reproductie oplevert dan de andere twee formuleringen. We zullen verder bekijken of dit verschil ook significant is. Descriptive Statistics Mean Std. Deviation N reproductie1 8,6691 1, reproductie2 11,1182 1, reproductie3 7,7949 1, Eerst kijken we nog naar de test voor sfericiteit. Deze geeft aan dat niet voldaan is aan deze assumptie. We zullen bij de interpretatie van de ANOVA dus rekening houden met een correctie voor deze schending van de assumpties. Mauchly's Test of Sphericity a Within Subjects Effect Mauchly's W Approx. Chi- df Sig. Epsilon b Square Greenhouse- Geisser Huynh-Feldt Lower-bound formulering,804 7,212 2,027,836,874,500 In de eigenlijke ANOVA-tabel bekijken we dus het significantieniveau op de lijn Huynh-Feldt omdat we een correctie voor sfericiteit willen toepassen. Er is blijkbaar een significant effect van de formulering op de reproductie van de inhoud van de berichten.
3 Tests of Within-Subjects Effects Source Type III Sum of Squares df Mean Square F Sig. Partial Eta Squared formulering Sphericity Assumed 207, ,871 39,698,000,539 Greenhouse-Geisser 207,742 1, ,261 39,698,000,539 Huynh-Feldt 207,742 1, ,837 39,698,000,539 Lower-bound 207,742 1, ,742 39,698,000,539 Error(formulering) Sphericity Assumed 177, ,616 Greenhouse-Geisser 177,922 56,842 3,130 Huynh-Feldt 177,922 59,436 2,994 Lower-bound 177,922 34,000 5,233 In de tabel Pairwise Comparisons vinden we terug tussen welke formuleringen er precies een verschil is. Blijkbaar verschillen formulering 1 en 2, alsook 2 en 3 van elkaar. Formulering 1 verschilt niet significant van formulering 3. Pairwise Comparisons (I) formulering (J) formulering Mean Difference (I-J) Std. Error Sig. b 95% Confidence Interval for Difference b Lower Bound Upper Bound ,449 *,289,000-3,176-1,722 3,874,428,147 -,203 1, ,449 *,289,000 1,722 3, ,323 *,427,000 2,248 4, ,874,428,147-1,952, ,323 *,427,000-4,398-2,248 De effectgrootte lezen we ook af uit de ANOVA-tabel, nl.539. Rapportering: Om na te gaan of de formulering van een verkeersbericht een invloed heeft op het reproduceren van de inhoud ervan, werd een repeated measures ANOVA uitgevoerd. Mauchly s test geeft aan dat de assumptie van sfericiteit geschonden is, ( ), p =.027. Daarom werd de Huynh-Feldt correctie gebruikt bij het interpreteren van het effect. Hieruit bleek dat er een significant effect was van formulering op reproductie, F(2, 59.44) = 39.70, p <.001, η² =.54. Formulering 2 zorgt voor meer reproductie (M = 11.12, SD = 1.68) dan formulering 1 (M = 8.66, SD = 1.53, p <.001) en formulering 3 (M = 7.80, SD = 1.77, p =.001). Het verschil tussen formulering 1 en formulering 3 was niet significant, p =.147.

4 2. In het onderzoek uit opdracht 1 werd aan de deelnemers ook gevraagd om de drie verschillende formuleringen te rangschikken volgens hun eigen voorkeur. De formulering die een deelnemer het beste vindt krijgt een 3, de volgende een 2 en de minst goede formulering krijgt een 1. De data staan in hetzelfde bestand. Kan je besluiten dat één van de formuleringen meer de voorkeur wegdraagt dan de andere? Stemt dit overeen met de formulering die de beste reproductie genereert? Dit onderzoek is gelijkaardig aan het onderzoek in opdracht één, behalve wat het meetniveau van de afhankelijke variabele betreft. De voorkeur van de deelnemers wordt immers gemeten met een ordinale schaal. Dat betekent dat we met de nonparametrische variant van de repeated measures ANOVA zullen werken, met name Friedman s ANOVA. Kies in het menu Analyze > Nonparametric tests > Legacy Dialogs > k related samples. Vul het dialoogvenster in zoals hieronder en vink Descriptives aan achter de knop Statistics. We stellen vast dat er een significant verschil is tussen de drie formuleringen: Test Statistics a N 35 Chi-Square 10,000 df 2 Asymp. Sig.,007 a. Friedman Test Aan de hand van enkele Wilcoxon Signed Rank tests zullen we nagaan waar de verschillen zich precies voordoen. We zullen alle condities onderling vergelijken en laten dus het alpha-niveau zakken tot α/3 =.017. We stellen vast dat het verschil tussen formulering 1 en 2 en tussen 1 en 3 significant is. Test Statistics a
5 voorkeur2 - voorkeur1 voorkeur3 - voorkeur1 voorkeur3 - voorkeur2 Z -2,442 b -2,618 b -,852 c Asymp. Sig. (2-tailed),015,009,394 a. Wilcoxon Signed Ranks Test b. Based on positive ranks. c. Based on negative ranks. Rapportering: Om de voorkeur van luisteraars voor een bepaalde formulering van verkeersberichten na te gaan werd Friedman s ANOVA uitgevoerd. Hieruit bleek de formulering een significant effect te hebben op de voorkeur, F = 10, p =.007. Bijkomend werden paarsgewijze Wilcoxon signed-rank toetsen uitgevoerd om de voorkeur voor formulering 1 (mean rank = 3.43), formulering 2 (mean rank = 1.71) en formulering 3 (mean rank = 1.86) onderling te vergelijken. Hierbij werd een gecorrigeerd significantieniveau van α =.017 gehanteerd. Uit deze post hoc toetsen bleken significante verschillen tussen de voorkeuren voor formulering 1 en 2 (z = -2.44, p =.015, r = -.29) alsook tussen formulering 1 en 3 (z = -2.62, p =.009, r = -.31). Er was geen significant verschil tussen de voorkeuren voor formulering 2 en 3 (z = -.85, p =.39, r = -.10). 3. Het schrijven van een boek is een aangename en intellectuele bezigheid die bijdraagt tot de zelfverwezenlijking, maar neigt al eens uit te draaien op oncontroleerbare paniek naarmate het einde nadert. Gezien de onwrikbaarheid van de deadline van de uitgever komen er dan immers vaak lange dagen en nachtelijke sessies aan te pas. Sommige auteurs beroepen zich dan op muziek om de motivatie en concentratie te bewaren. Gezien het belang van teksten die geproduceerd worden kan je je afvragen in hoeverre de aard van die muziek een invloed heeft op de kwaliteit van het werk. We testen dit uit door een aantal personen vier dagen op rij te laten schrijven aan een essay over uiteenlopende onderwerpen (geweld in videogames, de teloorgang van het kapitalisme, de wenselijkheid van kookprogramma s op televisie en het nut van lange onderbroeken), die over de dagen gecontrabalanceerd worden. De deelnemers schrijven de hele dag door waarbij ze telkens één van vier muziekgenres te horen krijgen: hard rock, dub step, klassiek en jazzfunk. Op het einde van elke dag dienen ze het essay in, waarvan het aantal woorden geregistreerd wordt en dat vervolgens kwalitatief beoordeeld wordt door enkele onafhankelijke beoordelaars. De deelnemers krijgen zodoende elke dag twee scores: een aantal woorden en een kwaliteitsbeoordeling op 100 punten. Je mag ervan uitgaan dat beide variabelen normaal verdeeld zijn in de populatie. Alle resultaten staan in het bestand opdr_essay.sav op de website. Ga na welke muziek de beste invloed heeft op de kwantiteit en kwaliteit van het werk. We bestuderen het verband tussen het muziekgenre en twee afhankelijke variabelen: kwantiteit van het essay en kwaliteit van het essay. De onafhankelijke variabele is van nominaal meetniveau en bevat vier niveaus (genres) terwijl de afhankelijke variabelen worden gemeten op intervalniveau. De onderzoekseenheden zijn de deelnemers aan het experiment, die de verschillende condities doorlopen. Het gaat dus om herhaalde metingen of afhankelijke steekproeven. Bij het checken van de assumptie van normaliteit met het Explore commando stellen we vast dat we mogen aannemen dat de variabelen normaal verdeeld zijn in de populatie. Op die manier komen we terecht bij een repeated measures ANOVA, die we starten via Analyze > General Linear Model > Repeated Measures.

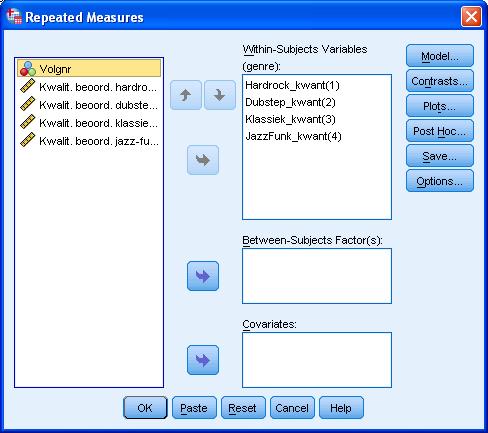
6 Onder Options:

7 Eventueel ook nog een grafiek opvragen via Plots. In de output lezen we een aantal beschrijvende gegevens af: Descriptive Statistics Mean Std. Deviation N Aantal woorden hardrock 4772,36 490, Aantal woorden dubstep 5117,94 355, Aantal woorden klassiek 3703,20 410, Aantal woorden jazz-funk 3770,88 420, De test voor sfericiteit wijst uit dat de assumptie geschonden is. We zullen dus een correctie moeten toepassen. Mauchly's Test of Sphericity a Within Subjects Effect Mauchly's W Approx. Chi- df Sig. Epsilon b Square Greenhouse- Geisser Huynh-Feldt Lower-bound genre,454 12,410 5,030,754,876,333 Tests the null hypothesis that the error covariance matrix of the orthonormalized transformed dependent variables is proportional to an identity matrix. a. Design: Intercept Within Subjects Design: genre
8 b. May be used to adjust the degrees of freedom for the averaged tests of significance. Corrected tests are displayed in the Tests of Within- Subjects Effects table. Tests of Within-Subjects Effects Source Type III Sum of Squares df Mean Square F Sig. Partial Eta Squared Sphericity Assumed , ,863 52,692,000,756 genre Greenhouse-Geisser ,588 2, ,418 52,692,000,756 Huynh-Feldt ,588 2, ,455 52,692,000,756 Lower-bound ,588 1, ,588 52,692,000,756 Sphericity Assumed , ,472 Error(genre) Greenhouse-Geisser ,093 38, ,596 Huynh-Feldt ,093 44, ,555 Lower-bound ,093 17, ,417 Als we de Huynh-Feldt correctie toepassen, stellen we vast dat er een significant effect is van Genre. Om meer gedetailleerd te bekijken tussen welke genres dit effect zich voodoet kijken we naar deze tabel: Pairwise Comparisons (I) genre (J) genre Mean Difference (I-J) Std. Error Sig. b 95% Confidence Interval for Difference b Lower Bound Upper Bound 2-345, ,048, ,823 9, ,167 * 142,736, , , ,487 * 176,959, , , , ,048,059-9, , ,744 * 141,528, , , ,064 * 105,750, , , ,167 * 142,736, , , ,744 * 141,528, , , , ,765 1, , , ,487 * 176,959, , , ,064 * 105,750, , , , ,765 1, , ,807 Based on estimated marginal means *. The mean difference is significant at the,05 level. b. Adjustment for multiple comparisons: Bonferroni.
9 Blijkbaar zijn er verschillen tussen 1 en 3, tussen 1 en 4, tussen 2 en 3, tussen 2 en 4. Dezelfde werkwijze dienen we nog eens te volgen voor de tweede afhankelijke variabele, kwaliteit van het essay. Rapportering: Om na te gaan of het muziekgenre waarnaar mensen luisteren tijdens het schrijven van een essay een invloed heeft op het aantal woorden in het essay en de inhoudelijke kwaliteit van het essay, werden twee repeated measures ANOVA s uitgevoerd. Uit de eerste ANOVA bleek dat er een effect is van het muziekgenre op het aantal woorden gebruikt in het essay, F (2.63, 44.65) = 52.69, p <.001, η² =.76. Hiervoor werd een Huynh-Feldt correctie toegepast bij gebrek aan sfericiteit in de data. De essays bevatten gemiddeld meer woorden bij het luisteren naar hardrock (M = , SD = ) dan het luisteren naar klassieke muziek (M = , SD = , p <.001) en jazzfunk (M = , SD = , p <.001). Ook het luisteren naar dubstep (M = , SD = ) leverde meer woorden op dan het luisteren naar klassieke muziek (p <.001) of jazz-funk (p <.001). De andere onderlinge verschillen waren niet significant. De tweede ANOVA leverde evidentie voor een effect van muziekgenre op de kwaliteit van de essays, F (3, 51) = 5.54, p =.002, η² =.25. Meer bepaald werden de essays uit de jazz-funk conditie hoger beoordeeld (M = 82.55, SD = 18.38) dan de essays uit de hardrock conditie (M = 62.41, SD = 11.41, p =.014) en de dubstep conditie (M = 62.87, SD = 21.29, p =.035). De verschillen tussen deze condities en de conditie met klassieke muziek (M = 73.47, SD = 18.80) waren niet significant.
M M M M M M M M M M M M M M La La La La La La La Mid Mid Mid Mid Mid Mid Mid 65 56 83 68 64 47 59 63 93 65 75 68 68 51
 INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 7 1. Een onderzoeker wil nagaan of de fitheid van jongeren tussen 14 en 18 jaar (laag, matig, hoog) en het geslacht (M, V) een
INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 7 1. Een onderzoeker wil nagaan of de fitheid van jongeren tussen 14 en 18 jaar (laag, matig, hoog) en het geslacht (M, V) een
De data worden ingevoerd in twee variabelen, omdat we te maken hebben met herhaalde metingen:
 INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 6 1. De 15 leden van een kleine mountainbikeclub vragen zich af in welk mate de omgevingstemperatuur een invloed heeft op hun
INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 6 1. De 15 leden van een kleine mountainbikeclub vragen zich af in welk mate de omgevingstemperatuur een invloed heeft op hun
Uitvoer van analyses (SPSS 16) voor het Faalfeedback en Oriëntatie voorbeeld in hoofdstuk 7 (Herhaalde metingen) >
 voor het Faalfeedback en Oriëntatie voorbeeld in hoofdstuk 7 (Herhaalde metingen) >") Uitvoer van analyses (SPSS 6) voor het aalfeedback en Oriëntatie voorbeeld in hoofdstuk 7 (Herhaalde metingen) > ** Berekening van lineaire en kwadratische trendvariabele. Compute ylin = -.77678 * y +
Uitvoer van analyses (SPSS 6) voor het aalfeedback en Oriëntatie voorbeeld in hoofdstuk 7 (Herhaalde metingen) > ** Berekening van lineaire en kwadratische trendvariabele. Compute ylin = -.77678 * y +
Meervoudige ANOVA Onderzoeksvraag Voorwaarden
 Er is onderzoek gedaan naar rouw na het overlijden van een huisdier (contactpersoon: Karolijne van der Houwen (Klinische Psychologie)). Mensen konden op internet een vragenlijst invullen. Daarin werd gevraagd
Er is onderzoek gedaan naar rouw na het overlijden van een huisdier (contactpersoon: Karolijne van der Houwen (Klinische Psychologie)). Mensen konden op internet een vragenlijst invullen. Daarin werd gevraagd
INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 5
 INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 5 1. De onderzoekers van een preventiedienst vermoeden dat werknemers in een bedrijf zonder liften fitter zijn dan werknemers
INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 5 1. De onderzoekers van een preventiedienst vermoeden dat werknemers in een bedrijf zonder liften fitter zijn dan werknemers
Bij herhaalde metingen ANOVA komt het effect van het experiment naar voren bij de variantie binnen participanten. Bij de gewone ANOVA is dit de SS R
 14. Herhaalde metingen Introductie Bij herhaalde metingen worden er bij verschillende condities in een experiment dezelfde proefpersonen gebruikt of waarbij dezelfde proefpersonen op verschillende momenten
14. Herhaalde metingen Introductie Bij herhaalde metingen worden er bij verschillende condities in een experiment dezelfde proefpersonen gebruikt of waarbij dezelfde proefpersonen op verschillende momenten
Enkelvoudige ANOVA Onderzoeksvraag Voorwaarden
 Er is onderzoek gedaan naar rouw na het overlijden van een huisdier (contactpersoon: Karolijne van der Houwen (Klinische Psychologie)). Mensen konden op internet een vragenlijst invullen. Daarin werd gevraagd
Er is onderzoek gedaan naar rouw na het overlijden van een huisdier (contactpersoon: Karolijne van der Houwen (Klinische Psychologie)). Mensen konden op internet een vragenlijst invullen. Daarin werd gevraagd
ANOVA in SPSS. Hugo Quené. opleiding Taalwetenschap Universiteit Utrecht Trans 10, 3512 JK Utrecht 12 maart 2003
 ANOVA in SPSS Hugo Quené hugo.quene@let.uu.nl opleiding Taalwetenschap Universiteit Utrecht Trans 10, 3512 JK Utrecht 12 maart 2003 1 vooraf In dit voorbeeld gebruik ik fictieve gegevens, ontleend aan
ANOVA in SPSS Hugo Quené hugo.quene@let.uu.nl opleiding Taalwetenschap Universiteit Utrecht Trans 10, 3512 JK Utrecht 12 maart 2003 1 vooraf In dit voorbeeld gebruik ik fictieve gegevens, ontleend aan
introductie Wilcoxon s rank sum toets Wilcoxon s signed rank toets introductie Wilcoxon s rank sum toets Wilcoxon s signed rank toets
 toetsende statistiek week 1: kansen en random variabelen week : de steekproevenverdeling week 3: schatten en toetsen: de z-toets week : het toetsen van gemiddelden: de t-toets week 5: het toetsen van varianties:
toetsende statistiek week 1: kansen en random variabelen week : de steekproevenverdeling week 3: schatten en toetsen: de z-toets week : het toetsen van gemiddelden: de t-toets week 5: het toetsen van varianties:
Antwoordvel Versie A
 Antwoordvel Versie A Interimtoets Toegepaste Biostatistiek 13 december 013 Naam:... Studentnummer:...... Antwoorden: Vraag Antwoord Antwoord Antwoord Vraag Vraag A B C D A B C D A B C D 1 10 19 11 0 3
Antwoordvel Versie A Interimtoets Toegepaste Biostatistiek 13 december 013 Naam:... Studentnummer:...... Antwoorden: Vraag Antwoord Antwoord Antwoord Vraag Vraag A B C D A B C D A B C D 1 10 19 11 0 3
mlw stroom 2.2 Biostatistiek en Epidemiologie College 9: Herhaalde metingen (2) Syllabus Afhankelijke Data Hoofdstuk 4, 5.1, 5.2
 Syllabus Afhankelijke Data Hoofdstuk 4, 5.1, 5.2") mlw stroom 2.2 Biostatistiek en Epidemiologie College 9: Herhaalde metingen (2) Syllabus Afhankelijke Data Hoofdstuk 4, 5.1, 5.2 Bjorn Winkens Methodologie en Statistiek Universiteit Maastricht 21 maart
mlw stroom 2.2 Biostatistiek en Epidemiologie College 9: Herhaalde metingen (2) Syllabus Afhankelijke Data Hoofdstuk 4, 5.1, 5.2 Bjorn Winkens Methodologie en Statistiek Universiteit Maastricht 21 maart
Meervoudige variantieanalyse
 Meervoudige variantieanalyse Inleiding In dit hoofdstuk, dat aansluit op hoofdstuk II-12 (deel2) van het statistiekboek, wordt besproken hoe met SPSS gemiddelden van verschillende groepen met elkaar vergeleken
Meervoudige variantieanalyse Inleiding In dit hoofdstuk, dat aansluit op hoofdstuk II-12 (deel2) van het statistiekboek, wordt besproken hoe met SPSS gemiddelden van verschillende groepen met elkaar vergeleken
Open het databestand in SPSS en kies Analyze > Correlate > Bivariate. Vul vervolgens het dialoogvenster in als volgt:
 INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 9 1. Een klinisch psycholoog vraagt zich af of er een verband bestaat tussen depressie en sociale vermijding in de populatie
INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 9 1. Een klinisch psycholoog vraagt zich af of er een verband bestaat tussen depressie en sociale vermijding in de populatie
We berekenen nog de effectgrootte aan de hand van formule 4.2 en rapporteren:
 INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 4 1. Toets met behulp van SPSS de hypothese van Evelien in verband met de baardlengte van metalfans. Ga na of je dezelfde conclusies
INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 4 1. Toets met behulp van SPSS de hypothese van Evelien in verband met de baardlengte van metalfans. Ga na of je dezelfde conclusies
a. Wanneer kan men in plaats van de Pearson correlatie coefficient beter de Spearman rangcorrelatie coefficient berekenen?
 Opdracht 15a ------------ Spearman rangcorrelatie coefficient (non-parametrische tegenhanger van de Pearson correlatie coefficient) Wilcoxon symmetrie-toets (non-parametrische tegenhanger van de t-procedure
Opdracht 15a ------------ Spearman rangcorrelatie coefficient (non-parametrische tegenhanger van de Pearson correlatie coefficient) Wilcoxon symmetrie-toets (non-parametrische tegenhanger van de t-procedure
c. Geef de een-factor ANOVA-tabel. Formuleer H_0 and H_a. Wat is je conclusie?
 Opdracht 13a ------------ Een-factor ANOVA (ANOVA-tabel, Contrasten, Bonferroni) Bij een onderzoek naar de leesvaardigheid bij kinderen in de V.S. werden drie onderwijsmethoden met elkaar vergeleken. Verschillende
Opdracht 13a ------------ Een-factor ANOVA (ANOVA-tabel, Contrasten, Bonferroni) Bij een onderzoek naar de leesvaardigheid bij kinderen in de V.S. werden drie onderwijsmethoden met elkaar vergeleken. Verschillende
Hoofdstuk 10 Eenwegs- en tweewegs-variantieanalyse
 Hoofdstuk 10 Eenwegs- en tweewegs-variantieanalyse 10.1 Eenwegs-variantieanalyse: Als we gegevens hebben verzameld van verschillende groepen en we willen nagaan of de populatiegemiddelden van elkaar verscihllen,
Hoofdstuk 10 Eenwegs- en tweewegs-variantieanalyse 10.1 Eenwegs-variantieanalyse: Als we gegevens hebben verzameld van verschillende groepen en we willen nagaan of de populatiegemiddelden van elkaar verscihllen,
INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 11
 INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 11 1. Een onderzoeker vraagt zich af of werknemers zich na de Kerstvakantie meer depressief voelen dan na de zomervakantie.
INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 11 1. Een onderzoeker vraagt zich af of werknemers zich na de Kerstvakantie meer depressief voelen dan na de zomervakantie.
Bij factor ANOVA is er een tweede onafhankelijke variabele in de analyse bij gekomen. Er zijn drie soorten designs mogelijk:
 13. Factor ANOVA De theorie achter factor ANOVA (tussengroep) Bij factor ANOVA is er een tweede onafhankelijke variabele in de analyse bij gekomen. Er zijn drie soorten designs mogelijk: 1. Onafhankelijke
13. Factor ANOVA De theorie achter factor ANOVA (tussengroep) Bij factor ANOVA is er een tweede onafhankelijke variabele in de analyse bij gekomen. Er zijn drie soorten designs mogelijk: 1. Onafhankelijke
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica. Tentamen Statistiek 2 voor TeMa (2S195) op vrijdag , 9-12 uur.
 op vrijdag , 9-12 uur.") TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek 2 voor TeMa (2S95) op vrijdag 29-04-2004, 9-2 uur. Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek 2 voor TeMa (2S95) op vrijdag 29-04-2004, 9-2 uur. Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica. Tentamen Statistiek 2 voor TeMa (2S195) op dinsdag , uur.
 op dinsdag , uur.") TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor TeMa (S95) op dinsdag 3-03-00, 9- uur. Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor TeMa (S95) op dinsdag 3-03-00, 9- uur. Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en
Interim Toegepaste Biostatistiek deel 1 14 december 2009 Versie A ANTWOORDEN
 Interim Toegepaste Biostatistiek deel december 2009 Versie A ANTWOORDEN C 2 B C A 5 C 6 B 7 B 8 B 9 D 0 D C 2 A B A 5 C Lever zowel het antwoordformulier als de interim toets in Versie A 2. Dit tentamen
Interim Toegepaste Biostatistiek deel december 2009 Versie A ANTWOORDEN C 2 B C A 5 C 6 B 7 B 8 B 9 D 0 D C 2 A B A 5 C Lever zowel het antwoordformulier als de interim toets in Versie A 2. Dit tentamen
De primaire link op gemeentelijke websites, Bijlagen. over efficiëntie, effectiviteit en gebruiksvriendelijkheid
 De primaire link op gemeentelijke s, over efficiëntie, effectiviteit en gebruiksvriendelijkheid Bijlagen Henk S. Kok (9827722) scriptiebegeleiders: Frank Jansen en Leo Lentz Faculteit der Letteren Nederlands,
De primaire link op gemeentelijke s, over efficiëntie, effectiviteit en gebruiksvriendelijkheid Bijlagen Henk S. Kok (9827722) scriptiebegeleiders: Frank Jansen en Leo Lentz Faculteit der Letteren Nederlands,
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica
 TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor TeMa (S95) Avondopleiding. donderdag 6-6-3, 9.-. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor TeMa (S95) Avondopleiding. donderdag 6-6-3, 9.-. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
TECHNISCHE UNIVERSITEIT EINDHOVEN
 TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek 2 voor TeMa (2S95) dinsdag 2-08-2003, 4.00-7.00 uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine,
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek 2 voor TeMa (2S95) dinsdag 2-08-2003, 4.00-7.00 uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine,
Hoofdstuk 5 Een populatie: parametrische toetsen
 Hoofdstuk 5 Een populatie: parametrische toetsen 5.1 Gemiddelde, variantie, standaardafwijking: De variantie is als het ware de gemiddelde gekwadrateerde afwijking van het gemiddelde. Hoe groter de variantie
Hoofdstuk 5 Een populatie: parametrische toetsen 5.1 Gemiddelde, variantie, standaardafwijking: De variantie is als het ware de gemiddelde gekwadrateerde afwijking van het gemiddelde. Hoe groter de variantie
Verdelingsvrije statistiek
 Verdelingsvrije statistiek Inleiding In hoofdstuk II-5 (deel ) worden een aantal verdelingsvrije toetsen (ook wel niet-parametrische toetsen) besproken, die gebruikt worden als de te onderzoeken variabele
Verdelingsvrije statistiek Inleiding In hoofdstuk II-5 (deel ) worden een aantal verdelingsvrije toetsen (ook wel niet-parametrische toetsen) besproken, die gebruikt worden als de te onderzoeken variabele
Inhoud. Woord vooraf 13. Hoofdstuk 1. Inductieve statistiek in onderzoek 17. Hoofdstuk 2. Kansverdelingen en kansberekening 28
 Inhoud Woord vooraf 13 Hoofdstuk 1. Inductieve statistiek in onderzoek 17 1.1 Wat is de bedoeling van statistiek? 18 1.2 De empirische cyclus 19 1.3 Het probleem van de inductieve statistiek 20 1.4 Statistische
Inhoud Woord vooraf 13 Hoofdstuk 1. Inductieve statistiek in onderzoek 17 1.1 Wat is de bedoeling van statistiek? 18 1.2 De empirische cyclus 19 1.3 Het probleem van de inductieve statistiek 20 1.4 Statistische
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica. Tentamen Statistiek 2 voor TeMa (2S195) op donderdag ,
 op donderdag ,") TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek 2 voor TeMa (2S95) op donderdag 0-03-2005, 4.00-7.00 uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine,
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek 2 voor TeMa (2S95) op donderdag 0-03-2005, 4.00-7.00 uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine,
Beschrijvende statistieken
 Elske Salemink (Klinische Psychologie) heeft onderzocht of het lezen van verhaaltjes invloed heeft op angst. Studenten werden at random ingedeeld in twee groepen. De ene groep las positieve verhaaltjes
Elske Salemink (Klinische Psychologie) heeft onderzocht of het lezen van verhaaltjes invloed heeft op angst. Studenten werden at random ingedeeld in twee groepen. De ene groep las positieve verhaaltjes
Voer de gegevens in in een tabel. Definieer de drie kolommen van de tabel en kies als kolomnamen groep, vooraf en achteraf.
 Opdracht 10a ------------ t-procedures voor gekoppelde paren t-procedures voor twee onafhankelijke steekproeven samengestelde t-procedures voor twee onafhankelijke steekproeven Twee groepen van 10 leraren
Opdracht 10a ------------ t-procedures voor gekoppelde paren t-procedures voor twee onafhankelijke steekproeven samengestelde t-procedures voor twee onafhankelijke steekproeven Twee groepen van 10 leraren
Pilot vragenlijst communicatieve redzaamheid
 Pilot vragenlijst communicatieve redzaamheid Het instrument Communicatieve redzaamheid kan worden opgevat als een vermogen om wederkerig te communiceren met behulp van woorden, gebaren of symbolen. Communicatief
Pilot vragenlijst communicatieve redzaamheid Het instrument Communicatieve redzaamheid kan worden opgevat als een vermogen om wederkerig te communiceren met behulp van woorden, gebaren of symbolen. Communicatief
Hoofdstuk 8 Het toetsen van nonparametrische variabelen
 Hoofdstuk 8 Het toetsen van nonparametrische variabelen 8.1 Non-parametrische toetsen: deze toetsen zijn toetsen waarbij de aannamen van normaliteit en intervalniveau niet nodig zijn. De aannamen zijn
Hoofdstuk 8 Het toetsen van nonparametrische variabelen 8.1 Non-parametrische toetsen: deze toetsen zijn toetsen waarbij de aannamen van normaliteit en intervalniveau niet nodig zijn. De aannamen zijn
Bijlage 3: Multiple regressie analyse
 Bijlage 3: Multiple regressie analyse REGRESSION /DESCRIPTIVES MEAN STDDEV CORR SIG N /MISSING PAIRWISE /STATISTICS COEFF OUTS CI(95) R ANOVA COLLIN TOL ZPP /CRITERIA=PIN(.05) POUT(.10) /NOORIGIN /DEPENDENT
Bijlage 3: Multiple regressie analyse REGRESSION /DESCRIPTIVES MEAN STDDEV CORR SIG N /MISSING PAIRWISE /STATISTICS COEFF OUTS CI(95) R ANOVA COLLIN TOL ZPP /CRITERIA=PIN(.05) POUT(.10) /NOORIGIN /DEPENDENT
EIND TOETS TOEGEPASTE BIOSTATISTIEK I. 30 januari 2009
 EIND TOETS TOEGEPASTE BIOSTATISTIEK I 30 januari 2009 - Dit tentamen bestaat uit vier opgaven onderverdeeld in totaal 2 subvragen. - Geef bij het beantwoorden van de vragen een zo volledig mogelijk antwoord.
EIND TOETS TOEGEPASTE BIOSTATISTIEK I 30 januari 2009 - Dit tentamen bestaat uit vier opgaven onderverdeeld in totaal 2 subvragen. - Geef bij het beantwoorden van de vragen een zo volledig mogelijk antwoord.
Het ANCOVA model is een vorm van het general linear model (GLM), en kan als volgt geschreven worden qua populatie parameters:
, en kan als volgt geschreven worden qua populatie parameters:") Hoofdstuk 4 4.1 De ANCOVA is een vorm van statistische controle, en was specifiek ontworpen om on-uitgelegde foutvariatie ( error variation ) te verminderen. Om dit te doen is er een co-variabele ( covariate
Hoofdstuk 4 4.1 De ANCOVA is een vorm van statistische controle, en was specifiek ontworpen om on-uitgelegde foutvariatie ( error variation ) te verminderen. Om dit te doen is er een co-variabele ( covariate
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica. Tentamen Statistiek II voor TeMa (2S195) op maandag ,
 op maandag ,") TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek II voor TeMa (2S195) op maandag 8-5-26, 9.-12. uur Bij het tentamen mag gebruik worden gemaakt van een (grafisch)
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek II voor TeMa (2S195) op maandag 8-5-26, 9.-12. uur Bij het tentamen mag gebruik worden gemaakt van een (grafisch)
11. Meerdere gemiddelden vergelijken, ANOVA
 11. Meerdere gemiddelden vergelijken, ANOVA Analyse van variantie (ANOVA) wordt gebruikt wanneer er situaties zijn waarbij er meer dan twee condities vergeleken worden. In dit hoofdstuk wordt de onafhankelijke
11. Meerdere gemiddelden vergelijken, ANOVA Analyse van variantie (ANOVA) wordt gebruikt wanneer er situaties zijn waarbij er meer dan twee condities vergeleken worden. In dit hoofdstuk wordt de onafhankelijke
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor T (2S070) op vrijdag 8 oktober 1999, uur De u
 op vrijdag 8 oktober 1999, uur De u") TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor T (2S070) op vrijdag 8 oktober 1999, 14.00-17.00 uur De uitwerkingen van de opgaven dienen duidelijk geformuleerd
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor T (2S070) op vrijdag 8 oktober 1999, 14.00-17.00 uur De uitwerkingen van de opgaven dienen duidelijk geformuleerd
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica. Tentamen Statistiek 2 voor TeMa (2S195) op dinsdag ,
 op dinsdag ,") TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek 2 voor TeMa (2S95) op dinsdag 5-03-2005, 9.00-22.00 uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek 2 voor TeMa (2S95) op dinsdag 5-03-2005, 9.00-22.00 uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
toetskeuze schema verschillen in gemiddelden
 toetsende statistiek week 1: kansen en random variabelen week 2: de steekproevenverdeling week 3: schatten en toetsen: de z-toets week 4: het toetsen van gemiddelden: de t-toets week 5: het toetsen van
toetsende statistiek week 1: kansen en random variabelen week 2: de steekproevenverdeling week 3: schatten en toetsen: de z-toets week 4: het toetsen van gemiddelden: de t-toets week 5: het toetsen van
gemiddelde politieke interesse van hoger opgeleide mensen)
") SPSS-oefening 2: Hypothesetoetsen Opgave Oefening 1 a) Het zijn onafhankelijke steekproeven. De scores voor politieke interesse zijn afkomstig van verschillende mensen aangezien elke persoon slechts in
SPSS-oefening 2: Hypothesetoetsen Opgave Oefening 1 a) Het zijn onafhankelijke steekproeven. De scores voor politieke interesse zijn afkomstig van verschillende mensen aangezien elke persoon slechts in
EIND TOETS TOEGEPASTE BIOSTATISTIEK I. 3 februari 2012
 EIND TOETS TOEGEPASTE BIOSTATISTIEK I 3 februari 2012 - Dit tentamen bestaat uit vier opgaven onderverdeeld in totaal 27 subvragen. - Geef bij het beantwoorden van de vragen een zo volledig mogelijk antwoord.
EIND TOETS TOEGEPASTE BIOSTATISTIEK I 3 februari 2012 - Dit tentamen bestaat uit vier opgaven onderverdeeld in totaal 27 subvragen. - Geef bij het beantwoorden van de vragen een zo volledig mogelijk antwoord.
Hierbij is het steekproefgemiddelde x_gemiddeld= en de steekproefstandaardafwijking
 Opdracht 9a ----------- t-procedures voor een enkelvoudige steekproef Voor de meting van de leesvaardigheid van kinderen wordt als toets de Degree of Reading Power (DRP) gebruikt. In een onderzoek onder
Opdracht 9a ----------- t-procedures voor een enkelvoudige steekproef Voor de meting van de leesvaardigheid van kinderen wordt als toets de Degree of Reading Power (DRP) gebruikt. In een onderzoek onder
Verband tussen twee variabelen
 Verband tussen twee variabelen Inleiding Dit practicum sluit aan op hoofdstuk I-3 van het statistiekboek en geeft uitleg over het maken van kruistabellen, het berekenen van de correlatiecoëfficiënt en
Verband tussen twee variabelen Inleiding Dit practicum sluit aan op hoofdstuk I-3 van het statistiekboek en geeft uitleg over het maken van kruistabellen, het berekenen van de correlatiecoëfficiënt en
College 6 Eenweg Variantie-Analyse
 College 6 Eenweg Variantie-Analyse - Leary: Hoofdstuk 11, 1 (t/m p. 55) - MM&C: Hoofdstuk 1 (t/m p. 617), p. 63 t/m p. 66 - Aanvullende tekst 6, 7 en 8 Jolien Pas ECO 01-013 Het Experiment: een voorbeeld
College 6 Eenweg Variantie-Analyse - Leary: Hoofdstuk 11, 1 (t/m p. 55) - MM&C: Hoofdstuk 1 (t/m p. 617), p. 63 t/m p. 66 - Aanvullende tekst 6, 7 en 8 Jolien Pas ECO 01-013 Het Experiment: een voorbeeld
2DM71: Eindtoets Biostatistiek, op dinsdag 20 Januari 2015, 13.30-16.30
 Faculteit der Wiskunde en Informatica 2DM71: Eindtoets Biostatistiek, op dinsdag 20 Januari 2015, 13.30-16.30 Opgave 1: (5 x 6 = 30 punten) (Bij deze opgave is gebruik van resultaten uit bijlage 1 noodzakelijk)
Faculteit der Wiskunde en Informatica 2DM71: Eindtoets Biostatistiek, op dinsdag 20 Januari 2015, 13.30-16.30 Opgave 1: (5 x 6 = 30 punten) (Bij deze opgave is gebruik van resultaten uit bijlage 1 noodzakelijk)
16. MANOVA. Overeenkomsten en verschillen met ANOVA. De theorie MANOVA
 16. MANOVA MANOVA Multivariate variantieanalyse (MANOVA) kan gebruikt worden in een situatie waarin je meerdere afhankelijke variabelen hebt. Met MANOVA kan er 1 onafhankelijke variabele gebruikt worden
16. MANOVA MANOVA Multivariate variantieanalyse (MANOVA) kan gebruikt worden in een situatie waarin je meerdere afhankelijke variabelen hebt. Met MANOVA kan er 1 onafhankelijke variabele gebruikt worden
Beknopte handleiding SPSS versie 18.0 1 van 28
 Beknopte handleiding SPSS versie 18.0 1 van 28 Beknopte handleiding SPSS versie 18.0 2 van 28 Inhoudsopgave Inleiding...3 SPSS- tips...4 Kopiëren van datakenmerken...6 Van SPSS naar Excel...7 Opsturen
Beknopte handleiding SPSS versie 18.0 1 van 28 Beknopte handleiding SPSS versie 18.0 2 van 28 Inhoudsopgave Inleiding...3 SPSS- tips...4 Kopiëren van datakenmerken...6 Van SPSS naar Excel...7 Opsturen
Twee en een half jaar Kwaliteitsmeting in de Fysiotherapie
 Twee en een half jaar Kwaliteitsmeting in de Fysiotherapie Feiten en cijfers tot nu toe Managementsamenvatting Na twee en een half jaar kwaliteitsmetingen in de fysiotherapie is het een geschikt moment
Twee en een half jaar Kwaliteitsmeting in de Fysiotherapie Feiten en cijfers tot nu toe Managementsamenvatting Na twee en een half jaar kwaliteitsmetingen in de fysiotherapie is het een geschikt moment
Deel 1: Voorbeeld van beschrijvende analyses in een onderzoeksrapport. Beschrijving van het rookgedrag in Vlaanderen anno 2013
 7.2.4 Voorbeeld van een kwantitatieve analyse (fictief voorbeeld) In onderstaand voorbeeld werken we met fictieve data. Doel van dit voorbeeld is dat je inzicht krijgt in hoe een onderzoeksrapport van
7.2.4 Voorbeeld van een kwantitatieve analyse (fictief voorbeeld) In onderstaand voorbeeld werken we met fictieve data. Doel van dit voorbeeld is dat je inzicht krijgt in hoe een onderzoeksrapport van
Aanpassingen takenboek! Statistische toetsen. Deze persoon in een verdeling. Iedereen in een verdeling
 Kwantitatieve Data Analyse (KDA) Onderzoekspracticum Sessie 2 11 Aanpassingen takenboek! Check studienet om eventuele verbeteringen te downloaden! Huidige versie takenboek: 09 Gjalt-Jorn Peters gjp@ou.nl
Kwantitatieve Data Analyse (KDA) Onderzoekspracticum Sessie 2 11 Aanpassingen takenboek! Check studienet om eventuele verbeteringen te downloaden! Huidige versie takenboek: 09 Gjalt-Jorn Peters gjp@ou.nl
Nominaal Ordinaal Interval (ratio) Nominaal - Kwalitatief - Laagste niveau - Categorieën niet ordenen - Geslacht
 Nominaal - Kwalitatief - Laagste niveau - Categorieën niet ordenen - Geslacht") Nominaal - Kwalitatief - Laagste niveau - Categorieën niet ordenen - Geslacht Ordinaal - Kwalitatief - Middelste niveau - Categorieën wel ordenen - Opleidingsniveau Interval / ratio - Kwantitatief - Hoogste
Nominaal - Kwalitatief - Laagste niveau - Categorieën niet ordenen - Geslacht Ordinaal - Kwalitatief - Middelste niveau - Categorieën wel ordenen - Opleidingsniveau Interval / ratio - Kwantitatief - Hoogste
Bestaat er een betekenisvol verband tussen het geslacht en het voorkomen van dyslexie? Gebruik de Chi-kwadraattoets voor kruistabellen.
 Oplossingen hoofdstuk IX 1. Bestaat er een verband tussen het geslacht en het voorkomen van dyslexie? Uit een aselecte steekproef van 00 leerlingen (waarvan 50% jongens en 50% meisjes) uit het basisonderwijs
Oplossingen hoofdstuk IX 1. Bestaat er een verband tussen het geslacht en het voorkomen van dyslexie? Uit een aselecte steekproef van 00 leerlingen (waarvan 50% jongens en 50% meisjes) uit het basisonderwijs
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica. Tentamen Statistiek 2 voor TeMa (2S195) op maandag ,
 op maandag ,") TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek 2 voor TeMa (2S95) op maandag 08-03-2004, 9.00-2.00 uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine,
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek 2 voor TeMa (2S95) op maandag 08-03-2004, 9.00-2.00 uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine,
1. Reductie van error variantie en dus verhogen van power op F-test
 Werkboek 2013-2014 ANCOVA Covariantie analyse bestaat uit regressieanalyse en variantieanalyse. Er wordt een afhankelijke variabele (intervalniveau) voorspeld uit meerdere onafhankelijke variabelen. De
Werkboek 2013-2014 ANCOVA Covariantie analyse bestaat uit regressieanalyse en variantieanalyse. Er wordt een afhankelijke variabele (intervalniveau) voorspeld uit meerdere onafhankelijke variabelen. De
d. Formuleer voor het hoofdeffect Afmeting H_0 en H_a. Is dit hoofdeffect significant?
 Opdracht 14a ------------ Twee-factor ANOVA In een groot research-project bestudeerde men de fysische eigenschappen van multiplex houtmaterialen, vervaardigd door kleine plakjes hout aan elkaar te hechten.
Opdracht 14a ------------ Twee-factor ANOVA In een groot research-project bestudeerde men de fysische eigenschappen van multiplex houtmaterialen, vervaardigd door kleine plakjes hout aan elkaar te hechten.
Fasen in het onderzoeksproces
 Fasen in het onderzoeksproces Gegevensbestand Controleren gegevens Bewerken gegevens Analyseren gegevens Interpreteren resultaten Nieuwe vragen? ja Onderzoeksverslag 1 Bestand opmaken Variabelen definiëren:
Fasen in het onderzoeksproces Gegevensbestand Controleren gegevens Bewerken gegevens Analyseren gegevens Interpreteren resultaten Nieuwe vragen? ja Onderzoeksverslag 1 Bestand opmaken Variabelen definiëren:
Resultaten smaaksessie in kader van GOT-kit: bepalen concentratieniveaus
 VERSLAG LEUVEN Resultaten smaaksessie in kader van GOT-kit: bepalen concentratieniveaus 1 Inleiding Het Center for Gastrology in Leuven is een onafhankelijk centrum dat een fundamentele verandering in
VERSLAG LEUVEN Resultaten smaaksessie in kader van GOT-kit: bepalen concentratieniveaus 1 Inleiding Het Center for Gastrology in Leuven is een onafhankelijk centrum dat een fundamentele verandering in
Kruis per vraag slechts één vakje aan op het antwoordformulier.
 Toets Stroom 1.2 Methoden en Statistiek tul, MLW 7 april 2006 Deze toets bestaat uit 25 vierkeuzevragen. Kruis per vraag slechts één vakje aan op het antwoordformulier. Vraag goed beantwoord dan punt voor
Toets Stroom 1.2 Methoden en Statistiek tul, MLW 7 april 2006 Deze toets bestaat uit 25 vierkeuzevragen. Kruis per vraag slechts één vakje aan op het antwoordformulier. Vraag goed beantwoord dan punt voor
Voorbeeld regressie-analyse
 Voorbeeld regressie-analyse In dit voorbeeld wordt gebruik gemaakt van het SPSS data-bestand vb_regr.sav (dit bestand kan gedownload worden via de on-line helpdesk). We schatten een model waarin de afhankelijke
Voorbeeld regressie-analyse In dit voorbeeld wordt gebruik gemaakt van het SPSS data-bestand vb_regr.sav (dit bestand kan gedownload worden via de on-line helpdesk). We schatten een model waarin de afhankelijke
toetsende statistiek deze week: wat hebben we al geleerd? Frank Busing, Universiteit Leiden
 toetsende statistiek week 1: kansen en random variabelen week 2: de steekproevenverdeling week 3: schatten en toetsen: de z-toets week 4: het toetsen van gemiddelden: de t-toets Moore, McCabe, and Craig.
toetsende statistiek week 1: kansen en random variabelen week 2: de steekproevenverdeling week 3: schatten en toetsen: de z-toets week 4: het toetsen van gemiddelden: de t-toets Moore, McCabe, and Craig.
Oplossingen hoofdstuk 9
 Oplossingen hoofdstuk 9 1. Bestaat er een verband tussen het geslacht en het voorkomen van dyslexie? Uit een aselecte steekproef van 200 leerlingen (waarvan 50% jongens en 50% meisjes) uit het basisonderwijs
Oplossingen hoofdstuk 9 1. Bestaat er een verband tussen het geslacht en het voorkomen van dyslexie? Uit een aselecte steekproef van 200 leerlingen (waarvan 50% jongens en 50% meisjes) uit het basisonderwijs
9. Lineaire Regressie en Correlatie
 9. Lineaire Regressie en Correlatie Lineaire verbanden In dit hoofdstuk worden methoden gepresenteerd waarmee je kwantitatieve respons variabelen (afhankelijk) en verklarende variabelen (onafhankelijk)
9. Lineaire Regressie en Correlatie Lineaire verbanden In dit hoofdstuk worden methoden gepresenteerd waarmee je kwantitatieve respons variabelen (afhankelijk) en verklarende variabelen (onafhankelijk)
Dit jaar gaan we MULTIVARIAAT TOETSEN. Bijvoorbeeld: We willen zien of de scores op taal en rekenen van kinderen afwijken in de populatie.
 Toetsen van hypothesen Bijvoorbeeld: nagaan of het gemiddeld IQ bij een bepaalde steekproef groter/kleiner is als in de populatie. µ = 100 Normaalverdeling, waarbij we de score van de steekproef gaan vergelijken
Toetsen van hypothesen Bijvoorbeeld: nagaan of het gemiddeld IQ bij een bepaalde steekproef groter/kleiner is als in de populatie. µ = 100 Normaalverdeling, waarbij we de score van de steekproef gaan vergelijken
Onderzoek. B-cluster BBB-OND2B.2
 Onderzoek B-cluster BBB-OND2B.2 Succes met leren Leuk dat je onze bundels hebt gedownload. Met deze bundels hopen we dat het leren een stuk makkelijker wordt. We proberen de beste samenvattingen voor jou
Onderzoek B-cluster BBB-OND2B.2 Succes met leren Leuk dat je onze bundels hebt gedownload. Met deze bundels hopen we dat het leren een stuk makkelijker wordt. We proberen de beste samenvattingen voor jou
Het gebruik van SPSS voor statistische analyses. Een beknopte handleiding.
 Het gebruik van SPSS voor statistische analyses. Een beknopte handleiding. SPSS is een alom gebruikt, gebruiksvriendelijk statistisch programma dat vele analysemogelijkheden kent. Voor HBO en universitaire
Het gebruik van SPSS voor statistische analyses. Een beknopte handleiding. SPSS is een alom gebruikt, gebruiksvriendelijk statistisch programma dat vele analysemogelijkheden kent. Voor HBO en universitaire
Regressie-analyse doel menu hulp globale werkwijze aandachtspunten Doel: Voor de uitvoering in SPSS: Missing Values Globale werkwijze
 Regressie-analyse Regressie-analyse is gericht op het voorspellen van één (numerieke) afhankelijke variabele met behulp van een of meerdere onafhankelijke variabelen (numerieke en/of dummy-variabelen).
Regressie-analyse Regressie-analyse is gericht op het voorspellen van één (numerieke) afhankelijke variabele met behulp van een of meerdere onafhankelijke variabelen (numerieke en/of dummy-variabelen).
INDUCTIEVE STATISTIEK
 INDUCTIEVE STATISTIEK Toegepaste hypothesetoetsing met SPSS Tim Vanhoomissen 1 Workshop Inductieve Statistiek INHOUD Hypothesetoetsing Principe van hypothesetoetsing Steekproevenverdeling Centrale limiet
INDUCTIEVE STATISTIEK Toegepaste hypothesetoetsing met SPSS Tim Vanhoomissen 1 Workshop Inductieve Statistiek INHOUD Hypothesetoetsing Principe van hypothesetoetsing Steekproevenverdeling Centrale limiet
S0A17D: Examen Sociale Statistiek (deel 2)
") S0A17D: Examen Sociale Statistiek (deel 2) 21 juni 2011 Naam : Jaar en studierichting : Lees volgende aanwijzingen eerst voor het examen te beginnen : Wie de vragen aanneemt en bekijkt, moet minstens 1
S0A17D: Examen Sociale Statistiek (deel 2) 21 juni 2011 Naam : Jaar en studierichting : Lees volgende aanwijzingen eerst voor het examen te beginnen : Wie de vragen aanneemt en bekijkt, moet minstens 1
Methoden van Onderzoek en Statistiek, Deeltentamen 2, 29 maart 2012 Versie 2
 Vraag 1. Voor welk van de onderstaande variabelen zal een placebo effect waarschijnlijk het grootst zijn? 1. Haarlengte. 2. Lichaamstemperatuur. 3. Mate van tevredenheid met de behandeling. 4. Hemoglobinegehalte
Vraag 1. Voor welk van de onderstaande variabelen zal een placebo effect waarschijnlijk het grootst zijn? 1. Haarlengte. 2. Lichaamstemperatuur. 3. Mate van tevredenheid met de behandeling. 4. Hemoglobinegehalte
Eindtoets Toegepaste Biostatistiek
 Eindtoets Toegepaste Biostatistiek 2013-2014 29 januari 2014 Dit tentamen bestaat uit vier opgaven, onderverdeeld in 24 subvragen. Begin bij het maken van een nieuwe opgave steeds op een nieuw antwoordvel.
Eindtoets Toegepaste Biostatistiek 2013-2014 29 januari 2014 Dit tentamen bestaat uit vier opgaven, onderverdeeld in 24 subvragen. Begin bij het maken van een nieuwe opgave steeds op een nieuw antwoordvel.
Vandaag. Onderzoeksmethoden: Statistiek 3. Recap 2. Recap 1. Recap Centrale limietstelling T-verdeling Toetsen van hypotheses
 Vandaag Onderzoeksmethoden: Statistiek 3 Peter de Waal (gebaseerd op slides Peter de Waal, Marjan van den Akker) Departement Informatica Beta-faculteit, Universiteit Utrecht Recap Centrale limietstelling
Vandaag Onderzoeksmethoden: Statistiek 3 Peter de Waal (gebaseerd op slides Peter de Waal, Marjan van den Akker) Departement Informatica Beta-faculteit, Universiteit Utrecht Recap Centrale limietstelling
c Voorbeeldvragen, Methoden & Technieken, Universiteit Leiden TS: versie 1 1 van 6
 c Voorbeeldvragen, Methoden & Technieken, Universiteit Leiden TS: versie 1 1 van 6 1. Iemand kiest geblinddoekt 4 paaseitjes uit een mand met oneindig veel paaseitjes. De helft is melkchocolade, de andere
c Voorbeeldvragen, Methoden & Technieken, Universiteit Leiden TS: versie 1 1 van 6 1. Iemand kiest geblinddoekt 4 paaseitjes uit een mand met oneindig veel paaseitjes. De helft is melkchocolade, de andere
Technische uitwerkingen voor het SPSS practicum Toetsende Statistiek
 Technische uitwerkingen voor het SPSS practicum Toetsende Statistiek NB Voor de SPSS opgaven wordt alleen aangegeven hoe het door de opgave gevraagde resultaat kan worden bereikt. C. J. Verduin 11 december
Technische uitwerkingen voor het SPSS practicum Toetsende Statistiek NB Voor de SPSS opgaven wordt alleen aangegeven hoe het door de opgave gevraagde resultaat kan worden bereikt. C. J. Verduin 11 december
Statistiek Hoorcollege 5. Χ 2 toets 10/7/2009. De Collegereeks Statistiek. Deze week. Vandaag. Keuze voor een toets
 10/7/009 De Collegereeks Statistiek Informatiekunde Universiteit Utrecht Dr. H. Prüst Statistiek Hoorcollege 5 Χ toets (37): Descriptieve statistiek (H 1,,3) (HP) 3(38): Score & Kans verdelingen (H 4,
10/7/009 De Collegereeks Statistiek Informatiekunde Universiteit Utrecht Dr. H. Prüst Statistiek Hoorcollege 5 Χ toets (37): Descriptieve statistiek (H 1,,3) (HP) 3(38): Score & Kans verdelingen (H 4,
Residual Plot for Strength. predicted Strength
 Uitwerking tentamen DS mei 4 Opgave Een uitwerking geven is hier niet mogelijk. Het is van belang het iteratieve optimaliseringsproces goed uit te voeren (zie ook de PowerPoint sheets): screening design
Uitwerking tentamen DS mei 4 Opgave Een uitwerking geven is hier niet mogelijk. Het is van belang het iteratieve optimaliseringsproces goed uit te voeren (zie ook de PowerPoint sheets): screening design
Oplossingen hoofdstuk XI
 Oplossingen hoofdstuk XI. Hierbij vind je de resultaten van het onderzoek naar de relatie tussen een leestest en een schoolrapport voor lezen. Deze gegevens hebben betrekking op een regressieanalyse bij
Oplossingen hoofdstuk XI. Hierbij vind je de resultaten van het onderzoek naar de relatie tussen een leestest en een schoolrapport voor lezen. Deze gegevens hebben betrekking op een regressieanalyse bij
Statistiek II. Sessie 4. Feedback Deel 4
 Statistiek II Sessie 4 Feedback Deel 4 VPPK Universiteit Gent 2017-2018 Feedback Oefensessie 4 We hebben besloten de bekomen grafieken in R niet in het document in te voegen, dit omdat het document met
Statistiek II Sessie 4 Feedback Deel 4 VPPK Universiteit Gent 2017-2018 Feedback Oefensessie 4 We hebben besloten de bekomen grafieken in R niet in het document in te voegen, dit omdat het document met
Het samenstellen van een multipele indicator index. Harry B.G. Ganzeboom ADEK UvS College 2 28 februari 2011
 Het samenstellen van een multipele indicator index Harry B.G. Ganzeboom ADEK UvS College 2 28 februari 2011 Indices voor attituden Attittuden (opvattingen) zijn complexe kenmerken Moeilijk te meten met
Het samenstellen van een multipele indicator index Harry B.G. Ganzeboom ADEK UvS College 2 28 februari 2011 Indices voor attituden Attittuden (opvattingen) zijn complexe kenmerken Moeilijk te meten met
Deze menu-aansturingen zijn van toepassing op versies 14.0 en 15.0 van SPSS.
 Menu aansturing van SPSS voorbeeld in hoofdstuk 8 over schaalconstructie met Cronbach s α en principale componenten analyse van meningen over strafdoelen Hieronder wordt uitgelegd hoe alle analyses besproken
Menu aansturing van SPSS voorbeeld in hoofdstuk 8 over schaalconstructie met Cronbach s α en principale componenten analyse van meningen over strafdoelen Hieronder wordt uitgelegd hoe alle analyses besproken
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica. Tentamen Biostatistiek voor BMT (2S390) op maandag ,
 op maandag ,") TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Biostatistiek voor BMT (2S390) op maandag 19-11-2001, 14.00-17.00 uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Biostatistiek voor BMT (2S390) op maandag 19-11-2001, 14.00-17.00 uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
DE IMPACT VAN (CONSUMENTEN)RACISME OP DE EFFECTIVITEIT VAN BLANKE EN NIET- BLANKE (CELEBRITY) ENDORSERS IN RECLAME
RACISME OP DE EFFECTIVITEIT VAN BLANKE EN NIET- BLANKE (CELEBRITY) ENDORSERS IN RECLAME") UNIVERSITEIT GENT FACULTEIT ECONOMIE EN BEDRIJFSKUNDE ACADEMIEJAAR 2010 2011 DE IMPACT VAN (CONSUMENTEN)RACISME OP DE EFFECTIVITEIT VAN BLANKE EN NIET- BLANKE (CELEBRITY) ENDORSERS IN RECLAME Masterproef
UNIVERSITEIT GENT FACULTEIT ECONOMIE EN BEDRIJFSKUNDE ACADEMIEJAAR 2010 2011 DE IMPACT VAN (CONSUMENTEN)RACISME OP DE EFFECTIVITEIT VAN BLANKE EN NIET- BLANKE (CELEBRITY) ENDORSERS IN RECLAME Masterproef
Motorische vaardigheden in de gymzaal primair onderwijs
 Motorische vaardigheden in de gymzaal primair onderwijs Naam: Martijn de Vries Studentnummer: 500689810 Onderzoeksthema: Meten van motoriek ACADEMIE voor LICHAMELIJKE OPVOEDING Hogeschool van Amsterdam
Motorische vaardigheden in de gymzaal primair onderwijs Naam: Martijn de Vries Studentnummer: 500689810 Onderzoeksthema: Meten van motoriek ACADEMIE voor LICHAMELIJKE OPVOEDING Hogeschool van Amsterdam
Toegepaste data-analyse: oefensessie 2
 Toegepaste data-analyse: oefensessie 2 Depressie 1. Beschrijf de clustering van de dataset en geef aan op welk niveau de verschillende variabelen behoren Je moet weten hoe de data geclusterd zijn om uit
Toegepaste data-analyse: oefensessie 2 Depressie 1. Beschrijf de clustering van de dataset en geef aan op welk niveau de verschillende variabelen behoren Je moet weten hoe de data geclusterd zijn om uit
Betrouwbaarheid, validiteit en overeenstemming
 Betrouwbaarheid, validiteit en overeenstemming Inleiding Dit practicum sluit aan op het theoriegedeelte over betrouwbaarheidsanalyse van hoofdstuk II-16 (deel 2). In dit hoofdstuk wordt besproken hoe een
Betrouwbaarheid, validiteit en overeenstemming Inleiding Dit practicum sluit aan op het theoriegedeelte over betrouwbaarheidsanalyse van hoofdstuk II-16 (deel 2). In dit hoofdstuk wordt besproken hoe een
Inhoud. Data. Analyse van tijd tot event data: van Edward Kaplan & Paul Meier tot David Cox
 van tijd tot event data: van Edward Kaplan & Paul Meier tot David Cox Bram Ramaekers Bianca de Greef KEMTA Masterclass Inhoud Data Kaplan-Meier curve Hazard rate Log-rank test Hazard ratio Cox regressie
van tijd tot event data: van Edward Kaplan & Paul Meier tot David Cox Bram Ramaekers Bianca de Greef KEMTA Masterclass Inhoud Data Kaplan-Meier curve Hazard rate Log-rank test Hazard ratio Cox regressie
APPENDIX B: Statistische analyses
 APPENDIX B: Statistische analyses Het gevoerde empirisch onderzoek was erop gericht te onderzoeken of het gebruikelijk is dat wanneer een kunstgalerie met een kunstenaar samenwerkt, de kunstwerken eigendom
APPENDIX B: Statistische analyses Het gevoerde empirisch onderzoek was erop gericht te onderzoeken of het gebruikelijk is dat wanneer een kunstgalerie met een kunstenaar samenwerkt, de kunstwerken eigendom
Hoofdstuk 8. Toetsende statistiek. 8.1 Associatie van categoriale data: CROSSTABS [dv 32.2]
![Hoofdstuk 8. Toetsende statistiek. 8.1 Associatie van categoriale data: CROSSTABS [dv 32.2]](/thumbs/40/20645084.jpg "Hoofdstuk 8. Toetsende statistiek. 8.1 Associatie van categoriale data: CROSSTABS [dv 32.2]") Hoofdstuk 8 Toetsende statistiek Meestal zijn we niet alleen geïnteresseerd in beschrijvende statistiek (over de steekproef), maar ook in toetsende statistiek. Het doel hiervan is om hypothesen te toetsen,
Hoofdstuk 8 Toetsende statistiek Meestal zijn we niet alleen geïnteresseerd in beschrijvende statistiek (over de steekproef), maar ook in toetsende statistiek. Het doel hiervan is om hypothesen te toetsen,
* de percentages goed per klas en volgorde van afnemen. sort cases by klas volgorde. split file by klas volgorde. des var=goedboekperc.
 * Sprekende voorbeelden. * De invloed van lessen op meerkeuzetoetsen Natuurkunde, klas 5 en 6 * Manfred te Grotenhuis en Nico van de Mortel * we gaan uit van de folder 'temp'op de c-drive, svp wijzigen
* Sprekende voorbeelden. * De invloed van lessen op meerkeuzetoetsen Natuurkunde, klas 5 en 6 * Manfred te Grotenhuis en Nico van de Mortel * we gaan uit van de folder 'temp'op de c-drive, svp wijzigen
Berekenen en gebruik van Cohen s d Cohen s d is een veelgebruikte manier om de effectgrootte te berekenen en wordt
 A. Effect & het onderscheidingsvermogen Effectgrootte (ES) De effectgrootte (effect size) vertelt ons iets over hoe relevant de relatie tussen twee variabelen is in de praktijk. Er zijn twee soorten effectgrootten:
A. Effect & het onderscheidingsvermogen Effectgrootte (ES) De effectgrootte (effect size) vertelt ons iets over hoe relevant de relatie tussen twee variabelen is in de praktijk. Er zijn twee soorten effectgrootten:
Wetenschappelijk Onderzoek: Experimenteel Onderzoek
 Programma Wetenschappelijk Onderzoek: Experimenteel Onderzoek Pieter Wouters 1. Kenmerken van experimenten 2. Het selecteren van onderzoekseenheden 3. Experimentele designs 4. Validiteit van experimenten
Programma Wetenschappelijk Onderzoek: Experimenteel Onderzoek Pieter Wouters 1. Kenmerken van experimenten 2. Het selecteren van onderzoekseenheden 3. Experimentele designs 4. Validiteit van experimenten
Vergelijken van twee groepen (SPSS)
") Vergelijken van twee groepen (SPSS) Vergelijking van gemiddeldes van onafhankelijke steekproeven met gelijke varianties (dataset newspapers) In een onderzoek geven studenten aan hoeveel keer per week ze
Vergelijken van twee groepen (SPSS) Vergelijking van gemiddeldes van onafhankelijke steekproeven met gelijke varianties (dataset newspapers) In een onderzoek geven studenten aan hoeveel keer per week ze
!!! Help! Statistiek! Overzicht. Data, computers, statistiek. Statistische programma s. Excel: hoe is het mogelijk? Excel: hoeveel is 1+1?
 Help! Statistiek! Overzicht Doorlopende serie laagdrempelige lezingen, voor iedereen vrij toegankelijk. Doel: Informeren over statistiek in klinisch onderzoek. - statistische programma s - tips SPSS Tijd:
Help! Statistiek! Overzicht Doorlopende serie laagdrempelige lezingen, voor iedereen vrij toegankelijk. Doel: Informeren over statistiek in klinisch onderzoek. - statistische programma s - tips SPSS Tijd:
Statistiek II. Sessie 5. Feedback Deel 5
 Statistiek II Sessie 5 Feedback Deel 5 VPPK Universiteit Gent 2017-2018 Feedback Oefensessie 5 1 Statismex, gewicht en slaperigheid2 1. Lineair model: slaperigheid2 = β 0 + β 1 dosis + β 2 bd + ε H 0 :
Statistiek II Sessie 5 Feedback Deel 5 VPPK Universiteit Gent 2017-2018 Feedback Oefensessie 5 1 Statismex, gewicht en slaperigheid2 1. Lineair model: slaperigheid2 = β 0 + β 1 dosis + β 2 bd + ε H 0 :
Tentamen Biostatistiek 1 voor BMT (2DM40) woensdag 28 oktober 2009, 9.00-12.00 uur
 woensdag 28 oktober 2009, 9.00-12.00 uur") Faculteit der Wiskunde en Informatica Tentamen Biostatistiek voor BMT (DM4) woensdag 8 oktober 9, 9.-. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en van een onbeschreven Statistisch
Faculteit der Wiskunde en Informatica Tentamen Biostatistiek voor BMT (DM4) woensdag 8 oktober 9, 9.-. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en van een onbeschreven Statistisch
Oefenvragen bij Statistics for Business and Economics van Newbold
 Oefenvragen bij Statistics for Business and Economics van Newbold Hoofdstuk 1 1. Wat is het verschil tussen populatie en sample? De populatie is de complete set van items waar de onderzoeker in geïnteresseerd
Oefenvragen bij Statistics for Business and Economics van Newbold Hoofdstuk 1 1. Wat is het verschil tussen populatie en sample? De populatie is de complete set van items waar de onderzoeker in geïnteresseerd
Basishandleiding SPSS
 Basishandleiding SPSS Elvira Folmer & Marieke ten Voorde SLO, Juli 2008 Deze handleiding is gebaseerd op SPSS 16.0 for Windows Inhoud 1 Het maken van een gegevensbestand in de Variable View... 4 2 Het
Basishandleiding SPSS Elvira Folmer & Marieke ten Voorde SLO, Juli 2008 Deze handleiding is gebaseerd op SPSS 16.0 for Windows Inhoud 1 Het maken van een gegevensbestand in de Variable View... 4 2 Het
EIND TOETS TOEGEPASTE BIOSTATISTIEK I. 5 februari 2010
 EIND TOETS TOEGEPASTE BIOSTATISTIEK I 5 februari - Dit tentamen bestaat uit vier opgaven onderverdeeld in totaal 9 subvragen. - Geef bij het beantwoorden van de vragen een zo volledig mogelijk antwoord.
EIND TOETS TOEGEPASTE BIOSTATISTIEK I 5 februari - Dit tentamen bestaat uit vier opgaven onderverdeeld in totaal 9 subvragen. - Geef bij het beantwoorden van de vragen een zo volledig mogelijk antwoord.
Menu aansturing van SPSS voorbeeld in paragraaf 6.5 van hoofdstuk 6 over multipele regressie analyses van recidive bij jongens
 Menu aansturing van SPSS voorbeeld in paragraaf 6.5 van hoofdstuk 6 over multipele regressie analyses van recidive bij jongens Hieronder wordt uitgelegd hoe alle analyses besproken in paragraaf 6.5 van
Menu aansturing van SPSS voorbeeld in paragraaf 6.5 van hoofdstuk 6 over multipele regressie analyses van recidive bij jongens Hieronder wordt uitgelegd hoe alle analyses besproken in paragraaf 6.5 van