Statistiek I Semester 2
|
|
|
- Lieven Dekker
- 6 jaren geleden
- Aantal bezoeken:
Transcriptie
 Machtsverzameling M = De verzameling")
1 Statistiek I Semester 2 Hoofdstuk 1 Axiomatische kansrekening Basisbegrippen Stochastisch proces = Proces met onzekere uitkomst Toevalsgebeuren = Uitkomst stochastisch proces o Elementair = slecht 1 uitkomst o Samengesteld = meerdere uitkomsten Kans = Mogelijkheid dat een bepaald toevalsgebeuren plaatsvindt Uitkomstenruimte S = # Mogelijke = (sample space) Machtsverzameling M = De verzameling van alle mogelijke elementaire en samengestelde toevalsgebeurens die men kan definiëren op basis van een S M(S) = 2 n Kansdefinitie van Laplace = # gunstige / # mogelijke (alleen gebruiken als alle uitkomsten even waarschijnlijk zijn) = en/of = zowel A B betekent: de verzameling die alle elementen bevat die in A en/of in B zitten A B betekent: De verzameling die alle elementen bevat, die zowel in A als in B zitten Complementregel P (A c ) = 1 P(A) Somregel indien A en B disjunct (dus A B = Ø) P (A B) = P(A) + P(B) Somregel indien A en B níet disjunct P (A B) = P(A) + P(B) P (A B) Productregel bij statistisch onafhankelijkheid (als P(A B) = P(A) en P(B A) = P(B)) P (A B) = P(A) * P(B) Productregel bij statistisch afhankelijkheid P (A B) = P(A B) * P(B) = P(B A) * P (A) indien twijfel -> kies afhankelijk Regel van de totale kans Regel van Bayes 1
![Regel van de voorwaardelijke kans Hoofdstuk 2 Kansverdelingen Checklist kansverdeling P[X=x] 1 (alle kansen tussen en 1) P[X=x] =](/docs-images/63/48647400/images/2-0.jpg "1 (som van alle kansen is 1) Stochasten & kansverdelingen Stochast - Is een variabele waarvan de waarde een numerieke uitkomst is")

![Kansverdeling - Discreet: kansfunctie - Continu: kansdichtheidsfunctie Gecumuleerde kansen (%) Bottom-up: P[X x] Top-down: P[X x]](/docs-images/63/48647400/images/2-2.jpg "Verwachtingswaarde (= gemiddelde van kansen) k µ = EX ( ) = xpx.")
2 Regel van de voorwaardelijke kans Hoofdstuk 2 Kansverdelingen Checklist kansverdeling P[X=x] 1 (alle kansen tussen en 1) P[X=x] = 1 (som van alle kansen is 1) Stochasten & kansverdelingen Stochast - Is een variabele waarvan de waarde een numerieke uitkomst is van een toevalsverschijnsel - Is een functie die de elementaire uitkomsten van een bepaald toevalsverschijnsel verbindt met een numerieke waarde. Kansverdeling - Discreet: kansfunctie - Continu: kansdichtheidsfunctie Gecumuleerde kansen (%) Bottom-up: P[X x] Top-down: P[X x] Verwachtingswaarde (= gemiddelde van kansen) k µ = EX ( ) = xpx. = x i= 1 Variantie (= spreiding van de stochast) i [ ] i Rekenkundige variant: Lineair getransformeerde stochasten E(a + bx) = a + b * E(X) Var(a + bx) = b 2 * Var(X) waarbij 2
3 Verwachting en variantie van een som van stochasten Voor alle stochasten E(Z) = E(X+Y) = E(X) + E(Y) E(Z) = E(X*Y) = E(X) * E(Y) + Cov(XY) Var(Z) = Var(X+Y) = Var(X) + Var(Y) + Cov(XY) Enkel voor onafhankelijke stochasten (want dan geldt: Cov(XY) = ) E(Z) = E(X*Y) = E(X) * E(Y) Var(Z) = Var(X+Y) = Var(X) + Var(Y) Geldt nóóit: σ(z) = σ(x+y) σ(x) + σ(y) Geen covariantie = de relatieve omvang van een waarde voor de ene stochast zegt niets over de relatieve omvang van de corresponderende waarde voor een andere stochast. Afhankelijk of onafhankelijk beredeneren met: Productregel óf Voorwaardelijke kansen Toepassingen Kansverdeling bepalen 1. Uitkomstenruimte bepalen a. Kruistabel (bij twee dichotome stochasten). b. Op de rij & kolom staan de mogelijke uitkomsten 2. Verbinden v / d uitkomst met waarden van stochast en kansen a. Kansverdeling (kansfunctie) maken b. (Of P[Y=y], P[X+Y=x+y], P[X*Y=x*y],..) Bij simultane kansverdeling 1) De waarden van X & Y uit de kansverdelingen op de rij en kolom noteren. In de cellen vermenigvuldig je de bijhorende kansen van X en Y. 2) Kansverdeling: alle mogelijke waarden van X en Y de bijhorende kansen optellen en invullen in de kansverdeling (bijv. als X en Y beide t/m 2 > X + Y = t/m 4) Voor stochast X+Y: optellen van de waarden waarvan X + Y =.. o Bijv. X+Y = als X = en Y = Voor stochast X*Y: vermenigvuldigen van de waarden waarvan X * Y = o Bijv. X*Y = als X = en/of Y = o P[X=] + P[Y=] P[X= Y=] o Dus P(X*Y) = P[X=x 1 ] + P[Y=y 1 ] P[X=x 1 Y=y 1 ] 3

![Indien X en Y onafhankelijke stochasten zijn, is de conditionele kansverdeling voor P[X=x Y=] gelijk aan de marginale](/docs-images/63/48647400/images/4-1.jpg "kansverdeling voor P[X=x] Bijv.")
 = $(&'( )'*) $()'*) P(Y=) uit marginale verdeling van Y P(X=1 Y=) uit simultane kansverdeling van X en Y")
4 De conditionele of voorwaardelijke verdeling Je kijkt naar de voorwaardelijke kansverdeling van X, op voorwaarde dat Y een bepaalde waarde heeft. Indien X en Y onafhankelijke stochasten zijn, is de conditionele kansverdeling voor P[X=x Y=] gelijk aan de marginale kansverdeling voor P[X=x] Bijv. Kansverdeling van X op voorwaarde dat Y= à Notatie: X Y= o Uitkomsten à X= Y= ; X=1 Y= ; X=2 Y= o Bijhorende kansen à Vb. P(X=1 Y=) = $(&'( )'*) $()'*) P(Y=) uit marginale verdeling van Y P(X=1 Y=) uit simultane kansverdeling van X en Y Dendogram Hoofdstuk 3 Binomiale verdeling & Hypergeometrische verdeling Steekproeftrekkingen Binomiaal coëfficiënt GR: n invoeren + math / prb / 3: ncr + k invoeren è n ncr k 4
")
5 Binomiale kans n k X ~ B( n; p) P( X = k / n; p) =. p.(1 p) k Waarin: k = aantal successen n = aantal experimenten p = kans op een succes 4 eigenschappen: Vast aantal experimenten n Constante kans op succes p Kansexperimenten zijn onafhankelijk van elkaar Twee alternatieven (succes/mislukking) n k Alles draait om het aantal successen (x) op n experimenten. Een binomiaal verdeelde stochast kan je dus bekijken als de som van de successen op de deelexperimenten. Cumulatieve & enkelvoudige kansen x P[X=x] P[X x] P[X x] Enkelvoudige kansen bottom-up top-down = van laagste naar 1, = van 1, naar laagste Handig bij cumulatieve kansen: zet > & < tekens om in & Bijv. P[X>2] > P[X 3] & P[X<3] > P[X 2] Bernoulliverdeling = Je bekijkt maar 1 deelexperimentje; dit kan je dan vermenigvuldigen met n om de totale kans te berekenen. = discrete kansverdeling met als enige uitkomsten succes of mislukking E[X] = Σx i.p[x=x i ] = 1.p +.q = p E[B] = n.p Var(X) = E[X 2 ]-[E(X)] 2 = p-p 2 = p.(1-p)= p.q Var[B] = n.p.q & σ[y]= n. p. q Binomiale verwachtingswaarde en giscorrectie bij meerkeuzevragen x P[X=x] 1 1/k t (k-1)/k Hoe groot moet de puntenaftrek t zijn om bij een foute gok die onterecht behaalde punten uit de toevallig juiste gok te compenseren (k = aantal uitkomstalternatieven) 5

 1n < N o Benaderen via de binomiale verdeling is acceptabel 1n >")


: Hypergeometrische verdeling ó p zeer klein: Poisson-verdeling kansexperimenten zijn onafhankelijk")
6 De hypergeometrische probleemcontext Géén constante kans op succes p! ð Steekproef zonder teruglegging, dus de vorige steekproefpersonen zijn dan niet langer beschikbaar voor trekking à de kans p is niet constant omdat de teller en noemer dan variëren. Vuistregel (indien steekproef zonder teruglegging) 1n < N o Benaderen via de binomiale verdeling is acceptabel 1n > N o Benaderen via de binomiale verdeling is NIET acceptabel Hypergeometrisch verdeelde stochast Waarbij: n = het aantal experimenten, in casu de trekkingen in de steekproef zonder teruglegging m = het aantal successen in de populatie N = de populatiegrootte s Verwachtingswaarde en variantie Voor X~H(n; m; N) geldt Verschil binomiale verdeling & andere verdelingen vast aantal experimenten n ó nde experiment eerste succes: Geometrische verdeling ó nde experiment k-de succes: Pascalverdeling constante kans p op een succes bij elk experiment ó p varieert (zonder teruglegging): Hypergeometrische verdeling ó p zeer klein: Poisson-verdeling kansexperimenten zijn onafhankelijk van elkaar 2 antwoordalternatieven (succes/mislukking) ó meer dan 2 categorieën: Multinomiale verdeling 6
 Spiegelen Stel kans op succes >,5 à staat niet in")
7 De Poisson-verdeling Gaat uit van een continu en dus onbegrensde tijdsruimte of fysieke ruimte (à zeer grote n) Kans op succes bij één deelexperiment is zeer klein (p) Kansfunctie: o o Waarbij k = aantal gezochte successen λ = n * p = het te verwachten aantal successen binnen de onderzochte tijdsruimte of fysieke ruimte (enige parameter hier) Spiegelen Stel kans op succes >,5 à staat niet in de tabel. Dan moet je gaan spiegelen = verdeling omzetten in de bijhorende kans op een x aantal mislukkingen Bijv. indien de kans op 5 successen bij n = 15 à omzetten in mislukken bij n = 15 ð Máár het wordt ingewikkeld zodra het geen exacte kans is. Tip: één voor één je getallen spiegelen. Bijv. 7 of meer successen spiegelen ( v / d 8) = 1 of minder mislukkingen Hoofdstuk 4 De Normale verdeling Kansdichtheidsfunctie van de normale verdeling Normale verdeling symbolisch: X~N(μ,σ) μ = het rekenkundig gemiddelde σ = de standaardafwijking Eigenschappen van de normale verdeling Continue verdeling (enige dit semester) Gekenmerkt door 2 parameters: o Positieparameter μ (`het gemiddelde ) o Vormparameter σ (`de standaardafwijking ) N(µ,σ) Eéntoppig, met als top: (stel x = µ) 1 ( µ, ) = ( µ, σ 1,4) σ 2π Symmetrisch rond de positieparameter μ o μ = Mo = Me = E[X] Klokvormig o Buigpunten bij μ-σ en μ+σ o Dichtheidskromme dijt asymptotisch uit naar - en + 7
 of φ(z) Kenmerken voor standaardnormale verdeling (preciezer geformuleerd) De standaardnormale dichtheidskromme bereikt een unieke top als Z = (want μ z = ).")
![De ordinaatwaarde bedraagt hier 1/ (2π),4 (want σ z = 1) μ = Mo = Me = E[X] à = De 2 buigpunten situeren zich ditmaal bij Z = -1 en bij Z = +1 (want μ-σ = -1 en μ+σ = +1) Verdelingsfunctie van de](/docs-images/63/48647400/images/8-1.jpg "standaardnormale verdeling F(z) = Kansdichtheidsfunctie maar dan met integraal ervoor van - tot z.")
8 Kansdichtheidsfunctie van de standaardnormale verdeling Waarbij aangezien μ z = en σ z = 1 = lineaire transformatie a + b*x waarbij a = (-μ/ σ) en b = (1/σ) Standaardnormale verdeling symbolisch: Z~N(,1) of φ(z) Kenmerken voor standaardnormale verdeling (preciezer geformuleerd) De standaardnormale dichtheidskromme bereikt een unieke top als Z = (want μ z = ). De ordinaatwaarde bedraagt hier 1/ (2π),4 (want σ z = 1) μ = Mo = Me = E[X] à = De 2 buigpunten situeren zich ditmaal bij Z = -1 en bij Z = +1 (want μ-σ = -1 en μ+σ = +1) Verdelingsfunctie van de standaardnormale verdeling F(z) = Kansdichtheidsfunctie maar dan met integraal ervoor van - tot z. Verkorte weergave = Φ(Z) Gecumuleerde kansdichtheden De kansdichtheid P(z i <Z<z j ) kan immers ook bekeken worden als het verschil tussen twee gecumuleerde kansdichtheden, met name Φ(z j ) - Φ(z i ) of P(Z<z j ) P (Z<z i ) Maak gebruik van symmetrie & complementaire kansen! Ieder normaalverdeelde kansvariabele kan via standaardisering omgezet worden in een standaardnormale kansvariabele: x µ x µ X ~ N( µσ, ) Z = ~ N(,1)... en... P( X < x) = P( Z < ) σ σ Van een kans(waarde) naar de corresponderende grenswaarde Stap 1: eerst oplossen voor Z ~ (,1) à waarde opzoeken in de tabel en bijhorende z-waarde aflezen Stap 2: z-waarde uit stap 1 ont-standaardiseren x µ z = x= µ + ( σ. z) σ Stelling van Chebychev Onafhankelijk van de vorm van de verdeling is ten minste 1*(1-k-2) procent van de waarneming maximaal ±k standaardafwijkingen verwijderd van het rekenkundig gemiddelde Betekenis Z-score: als z = 2 dan bevindt de bewuste score zich 2 standaardafwijkingen voorbij het gemiddelde. 8
 Bereken P(l i < X < u e i ) waarbij X ~ N(μ, σ) à Gebruik de tabel van")

 Het normale model past redelijk goed bij de geclassificeerde")

9 Aanpassen van een normale verdeling Stappenplan 1) De exacte klassengrenzen standaardiseren à e Zo bekomen je de z-scores zl ie en zu i e 2) Bereken P(l i < X < u e i ) waarbij X ~ N(μ, σ) à Gebruik de tabel van N(,1) voor de gestandaardiseerde z-scores N e 3) Bereken f i = P(l i < X < u e i ) * n N 4) Vergelijk f i en f i : ð + alle termen sommeren k = aantal klassen Hoe kleiner deze afwijkingssom is, hoe meer aanwijzing er is dat het normale model ook past bij de geclassificeerde empirische verdeling. Chi 2 -verdeling (χ 2 -verdeling) Het normale model past redelijk goed bij de geclassificeerde steekproefgegevens als: waarbij k 1 2 = v = aantal vrijheidsgraden Significantieniveau α = aantal % van de chi 2 -verdeelde steekproefverdeling die atypisch is Betrouwbaarheid = 1 α = het ste percentiel van de chi 2 verdeling Ruwe benadering: afwijkingssom < (k * 1,6)
10 De scheefheids- en gepiektheidsmaten Scheefheidsmaten: hoe scheef/asymmetrisch een empirische verdeling à normale verdeling = perfect symmetrisch à alleen bruikbaar voor niet te scheef verdeelde gegevens Gepiektheidsmaten: de mate waarin de waarnemingen zich concentreren in de staarten van de verdeling = hoe veel waarnemingen ver van het centrum verwijderd zijn. à normale verdeling: grootste deel v / d waarnemingen in de buurt v / h gem. μ Het normaal kwantieldiagram = het diagram waarin het verband tussen de empirische waarnemingen x i en de daarbij passende standaardnormale scores z i wordt weergegeven. Standaardnormale verdeling: lineair verband van de vorm x = μ+σ.z, waarbij Hoe we de x i s verbinden met de passende z i s 1) Gecumuleerde frequenties: De gegevens x i ordenen van laag naar hoog & een rangnummer toekennen 2) Relatieve gecumuleerde frequenties F i * = ( r i) : rangnummers delen door n of N 3) Opzoeken welke z-waarde past bij F i * = P[Z z] 4) Liggen de punten (z i,x i ) op een rechte è X~N(μ,σ) In feite verbinden we op deze manier empirische kwantielen (de waarnemingen x i ) met de daarbij horende standaardnormale kwantielen (de z-scores). Continuïteitscorrectie (CC) Te gebruiken wanneer een discrete verdeling wordt opgelost d.m.v. een continue verdeling. ð (x ± halve meetwaarde) Bijv. P (X 4) > schoenmaat is discreet, dus continuïteitscorrectie vanaf 3,5 rekenen, omdat 4 mee opgenomen is. Opmerking: P( s < Z < t) = P(s < Z < t) P( s < Z < t) = P(Z < t) (1 P(Z < s) Tip : tekenen! (schets van de standaardnormale verdeling) Hoofdstuk 5 Benaderingen van binomiale en hypergeometrische kansen Centrale limietstelling (CLS) = Een discrete verdeling die veel deelexperimenten behelst (n is groot), begint sterk te lijken op een continue verdeling, nl. een normale verdeling. = Als X 1, X 2,, X n identiek verdeelde en onderling onafhankelijke stochasten zijn met E[X i ] = μ en Var[X i ] = σ 2, dan is de som van deze stochasten X = 1'( X i normaal verdeeld met E[X] = nμ en Var[X] = nσ 2 wanneer n à + 1
 Oplossingsschema discrete verdelingen Hypergeometrisch: kans niet constant (= enigste verschil met binomiaal) > zonder teruglegging Indien N = heel groot & onbekend à binomiaal")
 EC gebruik je omdat de σ van hypergeometrisch < σ van binomiaal à daarom correctie daarop. Opmerking: Indien n.")

11 Vuistregel Als X ~ B(n,p) met n.p 5 en n.q 5 dan mogen we de verdeling van X benaderen door de normale verdeling N(n.p, n. p. q) Oplossingsschema discrete verdelingen Hypergeometrisch: kans niet constant (= enigste verschil met binomiaal) > zonder teruglegging Indien N = heel groot & onbekend à binomiaal verdeling, anders hypergeometrisch. Eindigheidscorrectie (EC) zegt iets over hoeveel % σ kleiner is (bijv. EC =, -> σ = 1% kleiner) EC gebruik je omdat de σ van hypergeometrisch < σ van binomiaal à daarom correctie daarop. Opmerking: Indien n.1 < N mag je ook de eindigheidscorrectie gebruiken maar die zou dan ongeveer 1 bedragen en dus geen noemenswaardige impact meer hebben. Stel jezelf de vragen: Discreet of continu probleem? Welke verdeling gebruik je? Cumulatieve of enkelvoudige kansvraag? Opmerkingen Ga altijd eerst op zoek naar je parameters Enkelvoudige vraag kun je niet berekenen onder de continu verdeling. o Bij een continu verdeling is de kans op één bepaalde waarde steeds gelijk aan. Als je een kleinere steekproef trekt, heb je meer kans op een onrealistisch resultaat. 11
12 Berekeningen met GR Distr (2 nd vars) Binomiale verdeling Exacte kans : Kleiner dan of gelijk aan A: binompdf( B: binomcdf( trails = n trails = n p = kans p = kans x value = aantal keer x x value = aantal keer x à Normale verdeling Bepaald gebied Tip: 2: normalcdf( je kunt ook de originele waardes (x) invoeren. Boven- en ondergrens ingeven à dan moet je dit ook doen voor μ & σ μ = & σ = 1 12
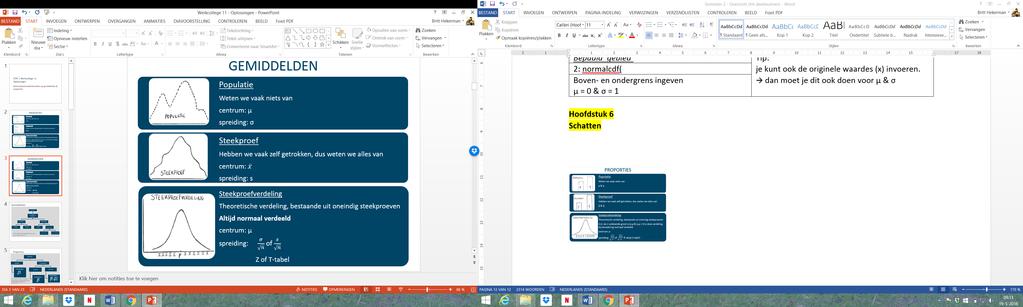
13 Hoofdstuk 6 Schatten Steekproefproportie X n = `steekproefproportie = p (`p hoed ) Van aantal successen à proporties: delen door n > n valt weg > je krijgt proporties Verdeling van de steekproefproportie ð ð & & is een lineaire transformatie van een binomiaal verdeelde stochast X: & = + (. X = a+bx met a= en b= ( volgt geen binomiale verdeling, maar we weten wel dat X ~ B(1;.25) N(25;4.33) (zie hiervoor: CLS toepassen bij B(n,p)) Verwachtingswaarde bepalen We weten dat E(a+bX)= a+b.e(x) ð E( X ) = n E(+(.X) = + ( E(X) = (. n. p = p Variantie bepalen: We weten dat Var(a+b.X)= b 2.Var(X) ð Var( & ) = Var(+(.X) = (( )2.Var(X) = ( :.;. n. p. q = ð σ( X n ) = Var(X) = p.q n Conclusie: Als n. p 5 en n. q 5 geldt dat & N(p; :.; ) En dus geldt A B : C.D A Continuïteitscorrectie N(;1) We gebruiken nu `±( *,F ) i.p.v. `±,5 (zie slide 21 les voor bewijs) Steekproefverdeling van p = de verdeling van de verschillende waarden die dit steekproefkenmerk aanneemt als men zeer veel aselecte steekproeven zou trekken van dezelfde omvang uit dezelfde populatie. 13
. In dit geval proberen we de proportie p te schatten op basis van informatie over 𝑝 in een steekproef.")
 hoe betrouwbaar is deze schatting?")
= Θ (Θ = `Thèta ) De")

14 Omkering van de vraagstelling We gaan op basis van een beperktere groep (een steekproef) iets proberen te zeggen over een grotere groep (een populatie). In dit geval proberen we de proportie p te schatten op basis van informatie over 𝑝 in een steekproef. Puntschatting = Intervalschatting = Toetsing = beperking tot één concrete waarde (wat is dan een zuivere (onvertekende) schatting voor deze proportie in de populatie?) hoe betrouwbaar is deze schatting? à betrouwbaarheidsintervallen Is het aannemelijk dat deze steekproef afkomstig is uit een populatie met een eerdere bepaalde μ? Puntschatting voor p Een zuivere puntschatting van p T is een zuivere of onvertekende puntschatting van Θ indien E(T)= Θ (Θ = `Thèta ) De steekproefproportie 𝑝 is een zuivere puntschatting van de populatieproportie p want ð Gemiddelde van alle 𝑝 = p, gemiddelde van de populatie Een efficiënte puntschatting van p De variabiliteit/doeltreffendheid van de schatter 𝑝 komt tot uiting in de variantie of de standaardafwijking van de steekproefverdeling van de steekproefproporties ð T is een efficiënte/doeltreffende schatter van Θ indien de variantie of standaardafwijking van T zo klein mogelijk is. 14
 De steekproefproportie p = & is een efficiënte")
15 à maar p is onbekend dus je gaat p gebruiken Standaardfout = de schatting van de standaardafwijking van de steekproef op basis van steekproefkenmerken Conclusie = pq ˆˆ. n De steekproefproportie p = & is een zuivere puntschatter voor p (want verwachtingswaarde van de steekproefverdeling van p is gelijk aan p) De steekproefproportie p = & is een efficiënte puntschatter voor p (want standaardafwijking van de steekproefverdeling van p is relatief klein) Een intervalschatting van p Intervalschatting = betrouwbaarheidsinterval = een schatting van het interval (minimum- en maximumwaarde) waarbinnen de parameter zich al situeren, gegeven een bepaald betrouwbaarheidsniveau. ð Tweezijdig interval, dus met een bovengrens én een ondergrens. Betrouwbaarheid C = het percentage van de steekproefverdeling waarmee men rekening houdt. = het aandeel van de steekproefverdeling wat waarschijnlijk wordt geacht. Werkwijze Vertrek van een steekproefproportie p Bepaal op basis van p vb. een 5% betrouwbaarheidsinterval [ondergrens ; bovengrens] zodat we kunnen zeggen in 5% van de gevallen ligt de echte populatieproportie p tussen de ondergrens en de bovengrens è maak gebruik van de steekproefverdeling van p,5 pˆ ( ) p pq ± pˆ ~ N p, n ~ N(,1) n pq n Stappenplan 1. Kritieke z-waarde bepalen = z* = z (1-C)/2 o Zoek dit op in de Z-tabel bij de bijhorende betrouwbaarheid C 2. Foutmarge berekenen :.; o M = z*. 3. Betrouwbaarheidsinterval opstellen (CI): o In C% van de gevallen zal p liggen tussen p z (1-C)/2. o Ofwel tussen p M en p + M :.; en p + z (1-C)/2. :.; 15
=C Hoe groter de steekproef, des te groter de noemer en des te kleiner de foutmarge. Eindigheidscorrectie Als de steekproef zonder teruglegging getrokken wordt uit een relatief kleine populatie (1.")

16 Algemene formule betrouwbaarheidsinterval P( 𝑧K LM < :B: C.D A < +𝑧K LN ) = C :.; ó P(𝑝 - 𝑧K LN. :.; < 𝑝 < 𝑝 + 𝑧K LM. )=C Hoe groter de steekproef, des te groter de noemer en des te kleiner de foutmarge. Eindigheidscorrectie Als de steekproef zonder teruglegging getrokken wordt uit een relatief kleine populatie (1.n N) ð geen onafhankelijke toevalsgebeurens à EC toepassen De formule voor een C.1% betrouwbaarheidsinterval voor p is bijgevolg [p zk LN. R.S T. UB UB( ; p + zk LN. R.S T. UB UB( ] n berekenen bij gegeven foutmarge Foutmarge m = 𝑧K LM. :.; Met z* = 𝑧K LM = kritieke waarde Als de foutmarge maximaal m mag zijn, bereken je de steekproefgrootte n via n= V.:.; X Schatten van gemiddelden De steekproefverdeling van het steekproefgemiddelde 𝑋 = ( 1'( 𝑋1 4 verschillende scenario s: a) Stochasten 𝑋1 zijn normaal verdeeld en σ is bekend b) Stochasten 𝑋1 zijn niet normaal verdeeld en σ is bekend c) Stochasten 𝑋1 zijn normaal verdeeld en σ is onbekend d) Stochasten 𝑋1 zijn niet normaal verdeeld en σ is onbekend Samenvatting: schatten van μ σ is bekend Het C.1%-betrouwbaarheidsinterval voor μ is waarbij: 16
 = P(X t K LM. Z < µ < X + t K LM Met een betrouwbaarheid van C.")
17 σ is niet gekend Als we Y vervangen door de standaardfout van de steekproefverdeling van het steekproefgemiddelde Z, is de steekproefverdeling niet langer normaal verdeeld maar volgt die een t-verdeling met n-1 vrijheidsgraden. & B[ \ A ~ t n-1 è P( t K LM < &B[ \ A < +t K LN ) = P(X t K LM. Z < µ < X + t K LM Met een betrouwbaarheid van C.1% ligt het populatiegemiddelde µ tussen: Z Z X t K LM. en X + t K LM.. Z ) = C Opmerkingen Tip: zorg dat je een conclusie kan formuleren. Populatiegegevens hebben altijd voorrang op steekproefgegevens! Dus indien je p weet, moet je deze gebruiken ipv. p Voor het opstellen van een betrouwbaarheidsinterval voor proporties ken je p nooit > dus is het altijd op steekproefgegevens. Bij een betrouwbaarheidsinterval heb je geen CC nodig, voor een hypothesetoets (mogelijk) wel. T-verdeling: laag aantal vrijheidsgraden = veel verschil tussen T-verdeling en Z-verdeling hoog aantal vrijheidsgraden = weinig verschil Keuze van df-waarde: dichtst mogelijk df-waarde kleiner dan (of gelijk aan) v (= n 1) (Dus voor bijv. n = 1 moet je toch kijken naar df-waarde 1) 17



18 18
19 Hoofdstuk 7 Toetsen De steekproeven = EAS Betrouwbaarheidsinterval = schattingsvraagstukken (vorig hoofdstuk) 7.1 Inleiding Een hypothese/significantietoets is bedoeld om een bewering over een populatiewaarde (p, µ, ) te toetsen d.m.v. een steekproef Bij toetsen hebben we het over de steekproefverdeling van een toetsingsgrootheid. Een toetsingsgrootheid is eigenlijk ook een steekproefgrootheid, maar dan wel één die men gebruikt in vergelijking tot een reeds bestaande schatting van het corresponderende populatiekenmerk. Verschillen tussen betrouwbaarheidsinvallen en statistische toetsing Betrouwbaarheidsinterval: We baseren ons enkel op de bevindingen uit een EAS. We beperken ons tot een schatting van de populatieparameter, in casu populatiegemiddelde, waarbij we de steekproefvariabiliteit in rekening brengen. Hypothesetoetsing: We hebben wel weet van een vroeger resultaat. Een veronderstelling wordt vastgesteld in hypothesen die het uitgangspunt vormen van statistische toetsing. Hypothesenpaar bij statistische toetsing (stel vroegere μ = b) Nulhypothese: De geformaliseerde veronderstelling die stelt dat de bestaande verwachtingen ten aanzien van de populatieparameter nog steeds opgaan. In een hypothesetoets wordt bewijsmateriaal tegen H onderzocht. H : μ = b Alternatieve hypothese: De hypothese die een verandering vooropstelt. Mogelijkheden: H a : μ > b rechts-eenzijdige hypothesetoets H a : μ < b links-eenzijdige hypothesetoets H a : μ b tweezijdige hypothesetoets Significantieniveau α = in zoveel % van de gevallen zouden we maar een dergelijke groot/klein steekproefgemiddelde aantreffen. C = compliment van α = de betrouwbaarheid ð Hoe groter α, des te groter de bewijssterkte tegen H. De vijf stappen van een hypothesetoets Vooraf: noteer de gegevens & wat er wordt gevraagd. 1) Bepaal nul- en alternatieve hypothese 2) Bepaal de toetsingsgrootheid en de verdeling ervan Bepaal de z-score (of t-score) horende bij het steekproefgemiddelde. 1
 = C o We leggen vast welke steekproefgemiddelden we onwaarschijnlijk groot/klein zullen noemen (die vinden we uiteraard in de rechter/linker staart van de steekproefverdeling), dit")
 Situeer de toetsingsgrootheid ten opzichte van de kritieke waarde z* (z met z* vergelijken) o We bekijken of de berekende toetsingsgrootheid z x (uitgaande van een gegeven μ en σ) zich situeert in")
20 3) Bepaal het verwerpingsgebied, ofwel kritieke grenswaarde (rekening houdende met het significantieniveau en de vorm van de alternatieve hypothese) o We zoeken naar de kritieke z-waarde z* waarvoor geldt dat P(Z<z*) = C o We leggen vast welke steekproefgemiddelden we onwaarschijnlijk groot/klein zullen noemen (die vinden we uiteraard in de rechter/linker staart van de steekproefverdeling), dit leid je af uit het gegeven significantieniveau α. 4) Situeer de toetsingsgrootheid ten opzichte van de kritieke waarde z* (z met z* vergelijken) o We bekijken of de berekende toetsingsgrootheid z x (uitgaande van een gegeven μ en σ) zich situeert in het verwerpingsgebied. o In dat geval achten we het onwaarschijnlijk, gegeven het significantieniveau, dat een dergelijk berekende toetsingsgrootheid afkomstig zou zijn uit N(,1) (ofwel uit een populatie met het eerder vastgestelde gemiddelde) 5) Formuleer een conclusie o Indien z x zich situeert in het verwerpingsgebied, kunnen we de nulhypothese verwerpen op het gegeven significantieniveau. o Het is dan dus onwaarschijnlijk dat je in een steekproef een bepaald gemiddelde vindt, terwijl het echte gemiddelde een bepaalde waarde bedraagt. Verwerpingsgebied bij eenzijdige toetsen De overschrijdingskans p (P-Value) De p-waarde is een kans die uitdrukt hoe waarschijnlijk het is dat een steekproef een (even extreme of) nog extremere waarde geeft dan diegene die wij hebben waargenomen. Bij een rechtseenzijdige toets zoeken we dus naar: P(Z>z x ) = 1 = Als p-waarde < α è H verwerpen op significantieniveau α Men geeft vaak aan wat het laagste significantieniveau α is waarvoor geldt dat de overschrijdingskans P < α. ð Hoe kleiner de corresponderende alfa, hoe sterker het bewijs is tegen de nulhypothese. Uitgedrukt in sterren: *: α =,1 **: α =,5 ***: α =,1 ****: α =,5 2

.")
21 Tweezijdige hypothesetoetsen H a: μ b Dit betekent dat we nu zowel in de linkerstaart als in de rechterstaart van de verdeling rekening moeten houden met een verwerpingsgebied à zoals bij een betrouwbaarheidsinterval zijn er in dit geval dus twee kritieke waarden. Bijv. gegeven dat α =,1 gaan we op zoek naar de z-waarden waarvoor geldt dat: P(Z<z) =,5 en P(Z>z) =,5 Voor het overige verloopt nagenoeg alles analoog (we hebben uiteraard nog altijd maar één toetsingsgrootheid zodat uiteindelijk maar één van beide kritieke waarden relevant is voor de situering van de berekende toetsingsgrootheid in de steekproefverdeling). Belangrijk verschil: bij de overschrijdingskans p. De overschrijdingskans wordt bij een tweezijdige toets verdubbeld. (de tweezijdige toetsingsprocedure werd immers vastgelegd voordat men de concrete toetsingsgrootheid berekent) Standaardfout versus standaardafwijking Indien we niet weten wat de standaardafwijking was in de vorige studie en moeten steunen op de standaardafwijking s in onze eigen steekproef, is de steekproefverdeling niet standaardnormaal maar t-verdeeld met (n-1) vrijheidsgraden. Je gebruikt dan de T-tabel en de kritieke grenswaarde t*. Voor het overige verloopt de toetsingsprocedure volledig analoog. Type I-fout en Type II-fout Bij het uitvoeren van een hypothesetoets bestaat de kans dat we een fout maken bij het formuleren van de conclusie. Type I-fout = de kans dat men H verwerpt terwijl die eigenlijk waar is. P(type I-fout) = significantieniveau α = 1 - C Type II-fout = de kans dat men H aanvaard terwijl H eigenlijk fout is. Berekening van β: 1. Vaststellen wanneer H : µ = b aanvaardt wordt. `B[ a A < z* of `B[ a A > z* à enige onbekende 2. berekenen waarvoor de nulhypothese nog net wordt aanvaard. 3. We veronderstellen dat de alternatieve hypothese eigenlijk geldig is, dus dat µ gelijk is aan het gemiddelde van de steekproef. 4. Los de vergelijking op P(Z< `B[(Z) a A ) of P(Z> `B[(Z) a A ) waarbij = net berekend en µ = van steekproef 21
 = α =,1 Kans op een type II-fout: P(type II-fout) = β = P(H aanvaarden H is fout) è")
22 Onderscheidingsvermogen (de `Power ) = het complement van β. = de kans dat H wordt verworpen gegeven dat een alternatieve parameterwaarde waar is. De type I-fout en de type II-fout in het voorbeeld van de belastingaangifte Kans op een type I-fout: P(type I-fout) = α =,1 Kans op een type II-fout: P(type II-fout) = β = P(H aanvaarden H is fout) è `H : µ = 55 is fout, dus we veronderstellen dat µ gelijk is aan x=5 è `H aanvaarden gebeurt als toetsingsgrootheid<z*, dus als `BFF Kc < 1.28 `BFF Kc dc < 1.28 als en slechts als x < ,28. (* j* = 57,2 è P(type II-fout) = P(Z< Fk,*lBFm Kc )=P(Z<-1,25)=,156 dc Hoe kleiner de kans op een type I-fout, hoe groter de kans op een type II-fout. ð trade-off dc Opmerkingen Bij toetsing gebruik je CC alleen als er (impliciet) bij staat dat het discreet gemeten is (bijv. als het er bij IQ niet bij staat, is CC niet nodig). Bij een hypothesetoets met proporties gebruik je de CC altijd! (want proportie is altijd discreet) Het makkelijkste is om deze al toe te passen op het proportie aantal (dus (proportie,5) / n) (máár bij het noteren van de gegevens, niet p al noteren incl. CC!) Bij hypothesetoetsen met proporties ken je p altijd want die staat in je hypothesetoets. Wat je van tevoren weet, beschouwen we als populatiegegevens. De nulhypothese en alternatieve hypothese gaan allebei altijd over populatie gegevens. Tip: maak een schets van de situatie. 22
Hoofdstuk 3 Statistiek: het toetsen
 Hoofdstuk 3 Statistiek: het toetsen 3.1 Schatten: Er moet een verbinding worden gelegd tussen de steekproefgrootheden en populatieparameters, willen we op basis van de een iets kunnen zeggen over de ander.
Hoofdstuk 3 Statistiek: het toetsen 3.1 Schatten: Er moet een verbinding worden gelegd tussen de steekproefgrootheden en populatieparameters, willen we op basis van de een iets kunnen zeggen over de ander.
Hoofdstuk 5 Een populatie: parametrische toetsen
 Hoofdstuk 5 Een populatie: parametrische toetsen 5.1 Gemiddelde, variantie, standaardafwijking: De variantie is als het ware de gemiddelde gekwadrateerde afwijking van het gemiddelde. Hoe groter de variantie
Hoofdstuk 5 Een populatie: parametrische toetsen 5.1 Gemiddelde, variantie, standaardafwijking: De variantie is als het ware de gemiddelde gekwadrateerde afwijking van het gemiddelde. Hoe groter de variantie
Samenvatting Statistiek
 Samenvatting Statistiek De hoofdstukken 1 t/m 3 gaan over kansrekening: het uitrekenen van kansen in een volledig gespecifeerd model, waarin de parameters bekend zijn en de kans op een gebeurtenis gevraagd
Samenvatting Statistiek De hoofdstukken 1 t/m 3 gaan over kansrekening: het uitrekenen van kansen in een volledig gespecifeerd model, waarin de parameters bekend zijn en de kans op een gebeurtenis gevraagd
Populatie: De gehele groep elementen waarover informatie wordt gewenst.
 Statistiek I Werkcollege 1 Populatie: De gehele groep elementen waarover informatie wordt gewenst. Steekproef: Gedeelte van de populatie dat feitelijk wordt onderzocht om informatie te vergaren. Eenheden:
Statistiek I Werkcollege 1 Populatie: De gehele groep elementen waarover informatie wordt gewenst. Steekproef: Gedeelte van de populatie dat feitelijk wordt onderzocht om informatie te vergaren. Eenheden:
Vandaag. Onderzoeksmethoden: Statistiek 3. Recap 2. Recap 1. Recap Centrale limietstelling T-verdeling Toetsen van hypotheses
 Vandaag Onderzoeksmethoden: Statistiek 3 Peter de Waal (gebaseerd op slides Peter de Waal, Marjan van den Akker) Departement Informatica Beta-faculteit, Universiteit Utrecht Recap Centrale limietstelling
Vandaag Onderzoeksmethoden: Statistiek 3 Peter de Waal (gebaseerd op slides Peter de Waal, Marjan van den Akker) Departement Informatica Beta-faculteit, Universiteit Utrecht Recap Centrale limietstelling
HOOFDSTUK 6: INTRODUCTIE IN STATISTISCHE GEVOLGTREKKINGEN
 HOOFDSTUK 6: INTRODUCTIE IN STATISTISCHE GEVOLGTREKKINGEN Inleiding Statistische gevolgtrekkingen (statistical inference) gaan over het trekken van conclusies over een populatie op basis van steekproefdata.
HOOFDSTUK 6: INTRODUCTIE IN STATISTISCHE GEVOLGTREKKINGEN Inleiding Statistische gevolgtrekkingen (statistical inference) gaan over het trekken van conclusies over een populatie op basis van steekproefdata.
DEEL 3 INDUCTIEVE STATISTIEK INLEIDING TOT DE INDUCTIEVE STATISTIEK 11.2 DE GROOTSTE AANNEMELIJKHEID - METHODE
 DEEL 3 INDUCTIEVE STATISTIEK INHOUD H 10: INLEIDING TOT DE INDUCTIEVE STATISTIEK H 11: PUNTSCHATTING 11.1 ALGEMEEN 11.1.1 Definities 11.1.2 Eigenschappen 11.2 DE GROOTSTE AANNEMELIJKHEID - METHODE 11.3
DEEL 3 INDUCTIEVE STATISTIEK INHOUD H 10: INLEIDING TOT DE INDUCTIEVE STATISTIEK H 11: PUNTSCHATTING 11.1 ALGEMEEN 11.1.1 Definities 11.1.2 Eigenschappen 11.2 DE GROOTSTE AANNEMELIJKHEID - METHODE 11.3
Medische Statistiek Kansrekening
 Medische Statistiek Kansrekening Medisch statistiek- kansrekening Hoorcollege 1 Uitkomstenruimte vaststellen Ook wel S of E. Bij dobbelsteen: E= {1,2,3,4,5,6} Een eindige uitkomstenreeks Bij het gooien
Medische Statistiek Kansrekening Medisch statistiek- kansrekening Hoorcollege 1 Uitkomstenruimte vaststellen Ook wel S of E. Bij dobbelsteen: E= {1,2,3,4,5,6} Een eindige uitkomstenreeks Bij het gooien
Vandaag. Onderzoeksmethoden: Statistiek 2. Basisbegrippen. Theoretische kansverdelingen
 Vandaag Onderzoeksmethoden: Statistiek 2 Peter de Waal (gebaseerd op slides Peter de Waal, Marjan van den Akker) Departement Informatica Beta-faculteit, Universiteit Utrecht Theoretische kansverdelingen
Vandaag Onderzoeksmethoden: Statistiek 2 Peter de Waal (gebaseerd op slides Peter de Waal, Marjan van den Akker) Departement Informatica Beta-faculteit, Universiteit Utrecht Theoretische kansverdelingen
Hoofdstuk 6 Twee populaties: parametrische toetsen
 Hoofdstuk 6 Twee populaties: parametrische toetsen 6.1 De t-toets voor het verschil tussen twee gemiddelden: In veel onderzoekssituaties zijn we vooral in de verschillen tussen twee populaties geïnteresseerd.
Hoofdstuk 6 Twee populaties: parametrische toetsen 6.1 De t-toets voor het verschil tussen twee gemiddelden: In veel onderzoekssituaties zijn we vooral in de verschillen tussen twee populaties geïnteresseerd.
werkcollege 6 - D&P9: Estimation Using a Single Sample
 cursus 9 mei 2012 werkcollege 6 - D&P9: Estimation Using a Single Sample van frequentie naar dichtheid we bepalen frequenties van meetwaarden plot in histogram delen door totaal aantal meetwaarden > fracties
cursus 9 mei 2012 werkcollege 6 - D&P9: Estimation Using a Single Sample van frequentie naar dichtheid we bepalen frequenties van meetwaarden plot in histogram delen door totaal aantal meetwaarden > fracties
Verklarende Statistiek: Toetsen. Zat ik nou in dat kritische gebied of niet?
 Verklarende Statistiek: Toetsen Zat ik nou in dat kritische gebied of niet? Toetsen, Overzicht Nulhypothese - Alternatieve hypothese (voorbeeld: toets voor p = p o in binomiale steekproef) Betrouwbaarheid
Verklarende Statistiek: Toetsen Zat ik nou in dat kritische gebied of niet? Toetsen, Overzicht Nulhypothese - Alternatieve hypothese (voorbeeld: toets voor p = p o in binomiale steekproef) Betrouwbaarheid
SOCIALE STATISTIEK (deel 2)
") SOCIALE STATISTIEK (deel 2) D. Vanpaemel KU Leuven D. Vanpaemel (KU Leuven) SOCIALE STATISTIEK (deel 2) 1 / 57 Hoofdstuk 5: Schatters en hun verdeling 5.1 Steekproefgemiddelde als toevalsvariabele D. Vanpaemel
SOCIALE STATISTIEK (deel 2) D. Vanpaemel KU Leuven D. Vanpaemel (KU Leuven) SOCIALE STATISTIEK (deel 2) 1 / 57 Hoofdstuk 5: Schatters en hun verdeling 5.1 Steekproefgemiddelde als toevalsvariabele D. Vanpaemel
. Dan geldt P(B) = a. 1 4. d. 3 8
 = a. 1 4. d. 3 8") Tentamen Statistische methoden 4052STAMEY juli 203, 9:00 2:00 Studienummers: Vult u alstublieft op het meerkeuzevragenformulier uw Delftse studienummer in (tbv automatische verwerking); en op het open
Tentamen Statistische methoden 4052STAMEY juli 203, 9:00 2:00 Studienummers: Vult u alstublieft op het meerkeuzevragenformulier uw Delftse studienummer in (tbv automatische verwerking); en op het open
We illustreren deze werkwijze opnieuw a.h.v. de steekproef van de geboortegewichten
 Hoofdstuk 8 Betrouwbaarheidsintervallen In het vorige hoofdstuk lieten we zien hoe het mogelijk is om over een ongekende karakteristiek van een populatie hypothesen te formuleren. Een andere manier van
Hoofdstuk 8 Betrouwbaarheidsintervallen In het vorige hoofdstuk lieten we zien hoe het mogelijk is om over een ongekende karakteristiek van een populatie hypothesen te formuleren. Een andere manier van
Formules Excel Bedrijfsstatistiek
 Formules Excel Bedrijfsstatistiek Hoofdstuk 2 Data en hun voorstelling AANTAL.ALS vb: AANTAL.ALS(A1 :B6,H1) Telt hoeveel keer (frequentie) de waarde die in H1 zit in A1:B6 voorkomt. Vooral bedoeld voor
Formules Excel Bedrijfsstatistiek Hoofdstuk 2 Data en hun voorstelling AANTAL.ALS vb: AANTAL.ALS(A1 :B6,H1) Telt hoeveel keer (frequentie) de waarde die in H1 zit in A1:B6 voorkomt. Vooral bedoeld voor
Kansrekening en Statistiek
 Kansrekening en Statistiek College 15 Dinsdag 2 November 1 / 16 2 Statistiek Indeling: Filosofie Schatten Centraal Bureau voor Statistiek 2 / 16 Schatten Vb. Het aantal tenen plus vingers in jullie huishoudens:
Kansrekening en Statistiek College 15 Dinsdag 2 November 1 / 16 2 Statistiek Indeling: Filosofie Schatten Centraal Bureau voor Statistiek 2 / 16 Schatten Vb. Het aantal tenen plus vingers in jullie huishoudens:
Hoofdstuk 5: Steekproevendistributies
 Hoofdstuk 5: Steekproevendistributies Inleiding Statistische gevolgtrekkingen worden gebruikt om conclusies over een populatie of proces te trekken op basis van data. Deze data wordt samengevat door middel
Hoofdstuk 5: Steekproevendistributies Inleiding Statistische gevolgtrekkingen worden gebruikt om conclusies over een populatie of proces te trekken op basis van data. Deze data wordt samengevat door middel
Data analyse Inleiding statistiek
 Data analyse Inleiding statistiek 1 Terugblik - Inductieve statistiek Afleiden van eigenschappen van een populatie op basis van een beperkt aantal metingen (steekproef) Kennis gemaakt met kans & kansverdelingen»
Data analyse Inleiding statistiek 1 Terugblik - Inductieve statistiek Afleiden van eigenschappen van een populatie op basis van een beperkt aantal metingen (steekproef) Kennis gemaakt met kans & kansverdelingen»
Tentamen Kansrekening en statistiek wi2105in 25 juni 2007, uur
 Tentamen Kansrekening en statistiek wi205in 25 juni 2007, 4.00 7.00 uur Bij dit examen is het gebruik van een (evt. grafische rekenmachine toegestaan. Tevens krijgt u een formuleblad uitgereikt na afloop
Tentamen Kansrekening en statistiek wi205in 25 juni 2007, 4.00 7.00 uur Bij dit examen is het gebruik van een (evt. grafische rekenmachine toegestaan. Tevens krijgt u een formuleblad uitgereikt na afloop
Kansrekening en statistiek wi2105in deel I 29 januari 2010, uur
 Kansrekening en statistiek wi20in deel I 29 januari 200, 400 700 uur Bij dit examen is het gebruik van een (evt grafische rekenmachine toegestaan Tevens krijgt u een formuleblad uitgereikt na afloop inleveren
Kansrekening en statistiek wi20in deel I 29 januari 200, 400 700 uur Bij dit examen is het gebruik van een (evt grafische rekenmachine toegestaan Tevens krijgt u een formuleblad uitgereikt na afloop inleveren
Hoofdstuk 7: Statistische gevolgtrekkingen voor distributies
 Hoofdstuk 7: Statistische gevolgtrekkingen voor distributies 7.1 Het gemiddelde van een populatie Standaarddeviatie van de populatie en de steekproef In het vorige deel is bij de significantietoets uitgegaan
Hoofdstuk 7: Statistische gevolgtrekkingen voor distributies 7.1 Het gemiddelde van een populatie Standaarddeviatie van de populatie en de steekproef In het vorige deel is bij de significantietoets uitgegaan
+ ( 1 4 )2 σ 2 X σ2. 36 σ2 terwijl V ar[x] = 11. Aangezien V ar[x] het kleinst is, is dit rekenkundig gemiddelde de meest efficiënte schatter.
![+ ( 1 4 )2 σ 2 X σ2. 36 σ2 terwijl V ar[x] = 11. Aangezien V ar[x] het kleinst is, is dit rekenkundig gemiddelde de meest efficiënte schatter.](/thumbs/48/24456561.jpg "+ ( 1 4 )2 σ 2 X σ2. 36 σ2 terwijl V ar[x] = 11. Aangezien V ar[x] het kleinst is, is dit rekenkundig gemiddelde de meest efficiënte schatter.") STATISTIEK OPLOSSINGEN OEFENZITTINGEN 5 en 6 c D. Keppens 2004 5 1 (a) Zij µ de verwachtingswaarde van X. We moeten aantonen dat E[M i ] = µ voor i = 1, 2, 3 om te kunnen spreken van zuivere schatters.
STATISTIEK OPLOSSINGEN OEFENZITTINGEN 5 en 6 c D. Keppens 2004 5 1 (a) Zij µ de verwachtingswaarde van X. We moeten aantonen dat E[M i ] = µ voor i = 1, 2, 3 om te kunnen spreken van zuivere schatters.
Inhoudsopgave. Deel I Schatters en toetsen 1
 Inhoudsopgave Deel I Schatters en toetsen 1 1 Hetschattenvanpopulatieparameters.................. 3 1.1 Inleiding:schatterversusschatting................. 3 1.2 Hetschattenvaneengemiddelde..................
Inhoudsopgave Deel I Schatters en toetsen 1 1 Hetschattenvanpopulatieparameters.................. 3 1.1 Inleiding:schatterversusschatting................. 3 1.2 Hetschattenvaneengemiddelde..................
Oefenvragen bij Statistics for Business and Economics van Newbold
 Oefenvragen bij Statistics for Business and Economics van Newbold Hoofdstuk 1 1. Wat is het verschil tussen populatie en sample? De populatie is de complete set van items waar de onderzoeker in geïnteresseerd
Oefenvragen bij Statistics for Business and Economics van Newbold Hoofdstuk 1 1. Wat is het verschil tussen populatie en sample? De populatie is de complete set van items waar de onderzoeker in geïnteresseerd
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica. Tentamen Statistiek (2DD14) op vrijdag 17 maart 2006, 9.00-12.00 uur.
 op vrijdag 17 maart 2006, 9.00-12.00 uur.") TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek DD14) op vrijdag 17 maart 006, 9.00-1.00 uur. UITWERKINGEN 1. Methoden om schatters te vinden a) De aannemelijkheidsfunctie
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek DD14) op vrijdag 17 maart 006, 9.00-1.00 uur. UITWERKINGEN 1. Methoden om schatters te vinden a) De aannemelijkheidsfunctie
14.1 Kansberekeningen [1]
![14.1 Kansberekeningen [1]](/thumbs/59/42966816.jpg "14.1 Kansberekeningen [1]") 14.1 Kansberekeningen [1] Herhaling kansberekeningen: Somregel: Als de gebeurtenissen G 1 en G 2 geen gemeenschappelijke uitkomsten hebben geldt: P(G 1 of G 2 ) = P(G 1 ) + P(G 2 ) B.v. P(3 of 4 gooien
14.1 Kansberekeningen [1] Herhaling kansberekeningen: Somregel: Als de gebeurtenissen G 1 en G 2 geen gemeenschappelijke uitkomsten hebben geldt: P(G 1 of G 2 ) = P(G 1 ) + P(G 2 ) B.v. P(3 of 4 gooien
11.0 Voorkennis. Wanneer je met binomcdf werkt, werk je dus altijd met een kans van de vorm P(X k)
") 11.0 Voorkennis Let op: Cumulatieve binomiale verdeling: P(X k) = binomcdf(n,p,k) Wanneer je met binomcdf werkt, werk je dus altijd met een kans van de vorm P(X k) Voorbeeld 1: Binomiaal kanseperiment
11.0 Voorkennis Let op: Cumulatieve binomiale verdeling: P(X k) = binomcdf(n,p,k) Wanneer je met binomcdf werkt, werk je dus altijd met een kans van de vorm P(X k) Voorbeeld 1: Binomiaal kanseperiment
9.0 Voorkennis. Bij samengestelde kansexperimenten maak je gebruik van de productregel.
 9.0 Voorkennis Bij samengestelde kansexperimenten maak je gebruik van de productregel. Productregel: Voor de gebeurtenis G 1 bij het ene kansexperiment en de gebeurtenis G 2 bij het andere kansexperiment
9.0 Voorkennis Bij samengestelde kansexperimenten maak je gebruik van de productregel. Productregel: Voor de gebeurtenis G 1 bij het ene kansexperiment en de gebeurtenis G 2 bij het andere kansexperiment
TECHNISCHE UNIVERSITEIT EINDHOVEN. Faculteit Wiskunde en Informatica
 TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Kansrekening (2WS2, Vrijdag 23 januari 25, om 9:-2:. Dit is een tentamen met gesloten boek. De uitwerkingen van de opgaven dienen
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Kansrekening (2WS2, Vrijdag 23 januari 25, om 9:-2:. Dit is een tentamen met gesloten boek. De uitwerkingen van de opgaven dienen
Statistiek: Spreiding en dispersie 6/12/2013. dr. Brenda Casteleyn
 Statistiek: Spreiding en dispersie 6/12/2013 dr. Brenda Casteleyn dr. Brenda Casteleyn www.keu6.be Page 2 1. Theorie Met spreiding willen we in één getal uitdrukken hoe verspreid de gegevens zijn: in hoeveel
Statistiek: Spreiding en dispersie 6/12/2013 dr. Brenda Casteleyn dr. Brenda Casteleyn www.keu6.be Page 2 1. Theorie Met spreiding willen we in één getal uitdrukken hoe verspreid de gegevens zijn: in hoeveel
11.1 Kansberekeningen [1]
![11.1 Kansberekeningen [1]](/thumbs/27/12038291.jpg "11.1 Kansberekeningen [1]") 11.1 Kansberekeningen [1] Kansdefinitie van Laplace: P(gebeurtenis) = Aantal gunstige uitkomsten/aantal mogelijke uitkomsten Voorbeeld 1: Wat is de kans om minstens 16 te gooien, als je met 3 dobbelstenen
11.1 Kansberekeningen [1] Kansdefinitie van Laplace: P(gebeurtenis) = Aantal gunstige uitkomsten/aantal mogelijke uitkomsten Voorbeeld 1: Wat is de kans om minstens 16 te gooien, als je met 3 dobbelstenen
Kansrekening en statistiek WI2211TI / WI2105IN deel 2 2 februari 2012, uur
 Kansrekening en statistiek WI22TI / WI25IN deel 2 2 februari 22, 4. 6. uur VOOR WI22TI: Bij dit examen is het gebruik van een (evt. grafische) rekenmachine toegestaan. Een formuleblad is niet toegestaan.
Kansrekening en statistiek WI22TI / WI25IN deel 2 2 februari 22, 4. 6. uur VOOR WI22TI: Bij dit examen is het gebruik van een (evt. grafische) rekenmachine toegestaan. Een formuleblad is niet toegestaan.
Samenvatting Wiskunde A
 Bereken: Bereken algebraisch: Bereken exact: De opgave mag berekend worden met de hand of met de GR. Geef bij GR gebruik de ingevoerde formules en gebruikte opties. Kies op een examen in dit geval voor
Bereken: Bereken algebraisch: Bereken exact: De opgave mag berekend worden met de hand of met de GR. Geef bij GR gebruik de ingevoerde formules en gebruikte opties. Kies op een examen in dit geval voor
Inhoud. 1 Inleiding tot de beschrijvende statistiek Maatstaven voor ligging en spreiding Kansrekening 99
 Inhoud 1 Inleiding tot de beschrijvende statistiek 13 1.1 Een eerste verkenning 14 1.2 Frequentieverdelingen 22 1.3 Grafische voorstellingen 30 1.4 Diverse diagrammen 35 1.5 Stamdiagram, histogram en frequentiepolygoon
Inhoud 1 Inleiding tot de beschrijvende statistiek 13 1.1 Een eerste verkenning 14 1.2 Frequentieverdelingen 22 1.3 Grafische voorstellingen 30 1.4 Diverse diagrammen 35 1.5 Stamdiagram, histogram en frequentiepolygoon
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica
 TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamenopgaven Statistiek 2DD71: UITWERKINGEN 1. Stroopwafels a De som S van de 12 gewichten is X 1 + X 2 + + X 12. Deze is normaal
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamenopgaven Statistiek 2DD71: UITWERKINGEN 1. Stroopwafels a De som S van de 12 gewichten is X 1 + X 2 + + X 12. Deze is normaal
13.1 Kansberekeningen [1]
![13.1 Kansberekeningen [1]](/thumbs/53/31278159.jpg "13.1 Kansberekeningen [1]") 13.1 Kansberekeningen [1] Herhaling kansberekeningen: Somregel: Als de gebeurtenissen G 1 en G 2 geen gemeenschappelijke uitkomsten hebben geldt: P(G 1 of G 2 ) = P(G 1 ) + P(G 2 ) B.v. P(3 of 4 gooien
13.1 Kansberekeningen [1] Herhaling kansberekeningen: Somregel: Als de gebeurtenissen G 1 en G 2 geen gemeenschappelijke uitkomsten hebben geldt: P(G 1 of G 2 ) = P(G 1 ) + P(G 2 ) B.v. P(3 of 4 gooien
 Vertaling van enkele termen uit de kansrekening en statistiek alternative hypothesis alternatieve hypothese approximate methods benaderende methoden asymptotic variance asymptotische variantie asymptotically
Vertaling van enkele termen uit de kansrekening en statistiek alternative hypothesis alternatieve hypothese approximate methods benaderende methoden asymptotic variance asymptotische variantie asymptotically
HOOFDSTUK 7: STATISTISCHE GEVOLGTREKKINGEN VOOR DISTRIBUTIES
 HOOFDSTUK 7: STATISTISCHE GEVOLGTREKKINGEN VOOR DISTRIBUTIES 7.1 Het gemiddelde van een populatie Standaarddeviatie van de populatie en de steekproef In het vorige deel is bij de significantietoets uitgegaan
HOOFDSTUK 7: STATISTISCHE GEVOLGTREKKINGEN VOOR DISTRIBUTIES 7.1 Het gemiddelde van een populatie Standaarddeviatie van de populatie en de steekproef In het vorige deel is bij de significantietoets uitgegaan
VOOR HET SECUNDAIR ONDERWIJS
 VOOR HET SECUNDAIR ONDERWIJS Steekproefmodellen en normaal verdeelde steekproefgrootheden 5. Werktekst voor de leerling Prof. dr. Herman Callaert Hans Bekaert Cecile Goethals Lies Provoost Marc Vancaudenberg
VOOR HET SECUNDAIR ONDERWIJS Steekproefmodellen en normaal verdeelde steekproefgrootheden 5. Werktekst voor de leerling Prof. dr. Herman Callaert Hans Bekaert Cecile Goethals Lies Provoost Marc Vancaudenberg
Tentamen Mathematische Statistiek (2WS05), vrijdag 29 oktober 2010, van 14.00 17.00 uur.
, vrijdag 29 oktober 2010, van 14.00 17.00 uur.") Technische Universiteit Eindhoven Faculteit Wiskunde en Informatica Tentamen Mathematische Statistiek (WS05), vrijdag 9 oktober 010, van 14.00 17.00 uur. Dit is een tentamen met gesloten boek. De uitwerkingen
Technische Universiteit Eindhoven Faculteit Wiskunde en Informatica Tentamen Mathematische Statistiek (WS05), vrijdag 9 oktober 010, van 14.00 17.00 uur. Dit is een tentamen met gesloten boek. De uitwerkingen
Inleiding Applicatie Software - Statgraphics
 Inleiding Applicatie Software - Statgraphics Beschrijvende Statistiek /k 1/35 OPDRACHT OVER BESCHRIJVENDE STATISTIEK Beleggen Door een erfenis heeft een vriend van u onverwacht de beschikking over een
Inleiding Applicatie Software - Statgraphics Beschrijvende Statistiek /k 1/35 OPDRACHT OVER BESCHRIJVENDE STATISTIEK Beleggen Door een erfenis heeft een vriend van u onverwacht de beschikking over een
Kansrekening en Statistiek
 Kansrekening en Statistiek College 8 Donderdag 13 Oktober 1 / 23 2 Statistiek Vandaag: Stochast en populatie Experimenten herhalen Wet van de Grote Getallen Centrale Limietstelling 2 / 23 Stochast en populatie
Kansrekening en Statistiek College 8 Donderdag 13 Oktober 1 / 23 2 Statistiek Vandaag: Stochast en populatie Experimenten herhalen Wet van de Grote Getallen Centrale Limietstelling 2 / 23 Stochast en populatie
Toetsende Statistiek, Week 2. Van Steekproef naar Populatie: De Steekproevenverdeling
 Toetsende Statistiek, Week 2. Van Steekproef naar Populatie: De Steekproevenverdeling Moore, McCabe & Craig: 3.3 Toward Statistical Inference From Probability to Inference 5.1 Sampling Distributions for
Toetsende Statistiek, Week 2. Van Steekproef naar Populatie: De Steekproevenverdeling Moore, McCabe & Craig: 3.3 Toward Statistical Inference From Probability to Inference 5.1 Sampling Distributions for
4 Domein STATISTIEK - versie 1.2
 USolv-IT - Boomstructuur DOMEIN STATISTIEK - versie 1.2 - c Copyrighted 42 4 Domein STATISTIEK - versie 1.2 (Op initiatief van USolv-IT werd deze boomstructuur mede in overleg met het Universitair Centrum
USolv-IT - Boomstructuur DOMEIN STATISTIEK - versie 1.2 - c Copyrighted 42 4 Domein STATISTIEK - versie 1.2 (Op initiatief van USolv-IT werd deze boomstructuur mede in overleg met het Universitair Centrum
Examen Statistiek I Feedback
 Examen Statistiek I Feedback Bij elke vraag is alternatief A correct. Bij de trekking van een persoon uit een populatie beschouwt men de gebeurtenissen A (met bril), B (hooggeschoold) en C (mannelijk).
Examen Statistiek I Feedback Bij elke vraag is alternatief A correct. Bij de trekking van een persoon uit een populatie beschouwt men de gebeurtenissen A (met bril), B (hooggeschoold) en C (mannelijk).
Kansrekening en Statistiek
 Kansrekening en Statistiek College 14 Donderdag 28 Oktober 1 / 37 2 Statistiek Indeling: Hypothese toetsen Schatten 2 / 37 Vragen 61 Amerikanen werd gevraagd hoeveel % van de tijd zij liegen. Het gevonden
Kansrekening en Statistiek College 14 Donderdag 28 Oktober 1 / 37 2 Statistiek Indeling: Hypothese toetsen Schatten 2 / 37 Vragen 61 Amerikanen werd gevraagd hoeveel % van de tijd zij liegen. Het gevonden
Inleiding Applicatie Software - Statgraphics. Beschrijvende Statistiek
 Inleiding Applicatie Software - Statgraphics Beschrijvende Statistiek OPDRACHT OVER BESCHRIJVENDE STATISTIEK Beleggen Door een erfenis heeft een vriend van u onverwacht de beschikking over een klein kapitaaltje
Inleiding Applicatie Software - Statgraphics Beschrijvende Statistiek OPDRACHT OVER BESCHRIJVENDE STATISTIEK Beleggen Door een erfenis heeft een vriend van u onverwacht de beschikking over een klein kapitaaltje
Vrije Universiteit 28 mei Gebruik van een (niet-grafische) rekenmachine is toegestaan.
 rekenmachine is toegestaan.") Afdeling Wiskunde Volledig tentamen Statistics Deeltentamen 2 Statistics Vrije Universiteit 28 mei 2015 Gebruik van een (niet-grafische) rekenmachine is toegestaan. Geheel tentamen: opgaven 1,2,3,4. Cijfer=
Afdeling Wiskunde Volledig tentamen Statistics Deeltentamen 2 Statistics Vrije Universiteit 28 mei 2015 Gebruik van een (niet-grafische) rekenmachine is toegestaan. Geheel tentamen: opgaven 1,2,3,4. Cijfer=
Voorbeeldtentamen Statistiek voor Psychologie
 Voorbeeldtentamen Statistiek voor Psychologie 1) Vul de volgende uitspraak aan, zodat er een juiste bewering ontstaat: De verdeling van een variabele geeft een opsomming van de categorieën en geeft daarbij
Voorbeeldtentamen Statistiek voor Psychologie 1) Vul de volgende uitspraak aan, zodat er een juiste bewering ontstaat: De verdeling van een variabele geeft een opsomming van de categorieën en geeft daarbij
VOOR HET SECUNDAIR ONDERWIJS. Kansmodellen. 4. Het steekproefgemiddelde. Werktekst voor de leerling. Prof. dr. Herman Callaert
 VOOR HET SECUNDAIR ONDERWIJS Kansmodellen 4. Werktekst voor de leerling Prof. dr. Herman Callaert Hans Bekaert Cecile Goethals Lies Provoost Marc Vancaudenberg . Een concreet voorbeeld.... Een kansmodel
VOOR HET SECUNDAIR ONDERWIJS Kansmodellen 4. Werktekst voor de leerling Prof. dr. Herman Callaert Hans Bekaert Cecile Goethals Lies Provoost Marc Vancaudenberg . Een concreet voorbeeld.... Een kansmodel
Toetsen van Hypothesen. Het vaststellen van de hypothese
 Toetsen van Hypothesen Wisnet-hbo update maart 2008 1. en Het vaststellen van de hypothese De nulhypothese en de Alternatieve hypothese. Het gaat in deze paragraaf puur alleen om de formulering. Er wordt
Toetsen van Hypothesen Wisnet-hbo update maart 2008 1. en Het vaststellen van de hypothese De nulhypothese en de Alternatieve hypothese. Het gaat in deze paragraaf puur alleen om de formulering. Er wordt
Deze week: Steekproefverdelingen. Statistiek voor Informatica Hoofdstuk 7: Steekproefverdelingen. Kwaliteit van schatter. Overzicht Schatten
 Deze week: Steekproefverdelingen Statistiek voor Informatica Hoofdstuk 7: Steekproefverdelingen Cursusjaar 29 Peter de Waal Zuivere Schatters Betrouwbaarheidsintervallen Departement Informatica Hfdstk
Deze week: Steekproefverdelingen Statistiek voor Informatica Hoofdstuk 7: Steekproefverdelingen Cursusjaar 29 Peter de Waal Zuivere Schatters Betrouwbaarheidsintervallen Departement Informatica Hfdstk
Cursus Statistiek Hoofdstuk 4. Statistiek voor Informatica Hoofdstuk 4: Verwachtingen. Definitie (Verwachting van discrete stochast) Voorbeeld (1)
 Voorbeeld (1)") Cursus Statistiek Hoofdstuk 4 Statistiek voor Informatica Hoofdstuk 4: Verwachtingen Cursusjaar 29 Peter de Waal Departement Informatica Inhoud Verwachtingen Variantie Momenten en Momentengenererende functie
Cursus Statistiek Hoofdstuk 4 Statistiek voor Informatica Hoofdstuk 4: Verwachtingen Cursusjaar 29 Peter de Waal Departement Informatica Inhoud Verwachtingen Variantie Momenten en Momentengenererende functie
7.1 Toets voor het gemiddelde van een normale verdeling
 Hoofdstuk 7 Toetsen van hypothesen Toetsen van hypothesen is, o.a. in de medische en chemische wereld, een veel gebruikte statistische techniek. Het wordt vaak gebruikt om een gevestigde norm eventueel
Hoofdstuk 7 Toetsen van hypothesen Toetsen van hypothesen is, o.a. in de medische en chemische wereld, een veel gebruikte statistische techniek. Het wordt vaak gebruikt om een gevestigde norm eventueel
Kansrekening en Statistiek
 Kansrekening en Statistiek College 7 Dinsdag 11 Oktober 1 / 33 2 Statistiek Vandaag: Populatie en steekproef Maten Standaardscores Normale verdeling Stochast en populatie Experimenten herhalen 2 / 33 3
Kansrekening en Statistiek College 7 Dinsdag 11 Oktober 1 / 33 2 Statistiek Vandaag: Populatie en steekproef Maten Standaardscores Normale verdeling Stochast en populatie Experimenten herhalen 2 / 33 3
Zin en onzin van normale benaderingen van binomiale verdelingen
 Zin en onzin van normale benaderingen van binomiale verdelingen Johan Walrave, docent EHSAL 0. Inleiding Voordat het grafisch rekentoestel in onze school ingevoerd werd, was er onder de statistiekdocenten
Zin en onzin van normale benaderingen van binomiale verdelingen Johan Walrave, docent EHSAL 0. Inleiding Voordat het grafisch rekentoestel in onze school ingevoerd werd, was er onder de statistiekdocenten
Statistiek II. Sessie 1. Verzamelde vragen en feedback Deel 1
 Statistiek II Sessie 1 Verzamelde vragen en feedback Deel 1 VPPK Universiteit Gent 2017-2018 Feedback Oefensessie 1 1 Staafdiagram 1. Wat is de steekproefgrootte? Op de horizontale as vinden we de respectievelijke
Statistiek II Sessie 1 Verzamelde vragen en feedback Deel 1 VPPK Universiteit Gent 2017-2018 Feedback Oefensessie 1 1 Staafdiagram 1. Wat is de steekproefgrootte? Op de horizontale as vinden we de respectievelijke
Tentamen Wiskunde A CENTRALE COMMISSIE VOORTENTAMEN WISKUNDE. Datum: 19 december Aantal opgaven: 6
 CENTRALE COMMISSIE VOORTENTAMEN WISKUNDE Tentamen Wiskunde A Datum: 19 december 2018 Tijd: 13.30 16.30 uur Aantal opgaven: 6 Lees onderstaande aanwijzingen s.v.p. goed door voordat u met het tentamen begint.
CENTRALE COMMISSIE VOORTENTAMEN WISKUNDE Tentamen Wiskunde A Datum: 19 december 2018 Tijd: 13.30 16.30 uur Aantal opgaven: 6 Lees onderstaande aanwijzingen s.v.p. goed door voordat u met het tentamen begint.
Sheets K&S voor INF HC 10: Hoofdstuk 12
 Sheets K&S voor INF HC 1: Hoofdstuk 12 Statistiek Deel 1: Schatten (hfdst. 1) Deel 2: Betrouwbaarheidsintervallen (11) Deel 3: Toetsen van hypothesen (12) Betrouwbaarheidsintervallen (H11) en toetsen (H12)
Sheets K&S voor INF HC 1: Hoofdstuk 12 Statistiek Deel 1: Schatten (hfdst. 1) Deel 2: Betrouwbaarheidsintervallen (11) Deel 3: Toetsen van hypothesen (12) Betrouwbaarheidsintervallen (H11) en toetsen (H12)
Statistiek voor A.I.
 Statistiek voor A.I. College 13 Donderdag 25 Oktober 1 / 28 2 Deductieve statistiek Orthodoxe statistiek 2 / 28 3 / 28 Jullie - onderzoek Tobias, Lody, Swen en Sander Links: Aantal broers/zussen van het
Statistiek voor A.I. College 13 Donderdag 25 Oktober 1 / 28 2 Deductieve statistiek Orthodoxe statistiek 2 / 28 3 / 28 Jullie - onderzoek Tobias, Lody, Swen en Sander Links: Aantal broers/zussen van het
Tentamen Statistische methoden MST-STM 8 april 2010, 9:00 12:00
 Tentamen Statistische methoden MST-STM 8 april 2, 9: 2: Bij dit examen is het gebruik van een (evt. grafische) rekenmachine toegestaan. Tevens krijgt u een formuleblad uitgereikt na afloop inleveren alstublieft.
Tentamen Statistische methoden MST-STM 8 april 2, 9: 2: Bij dit examen is het gebruik van een (evt. grafische) rekenmachine toegestaan. Tevens krijgt u een formuleblad uitgereikt na afloop inleveren alstublieft.
Tentamen Kansrekening en Statistiek MST 14 januari 2016, uur
 Tentamen Kansrekening en Statistiek MST 14 januari 2016, 14.00 17.00 uur Het tentamen bestaat uit 15 meerkeuzevragen 2 open vragen. Een formuleblad wordt uitgedeeld. Normering: 0.4 punt per MC antwoord
Tentamen Kansrekening en Statistiek MST 14 januari 2016, 14.00 17.00 uur Het tentamen bestaat uit 15 meerkeuzevragen 2 open vragen. Een formuleblad wordt uitgedeeld. Normering: 0.4 punt per MC antwoord
Kansrekening en statistiek wi2105in deel 2 16 april 2010, uur
 Kansrekening en statistiek wi205in deel 2 6 april 200, 4.00 6.00 uur Bij dit examen is het gebruik van een (evt. grafische) rekenmachine toegestaan. Tevens krijgt u een formuleblad uitgereikt na afloop
Kansrekening en statistiek wi205in deel 2 6 april 200, 4.00 6.00 uur Bij dit examen is het gebruik van een (evt. grafische) rekenmachine toegestaan. Tevens krijgt u een formuleblad uitgereikt na afloop
Deeltentamen 2 Algemene Statistiek Vrije Universiteit 18 december 2013
 Afdeling Wiskunde Volledig tentamen Algemene Statistiek Deeltentamen 2 Algemene Statistiek Vrije Universiteit 18 december 2013 Gebruik van een (niet-grafische) rekenmachine is toegestaan. Geheel tentamen:
Afdeling Wiskunde Volledig tentamen Algemene Statistiek Deeltentamen 2 Algemene Statistiek Vrije Universiteit 18 december 2013 Gebruik van een (niet-grafische) rekenmachine is toegestaan. Geheel tentamen:
HOOFDSTUK II BIJZONDERE THEORETISCHE VERDELINGEN
 HOOFDSTUK II BIJZONDERE THEORETISCHE VERDELINGEN. Continue Verdelingen 1 A. De uniforme (of rechthoekige) verdeling Kansdichtheid en cumulatieve frequentiefunctie Voor x < a f(x) = 0 F(x) = 0 Voor a x
HOOFDSTUK II BIJZONDERE THEORETISCHE VERDELINGEN. Continue Verdelingen 1 A. De uniforme (of rechthoekige) verdeling Kansdichtheid en cumulatieve frequentiefunctie Voor x < a f(x) = 0 F(x) = 0 Voor a x
5.0 Voorkennis. Voorbeeld 1: In een vaas zitten 10 rode, 5 witte en 6 blauwe knikkers. Er worden 9 knikkers uit de vaas gepakt.
 5.0 Voorkennis Voorbeeld 1: In een vaas zitten 10 rode, 5 witte en 6 blauwe knikkers. Er worden 9 knikkers uit de vaas gepakt. a) Bereken de kans op minstens 7 rode knikkers: P(minstens 7 rood) = P(7 rood)
5.0 Voorkennis Voorbeeld 1: In een vaas zitten 10 rode, 5 witte en 6 blauwe knikkers. Er worden 9 knikkers uit de vaas gepakt. a) Bereken de kans op minstens 7 rode knikkers: P(minstens 7 rood) = P(7 rood)
Kansrekening en Statistiek
 Kansrekening en Statistiek College 12 Vrijdag 16 Oktober 1 / 38 2 Statistiek Indeling vandaag: Normale verdeling Wet van de Grote Getallen Centrale Limietstelling Deductieve statistiek Hypothese toetsen
Kansrekening en Statistiek College 12 Vrijdag 16 Oktober 1 / 38 2 Statistiek Indeling vandaag: Normale verdeling Wet van de Grote Getallen Centrale Limietstelling Deductieve statistiek Hypothese toetsen
Kansrekening en Statistiek
 Kansrekening en Statistiek College 12 Donderdag 21 Oktober 1 / 38 2 Statistiek Indeling: Stochast en populatie Experimenten herhalen Wet van de Grote Getallen Centrale Limietstelling 2 / 38 Deductieve
Kansrekening en Statistiek College 12 Donderdag 21 Oktober 1 / 38 2 Statistiek Indeling: Stochast en populatie Experimenten herhalen Wet van de Grote Getallen Centrale Limietstelling 2 / 38 Deductieve
Lesbrief hypothesetoetsen
 Lesbrief hypothesetoetsen 00 "Je gaat het pas zien als je het door hebt" Johan Cruijff Willem van Ravenstein Inhoudsopgave Inhoudsopgave... Hoofdstuk - voorkennis... Hoofdstuk - mens erger je niet... 3
Lesbrief hypothesetoetsen 00 "Je gaat het pas zien als je het door hebt" Johan Cruijff Willem van Ravenstein Inhoudsopgave Inhoudsopgave... Hoofdstuk - voorkennis... Hoofdstuk - mens erger je niet... 3
8. Analyseren van samenhang tussen categorische variabelen
 8. Analyseren van samenhang tussen categorische variabelen Er bestaat een samenhang tussen twee variabelen als de verdeling van de respons (afhankelijke) variabele verandert op het moment dat de waarde
8. Analyseren van samenhang tussen categorische variabelen Er bestaat een samenhang tussen twee variabelen als de verdeling van de respons (afhankelijke) variabele verandert op het moment dat de waarde
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica
 TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Uitwerking tentamen Kansrekening en Stochastische Processen (2S61) op woensdag 27 april 25, 14. 17. uur. 1. Gegeven zijn twee onafhankelijke
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Uitwerking tentamen Kansrekening en Stochastische Processen (2S61) op woensdag 27 april 25, 14. 17. uur. 1. Gegeven zijn twee onafhankelijke
Examen Statistiek I Januari 2010 Feedback
 Examen Statistiek I Januari 2010 Feedback Correcte alternatieven worden door een sterretje aangeduid. 1 Een steekproef van 400 personen bestaat uit 270 mannen en 130 vrouwen. Twee derden van de mannen
Examen Statistiek I Januari 2010 Feedback Correcte alternatieven worden door een sterretje aangeduid. 1 Een steekproef van 400 personen bestaat uit 270 mannen en 130 vrouwen. Twee derden van de mannen
Statistiek voor A.I. College 10. Donderdag 18 Oktober
 Statistiek voor A.I. College 10 Donderdag 18 Oktober 1 / 28 Huffington Post poll verkiezingen VS - 12 Oktober 2012 2 / 28 Gallup poll verkiezingen VS - 15 Oktober 2012 3 / 28 Jullie - onderzoek Kimberly,
Statistiek voor A.I. College 10 Donderdag 18 Oktober 1 / 28 Huffington Post poll verkiezingen VS - 12 Oktober 2012 2 / 28 Gallup poll verkiezingen VS - 15 Oktober 2012 3 / 28 Jullie - onderzoek Kimberly,
Hoofdstuk 8 Het toetsen van nonparametrische variabelen
 Hoofdstuk 8 Het toetsen van nonparametrische variabelen 8.1 Non-parametrische toetsen: deze toetsen zijn toetsen waarbij de aannamen van normaliteit en intervalniveau niet nodig zijn. De aannamen zijn
Hoofdstuk 8 Het toetsen van nonparametrische variabelen 8.1 Non-parametrische toetsen: deze toetsen zijn toetsen waarbij de aannamen van normaliteit en intervalniveau niet nodig zijn. De aannamen zijn
Lesbrief de normale verdeling
 Lesbrief de normale verdeling 2010 Willem van Ravenstein Inhoudsopgave Inhoudsopgave... 1 Hoofdstuk 1 de normale verdeling... 2 Hoofdstuk 2 meer over de normale verdeling... 11 Hoofdstuk 3 de n-wet...
Lesbrief de normale verdeling 2010 Willem van Ravenstein Inhoudsopgave Inhoudsopgave... 1 Hoofdstuk 1 de normale verdeling... 2 Hoofdstuk 2 meer over de normale verdeling... 11 Hoofdstuk 3 de n-wet...
Tentamen Kansrekening en Statistiek (2WS04), dinsdag 17 juni 2008, van uur.
, dinsdag 17 juni 2008, van uur.") Technische Universiteit Eindhoven Faculteit Wiskunde en Informatica Tentamen Kansrekening en Statistiek (2WS4, dinsdag 17 juni 28, van 9. 12. uur. Dit is een tentamen met gesloten boek. De uitwerkingen
Technische Universiteit Eindhoven Faculteit Wiskunde en Informatica Tentamen Kansrekening en Statistiek (2WS4, dinsdag 17 juni 28, van 9. 12. uur. Dit is een tentamen met gesloten boek. De uitwerkingen
DEZE PAGINA NIET vóór 8.30u OMSLAAN!
 STTISTIEK 1 VERSIE MT15303 1308 1 WGENINGEN UNIVERSITEIT LEERSTOELGROEP MT Tentamen Statistiek 1 (MT-15303) 5 augustus 2013, 8.30-10.30 uur EZE PGIN NIET vóór 8.30u OMSLN! STRT MET INVULLEN VN NM, REGISTRTIENUMMER,
STTISTIEK 1 VERSIE MT15303 1308 1 WGENINGEN UNIVERSITEIT LEERSTOELGROEP MT Tentamen Statistiek 1 (MT-15303) 5 augustus 2013, 8.30-10.30 uur EZE PGIN NIET vóór 8.30u OMSLN! STRT MET INVULLEN VN NM, REGISTRTIENUMMER,
Statistiek, gegevens en een kritische houding
 Statistiek Hoofdstuk 1. Statistiek, gegevens en een kritische houding 1.1. Statistiek 1.2. De wetenschap statistiek de wetenschap van gegevens verzamelen evalueren (classificeren, samenvatten, organiseren,
Statistiek Hoofdstuk 1. Statistiek, gegevens en een kritische houding 1.1. Statistiek 1.2. De wetenschap statistiek de wetenschap van gegevens verzamelen evalueren (classificeren, samenvatten, organiseren,
Kansrekening en Statistiek
 Kansrekening en Statistiek College 11 Dinsdag 25 Oktober 1 / 27 2 Statistiek Vandaag: Hypothese toetsen Schatten 2 / 27 Schatten 3 / 27 Vragen: liegen 61 Amerikanen werd gevraagd hoeveel % van de tijd
Kansrekening en Statistiek College 11 Dinsdag 25 Oktober 1 / 27 2 Statistiek Vandaag: Hypothese toetsen Schatten 2 / 27 Schatten 3 / 27 Vragen: liegen 61 Amerikanen werd gevraagd hoeveel % van de tijd
Statistiek voor Natuurkunde Opgavenserie 1: Kansrekening
 Statistiek voor Natuurkunde Opgavenserie 1: Kansrekening Inleveren: 12 januari 2011, VOOR het college Afspraken Serie 1 mag gemaakt en ingeleverd worden in tweetallen. Schrijf duidelijk je naam, e-mail
Statistiek voor Natuurkunde Opgavenserie 1: Kansrekening Inleveren: 12 januari 2011, VOOR het college Afspraken Serie 1 mag gemaakt en ingeleverd worden in tweetallen. Schrijf duidelijk je naam, e-mail
Kansrekening en stochastische processen 2S610
 Kansrekening en stochastische processen 2S610 Docent : Jacques Resing E-mail: j.a.c.resing@tue.nl http://www.win.tue.nl/wsk/onderwijs/2s610 1/28 Schatten van de verwachting We hebben een stochast X en
Kansrekening en stochastische processen 2S610 Docent : Jacques Resing E-mail: j.a.c.resing@tue.nl http://www.win.tue.nl/wsk/onderwijs/2s610 1/28 Schatten van de verwachting We hebben een stochast X en
Inleiding Statistiek
 Inleiding Statistiek Practicum 1 Op dit practicum herhalen we wat Matlab. Vervolgens illustreren we het schatten van een parameter en het toetsen van een hypothese met een klein simulatie experiment. Het
Inleiding Statistiek Practicum 1 Op dit practicum herhalen we wat Matlab. Vervolgens illustreren we het schatten van een parameter en het toetsen van een hypothese met een klein simulatie experiment. Het
1BA PSYCH Statistiek 1 Oefeningenreeks 3 1
 Juno KOEKELKOREN D.1.3. OEFENINGENREEKS 3 OEFENING 1 In onderstaande tabel vind je zes waarnemingen van twee variabelen (ratio meetniveau). Eén van de waarden van y is onbekend. Waarde x y 1 1 2 2 9 2
Juno KOEKELKOREN D.1.3. OEFENINGENREEKS 3 OEFENING 1 In onderstaande tabel vind je zes waarnemingen van twee variabelen (ratio meetniveau). Eén van de waarden van y is onbekend. Waarde x y 1 1 2 2 9 2
OefenDeeltentamen 2 Kansrekening 2011/ Beschouw een continue stochast X met kansdichtheidsfunctie cx 4, 0 x 1 f X (x) = f(x) = 0, anders.
 = f(x) = 0, anders.") Universiteit Utrecht *=Universiteit-Utrecht Boedapestlaan 6 Mathematisch Instituut 3584 CD Utrecht OefenDeeltentamen Kansrekening 11/1 1. Beschouw een continue stochast X met kansdichtheidsfunctie c 4,
Universiteit Utrecht *=Universiteit-Utrecht Boedapestlaan 6 Mathematisch Instituut 3584 CD Utrecht OefenDeeltentamen Kansrekening 11/1 1. Beschouw een continue stochast X met kansdichtheidsfunctie c 4,
werkcollege 6 - D&P10: Hypothesis testing using a single sample
 cursus huiswerk opgaven Ch.9: 1, 8, 11, 12, 20, 26, 36, 37, 71 werkcollege 6 - D&P10: Hypothesis testing using a single sample Activities 9.3 en 9.4 van schatting naar toetsing vorige bijeenkomst: populatie-kenmerk
cursus huiswerk opgaven Ch.9: 1, 8, 11, 12, 20, 26, 36, 37, 71 werkcollege 6 - D&P10: Hypothesis testing using a single sample Activities 9.3 en 9.4 van schatting naar toetsing vorige bijeenkomst: populatie-kenmerk
Toetsen van hypothesen
 Les 4 Toetsen van hypothesen We hebben tot nu toe enigszins algemeen naar grootheden van populaties gekeken en bediscussieerd hoe we deze grootheden uit steekproeven kunnen schatten. Vaak hebben we echter
Les 4 Toetsen van hypothesen We hebben tot nu toe enigszins algemeen naar grootheden van populaties gekeken en bediscussieerd hoe we deze grootheden uit steekproeven kunnen schatten. Vaak hebben we echter
Wiskunde B - Tentamen 2
 Wiskunde B - Tentamen Tentamen van Wiskunde B voor CiT (57) Donderdag 4 april 005 van 900 tot 00 uur Dit tentamen bestaat uit 8 opgaven, 3 tabellen en formulebladen Vermeld ook je studentnummer op je werk
Wiskunde B - Tentamen Tentamen van Wiskunde B voor CiT (57) Donderdag 4 april 005 van 900 tot 00 uur Dit tentamen bestaat uit 8 opgaven, 3 tabellen en formulebladen Vermeld ook je studentnummer op je werk
6.1 Beschouw de populatie die beschreven wordt door onderstaande kansverdeling.
 Opgaven hoofdstuk 6 I Basistechnieken 6.1 Beschouw de populatie die beschreven wordt door onderstaande kansverdeling. x 0 2 4 6 p(x) ¼ ¼ ¼ ¼ a. Schrijf alle mogelijke verschillende steekproeven van n =
Opgaven hoofdstuk 6 I Basistechnieken 6.1 Beschouw de populatie die beschreven wordt door onderstaande kansverdeling. x 0 2 4 6 p(x) ¼ ¼ ¼ ¼ a. Schrijf alle mogelijke verschillende steekproeven van n =
introductie toetsen power pauze hypothesen schatten ten slotte introductie toetsen power pauze hypothesen schatten ten slotte
 toetsende statistiek week 1: kansen en random variabelen week 2: de steekproevenverdeling week 3: schatten en toetsen: de z-toets Moore, McCabe, and Craig. Introduction to the Practice of Statistics Chapter
toetsende statistiek week 1: kansen en random variabelen week 2: de steekproevenverdeling week 3: schatten en toetsen: de z-toets Moore, McCabe, and Craig. Introduction to the Practice of Statistics Chapter
Introductie tot de statistiek
 Introductie tot de statistiek Hogeschool Gent 04/05/2010 Inhoudsopgave 1 Basisbegrippen en beschrijvende statistiek 8 1.1 Onderzoek............................ 8 1.1.1 Data........................... 8
Introductie tot de statistiek Hogeschool Gent 04/05/2010 Inhoudsopgave 1 Basisbegrippen en beschrijvende statistiek 8 1.1 Onderzoek............................ 8 1.1.1 Data........................... 8
Kansrekening en Statistiek
 Kansrekening en Statistiek College 9 Dinsdag 18 Oktober 1 / 1 2 Statistiek Vandaag: Centrale Limietstelling Correlatie Regressie 2 / 1 Centrale Limietstelling 3 / 1 Centrale Limietstelling St. (Centrale
Kansrekening en Statistiek College 9 Dinsdag 18 Oktober 1 / 1 2 Statistiek Vandaag: Centrale Limietstelling Correlatie Regressie 2 / 1 Centrale Limietstelling 3 / 1 Centrale Limietstelling St. (Centrale
= P(B) = 2P(C), P(A B) = 1 2 en P(A C) = 2 5. d. 31
 = 2P(C), P(A B) = 1 2 en P(A C) = 2 5. d. 31") Tentamen Statistische methoden 45STAMEY april, 9: : Studienummers: Vult u alstublieft op het MC formulier uw Delftse studienummer in; en op het open vragen formulier graag beide, naar volgend voorbeeld:
Tentamen Statistische methoden 45STAMEY april, 9: : Studienummers: Vult u alstublieft op het MC formulier uw Delftse studienummer in; en op het open vragen formulier graag beide, naar volgend voorbeeld:
Algemeen overzicht inleiding kansrekening en statistiek
 Algemeen overzicht inleiding kansrekening en statistiek Robert Fitzner Tim Hulshof 7 Oktober 202 v.3 Voorwoord Deze tekst geeft een overzicht van de stof die behandeld wordt in de meeste cursussen inleiding
Algemeen overzicht inleiding kansrekening en statistiek Robert Fitzner Tim Hulshof 7 Oktober 202 v.3 Voorwoord Deze tekst geeft een overzicht van de stof die behandeld wordt in de meeste cursussen inleiding
Tentamen Mathematische Statistiek (2WS05), dinsdag 3 november 2009, van uur.
, dinsdag 3 november 2009, van uur.") Technische Universiteit Eindhoven Faculteit Wiskunde en Informatica Tentamen Mathematische Statistiek (2WS05), dinsdag 3 november 2009, van 4.00 7.00 uur. Dit is een tentamen met gesloten boek. De uitwerkingen
Technische Universiteit Eindhoven Faculteit Wiskunde en Informatica Tentamen Mathematische Statistiek (2WS05), dinsdag 3 november 2009, van 4.00 7.00 uur. Dit is een tentamen met gesloten boek. De uitwerkingen
3de bach HI. Econometrie. Volledige samenvatting. uickprinter Koningstraat Antwerpen A 11,00
 3de bach HI Econometrie Volledige samenvatting Q www.quickprinter.be uickprinter Koningstraat 13 2000 Antwerpen 170 A 11,00 Practicum 0: Herhaling statistiek Hier vindt u een kort overzicht van enkele
3de bach HI Econometrie Volledige samenvatting Q www.quickprinter.be uickprinter Koningstraat 13 2000 Antwerpen 170 A 11,00 Practicum 0: Herhaling statistiek Hier vindt u een kort overzicht van enkele
Kanstheorie, -rekenen en bekende verdelingen
 Kanstheorie, -rekenen en bekende verdelingen 1 Rekenregels kansrekenen Kans van de zekere gebeurtenis: P () = P (U) = 1 Kans van de onmogelijke gebeurtenis: P (;) = 0 Complementregel: P (A c ) = 1 P (A)
Kanstheorie, -rekenen en bekende verdelingen 1 Rekenregels kansrekenen Kans van de zekere gebeurtenis: P () = P (U) = 1 Kans van de onmogelijke gebeurtenis: P (;) = 0 Complementregel: P (A c ) = 1 P (A)
Toetsende Statistiek Week 3. Statistische Betrouwbaarheid & Significantie Toetsing
 Toetsende Statistiek Week 3. Statistische Betrouwbaarheid & Significantie Toetsing M, M & C, Chapter 6, Introduction to Inference 6.1 Estimating with Confidence 6.2 Tests of Significance 6.3 Use and Abuse
Toetsende Statistiek Week 3. Statistische Betrouwbaarheid & Significantie Toetsing M, M & C, Chapter 6, Introduction to Inference 6.1 Estimating with Confidence 6.2 Tests of Significance 6.3 Use and Abuse
Voorbeeld 1: kansverdeling discrete stochast discrete kansverdeling
 12.0 Voorkennis Voorbeeld 1: Yvette pakt vier knikkers uit een vaas waar er 20 inzitten. 9 van de knikkers zijn rood en 11 van de knikkers zijn blauw. X = het aantal rode knikkers dat Yvette pakt. Er zijn
12.0 Voorkennis Voorbeeld 1: Yvette pakt vier knikkers uit een vaas waar er 20 inzitten. 9 van de knikkers zijn rood en 11 van de knikkers zijn blauw. X = het aantal rode knikkers dat Yvette pakt. Er zijn
toetsende statistiek deze week: wat hebben we al geleerd? Frank Busing, Universiteit Leiden
 toetsende statistiek week 1: kansen en random variabelen week 2: de steekproevenverdeling week 3: schatten en toetsen: de z-toets week 4: het toetsen van gemiddelden: de t-toets Moore, McCabe, and Craig.
toetsende statistiek week 1: kansen en random variabelen week 2: de steekproevenverdeling week 3: schatten en toetsen: de z-toets week 4: het toetsen van gemiddelden: de t-toets Moore, McCabe, and Craig.