Een inleiding tot taaltechnologie
|
|
|
- Ine Veerle Bakker
- 8 jaren geleden
- Aantal bezoeken:
Transcriptie
1 Academia Plutonicana Een inleiding tot taaltechnologie Peter Dirix 15 december 2010 Lange Trappen, Leuven

2 Academia Plutonicana Overzicht Overzicht & terminologie Formele taaltheorie Voorbeelden uit automatische vertaling en spraakherkenning 2

3 Academia Plutonicana Taaltechnologie Verschillende benamingen: - Taaltechnologie (LT) - Computertaalkunde (CL) - Natuurlijketaalverwerking (NLP) - Spraak- en taalverwerking (SLP) 3
 - Spraak- en")


4 Tekst en spraak Spraakcompressie Spraak Tekst Spraak Tekst Automatische vertaling / samenvatting Spraakherkenning Spraakgeneratie 4

5 Domeinen Spraakherkenning (ASR) Spraakgeneratie / spraaksynthese (TTS) Automatische vertaling (MT) Automatisch samenvatten Dialoogsystemen Informatieontsluiting en extractie (IR/IE) Natuurlijketaalbegrip (NLU) Spelling- en grammaticacontrole Vertaalgeheugens 5
 Spelling- en grammaticacontrole")
6 Taal Klanken (fonetiek & fonologie) Woordenschat / lexicon Syntaxis / grammatica Semantiek / betekenis Pragmatiek / context 6

7 Problemen met taal Ambiguïteit - woordenschat - homofonie - syntactische ambiguïteit Woordenschat is productief 7

8 Filosofie Wanneer is een systeem intelligent? Turingtest (1950) ELIZA (1966) Kunstmatige intelligentie 8
 Kunstmatige")
9 Korte geschiedenis 1939: Eerste spraaksynthese (Bell Labs) Jaren 40-50: theoretische beschouwingen Turing, Shannon Formeletaaltheorie (Chomsky, 1956) Vanaf jaren 50: automatische vertaling 1952: Eerste spraakherkenner (Bell Labs) 1976: Statistische aanpak Jaren 90: commerciële softwarepakketten & hybride systemen 9
 1976: Statistische aanpak Jaren 90: commerciële softwarepakketten &")
10 Tools (1) Tokeniseren: tekst terugbrengen naar tokens - atomaire eenheden (club,., New York) Morfologische analyse (terugbrengen van een token tot woordenboekvorm, maar ook stemming, herkennen van samenstellingen, afleidingen, voor- en achtervoegsels, ) 10

11 Tools (2) Syntactische analyse (herkenning van woordklasse, functie in de zin) Semantische analyse (zoekt bv. het antecedent van een betrekkelijk voornaamwoord) Pragmatische analyse (analyseert bv. of een tekst formeel of niet-formeel is) 11

12 Formele grammatica s (1) Symbolen: terminale en niet-terminale Herschrijfregels 5 types: - constituentenstructuurgrammatica s (PSGs, 0) - contextgevoelige grammatica s (CSGs, 1) - contextvrije grammatica s (CFGs, 2) - eindigetoestandsgrammatica s (FSGs, 3) - eindigekeuzegrammatica s (FCGs, 4) 12
 - eindigetoestandsgrammatica s (FSGs, 3) -")
13 Formele grammatica s (2) S -> NP VP NP -> Pronoun VP -> V V -> wandel loop Pronoun -> ik 13

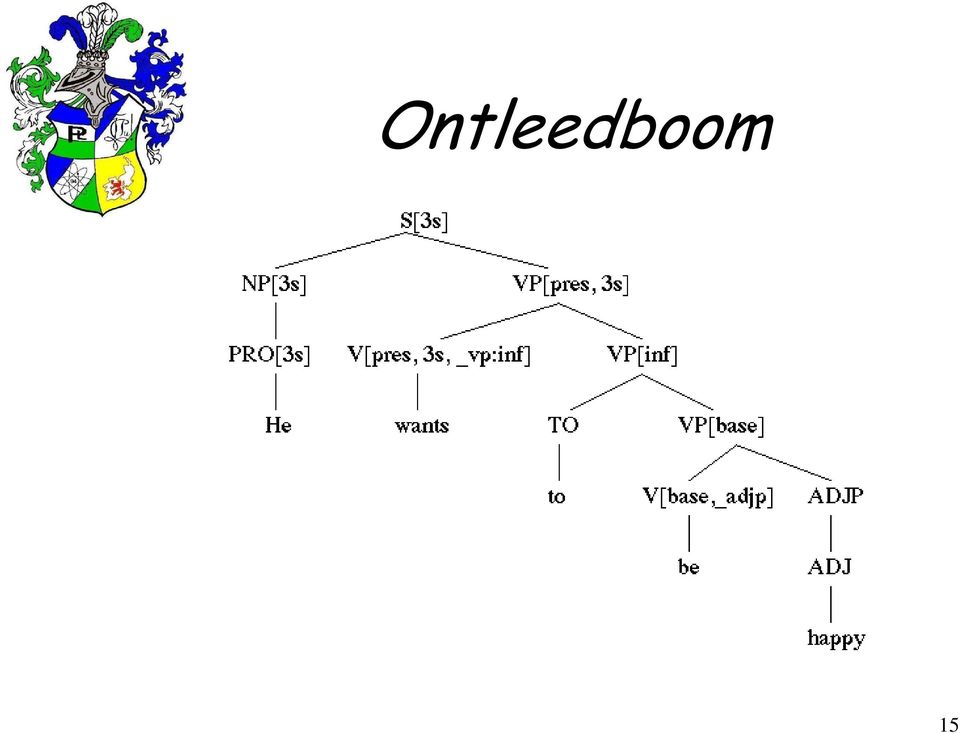
14 Analyse: parsers Parser of ontleder is programma dat deze analyse doet Verschillende benaderingen: - top-down / bottom-up - breedte-eerst / diepte-eerst Creëert een ontleedboom die de analyse bevat 14

15 Ontleedboom 15
16 Regelgebaseerde automatische vertaling Analyse van brontaal, minimaal morfologisch en syntactisch Gebruik van vertaalwoordenboek Gebruik van regels, bv. Spa-Eng: zelfst.+bijv. nw. -> bijv.+zelfst. nw. Eventueel nog herschrijfregels (postprocessor) in doeltaal Bv. SYSTRAN, EUROTRA, METEO 16

17 Spraakherkenning: geschiedenis (1) 1952: Eerste spraakherkenner (Bell Labs) 1969: Darpa begint financiering 1976: Eerste statistische modellen (IBM) Jaren 80: Eerste toepassingen (Dragon Systems, IBM, Kurzweil) 1990: Eerste dicteertoepassing (Dragon) 1997: IBM ViaVoice (eerste PC-toepassing) 1997: DragonNaturallySpeaking 1998: VoiceXpress (Lernout & Hauspie) 17
 1997: DragonNaturallySpeaking 1998: VoiceXpress (Lernout & Hauspie)")
18 Spraakherkenning: geschiedenis (2) 1997: L&H koopt Kurzweil 2000: L&H koopt Dragon en Dictaphone 2001: faillissement L&H; gekocht door Scansoft 2003: Scansoft koopt Speechworks en Philips Speech 2005: Scansoft koopt Nuance, nieuwe naam 2006: Nuance koopt Dictaphone 2009: Nuance koopt IBM-patenten 2010: 3 grote spelers Nuance, Google, Microsoft 18

19 Types spraakherkenning Sprekeronafhankelijk - geen training - beperkte woordenschat - meestal gebruikt in mobiele toepassingen Sprekerafhankelijk - systeem wordt getraind per gebruiker - algemeen akoestisch model - taalmodel per gebruiker - uitgebreide woordenschat - gebruikt in dicteertoepassingen 19

20 Gesproken taal Spraakherkenning: proces Microfoon Sampling Analoog -> Digitaal Foneemherkenning Woordherkenning Contextcontrole Geluidssignaal Analoog Signaal Analoog Signaal Digitaal Signaal Fonemen Karakters / woord Tekst 20

21 Spraakherkenning: aanpak (1) Statistische benadering Spraakherkenningspakket bestaat uit: - akoestisch model (AM) - taalmodel (LM) - herkenner: zoekalgoritme * analyse van signaal * transformeert signaal naar een woord 21
22 Spraakherkenning: aanpak (2) Stochastische aanpak maakt gebruik van de inherente statistische eigenschappen van het samen en gecombineerd voorkomen van individuele spraaksegmenten woordvolgorde: W = w 1, w 2,, w n foneemvolgorde: P = p 1, p 2,, p m V Z akoestiek (spraakspectrumvectoren): Y = y 1, y 2,..., y t. W = argmax P(W Y) W'= argmax P(W) P(Y W) / P(Y) 22
23 Akoestisch model (1) W'= argmax P(W) P(Y W) P(Y W) akoestisch model (waarschijnlijkheid voor een willek. vectorvolgorde Y, gegeven woord W) Invoersignaal Dictaphone Spectraalanalyse Reeks akoestische vectoren: Y=(y1,y2,y3,.., yk) Woordenboek Dictaphone (y1,y2,y3,.., yk), (y11,y7,y23,.., ym),... Dictanet (y1,y2,y3,.., yk), (y1,y17,y23,.., yt), P(Y W) akoest. score P(Y Dictaphone )=S1 P(Y Dictanet )=S2 P(Y telefoon )=S3 Max(S1,S2,S3) telefoon (y5,y2,y13,.., yk), (y1,y71,y3,.., yn),... Beste kandidaat 23
24 Akoestisch model (2) Woorden ontbinden in fonemen (30-70 per taal) Toevoegen pauzevullers, geluiden, etc. Fonemen groeperen in trifonen: test t-e-s en e-s-t Elke trifoon wordt voorgesteld door een reeks toestanden (2 à 3) Gemodelleerd door verborgen markovmodel (HMM) Overgang tussen toestanden volgens viterbialgoritme 24
25 Akoestisch model (3): HMM Probabilistische overgang tussen toestanden (a ij ) Iedere toestand produceert akoestische vector y t met waarschijnlijkheid b j (y t ) P(Y) = a 12 b 2 (y 1 ) a 22 b 2 (y 2 ) a 23 b 3 (y 3 ) 25
26 Akoestisch model (4): training Selecteer verzameling fonemen Transcribeer alle woorden fonetisch volgens deze verzameling Definieer het aantal toestanden/foneem Representatieve datacollectie: man/vrouw, leeftijd, opleiding, regio, Train het HMM door voor elke trifoon te berekenen: - overgangswaarschijnlijkheden tussen de toestanden (a ij ) - productiewaarschijnlijkheden voor een bepaalde akoestische vector b j (y t ) 26
27 Akoestisch model (5): aanpassing aan spreker Gebruiker leest aantal teksten Voor elk audio-/tekstpaar gaan we de tekst herkennen en vergelijken met wat er herkend zou moeten zijn Aligneren Indien er een goede herkenning is en consistente verschillen, wordt het AM aangepast 27
28 Akoestisch model (6): aanpassing aan spreker Aanpassing aan spreker verbetert herkenning bij: - consequent gewestelijk accent - consequente omgevingsgeluiden - consequente dicteersnelheid Aanpassing aan spreker lost niets op bij: - consequent verkeerd uitspreken van individuele woorden - gebruik van woorden die niet in woordenboek zitten - plotse veranderingen in omgevingsgeluiden - inconsequent dicteergedrag 28
29 Taalmodel (1) W'= argmax P(W) P(Y W) P(Y W) Akoestisch model P(W) Taalmodel Modelleert syntaxis en semantiek Modelleert lokale afhankelijkheid Akoestisch model genereert hypothesen Taalmodel geeft een score aan deze hypothesen: P(W = w 1, w 2,, w n ) = P(w n w 1, w 2,, w n-1 ) Akoestisch model per taal, taalmodel per domein/gebruiker 29
30 Taalmodel (2) Spraakherkenners gebruiken eenvoudig taalmodel: n-grammen - bigram: P(W) = P(w n w n-1 ) - trigram: P(W) = P(w n w n-2, w n-1 ) - 4-gram: P(W) = P(w n w n-3, w n-2, w n-1 ) Probleem: extreem groot aantal mogelijke tri-/4-grammen (data sparsity) Opvangen door terug te vallen op bigrammen of woordklassemodellen 30
31 Taalmodel (3) Sommige trigrammen veel frequenter dan andere: geachte heer,\komma is veel waarschijnlijker dan geachte meer bonen Tegenwoordig ongeveer unigrammen en een paar tientallen miljoenen bi-, tri- en 4-grammen, bv. «De vrouw zou ongeveer dertig jaar oud zijn.» de vrouw zou 1 vrouw zou ongeveer 1 zou ongeveer dertig 1 ongeveer dertig jaar 1 dertig jaar oud 1 jaar oud zijn 1 oud zijn.\punt 1 31
32 Taalmodel (4): training Zeer veel data nodig: There s no better data than more data Representatieve datacollectie: veel auteurs, types tekst, regio, opleiding, Terugbrengen naar standaardformaat Maken fonetische transcripties voor nieuwe woorden (pronning), bv. spraakherkenning 'sprak-her-ke-nin Nieuw taalmodel berekenen 32
33 Postprocessor Regelgebaseerd Herschrijft getallen, data, tijden, telefoonnummers etc. naar een door de gebruiker gekozen formaat, bv. 15/12/2010, 15 december 2010, , Zorgt er ook voor dat leestekens juist geplaatst worden, bv. een punt wordt tegen het vorige woord geplakt 33
34 Uitdagingen in spraakherkenning Veranderlijkheid tussen sprekers: lengte stemkanaal, taalsociologische factoren (moedertaal, accent, opleiding) Veranderlijkheid bij dezelfde spreker: verkoudheid, emoties Veranderlijkheid in de omgeving Coarticulatie, prosodie, etc. Dicteergewoonten van de gebruiker Verwachtingspatroon van de gebruiker 34
35 Terug naar automatische vertaling Jaren 50: Heilige Graal 1966: vernietigend rapport Problemen: - rekenkracht computers - ontwikkeling van regels en woordenboeken is heel arbeidsintensief 35
36 Spraakherkenning en SMT Jaren 80: statistische modellen o.i.v. spraaktechnologen Statistische automatische vertaling (SMT) Nood aan parallelle corpora Taalmodellen: - taalmodel brontaal - vertaalmodel - taalmodel doeltaal Voorloper: IBM Zelfde n-grammodel als spraakherkenning 36
37 SMT (2) Ander type problemen: data sparsity, er zijn geen regels Voordeel: snel en goedkoop te ontwikkelen, geen linguïstische kennis nodig Belangrijkste commerciële ontwikkelaars: Google, Microsoft (intern) 37
38 EBMT Variant: voorbeeldgebaseerde automatische vertaling (EBMT) Gedeeltelijk statistisch Zoekt voorbeelden in vertaling en probeert die samen te plakken Lijkt op wat vertaalgeheugens doen 38
39 Nu Hybride systemen: SMT en EBMT met regelgebaseerde componenten Gebruik van taalkundige informatie in SMT en EBMT Gebruik van gelijkende i.p.v. parallelle corpora 39
40 De toekomst Hybride systemen Ontwikkeling van benodigde data (cfr. Stevinproject van de NTU) Combinatie van domeinen: automatische vertaling van spraak, NLU in dialoogsystemen, automatische ondertiteling, information retrieval in telefoongesprekken (spionage) 40
41 Meer info Bijvoorbeeld: Daniel Jurafsky & James H. Martin, Speech and Language Processing, 2nd edition, Pearson Education,
Spraaktechnologie. Gerrit Bloothooft.
 Spraaktechnologie Gerrit Bloothooft Gerrit.Bloothooft@let.uu.nl Communicatie taal was er eerst als spraak en gebaar pas veel later als schrift - en lezen en schrijven (eerste taaltechnologie) Taal- en
Spraaktechnologie Gerrit Bloothooft Gerrit.Bloothooft@let.uu.nl Communicatie taal was er eerst als spraak en gebaar pas veel later als schrift - en lezen en schrijven (eerste taaltechnologie) Taal- en
Natuurlijke-Taalverwerking I
 1 atuurlijke-taalverwerking I Gosse Bouma en Geert Kloosterman (pract) 2e semester 2005/2006 Overzicht Week1 : Inleiding, Context-vrije grammatica. Week 2-3 : Definite Clause Grammar Regels, gebruik van
1 atuurlijke-taalverwerking I Gosse Bouma en Geert Kloosterman (pract) 2e semester 2005/2006 Overzicht Week1 : Inleiding, Context-vrije grammatica. Week 2-3 : Definite Clause Grammar Regels, gebruik van
Ontsluiten van gesproken documenten. Arjan van Hessen
 SpraakTech Ontsluiten van gesproken documenten Arjan van Hessen spraak tekst spraak verslag emotiedetectie emotiedetectie geeft GEEN antwoord op vragen herkennen van sprekers groeperen van verschillende
SpraakTech Ontsluiten van gesproken documenten Arjan van Hessen spraak tekst spraak verslag emotiedetectie emotiedetectie geeft GEEN antwoord op vragen herkennen van sprekers groeperen van verschillende
Natuurlijke-taalverwerking 1. Daniël de Kok
 Natuurlijke-taalverwerking 1 Daniël de Kok Natuurlijke-Taalverwerking Het college Natuurlijke-taalverwerking is een inleiding in de computationele taalkunde en maakt deel uit van het curriculum van Informatiekunde
Natuurlijke-taalverwerking 1 Daniël de Kok Natuurlijke-Taalverwerking Het college Natuurlijke-taalverwerking is een inleiding in de computationele taalkunde en maakt deel uit van het curriculum van Informatiekunde
Spreekvaardigheidstraining met behulp van Automatische Spraak-Herkenning (ASH)
") Spreekvaardigheidstraining met behulp van Automatische Spraak-Herkenning (ASH) Helmer Strik Afdeling Taalwetenschap Centre for Language and Speech Technology (CLST) Radboud Universiteit Nijmegen Overview
Spreekvaardigheidstraining met behulp van Automatische Spraak-Herkenning (ASH) Helmer Strik Afdeling Taalwetenschap Centre for Language and Speech Technology (CLST) Radboud Universiteit Nijmegen Overview
Onderlinge verstaanbaarheid van Nederlands en Duits
 Onderlinge verstaanbaarheid van Nederlands en Duits Onderlinge verstaanbaarheid van Nederlandse en Duitse cognaten gemodelleerd met behulp van automatische spraakherkenning Vincent J. van Heuven, Charlotte
Onderlinge verstaanbaarheid van Nederlands en Duits Onderlinge verstaanbaarheid van Nederlandse en Duitse cognaten gemodelleerd met behulp van automatische spraakherkenning Vincent J. van Heuven, Charlotte
Personiceren van stemmen met Deep Learning
 Personiceren van stemmen met Deep Learning Kan het Nationaal Archief straks teksten voorlezen met de stem van Joop den Uyl? Esther Judd-Klabbers 20 September 2016 Overzicht Introduction Statistische Parametrische
Personiceren van stemmen met Deep Learning Kan het Nationaal Archief straks teksten voorlezen met de stem van Joop den Uyl? Esther Judd-Klabbers 20 September 2016 Overzicht Introduction Statistische Parametrische
Het Nederlands en Taal en Spraaktechnologie
 Het Nederlands en Taal en Spraaktechnologie Amsterdam 18 Oktober 2012 Jan Odijk 1 Overzicht META-NET Studie Het Nederlands in de META-NET studie Het Nederlands in Nuance Spraaktechnologie De ontwikkeling
Het Nederlands en Taal en Spraaktechnologie Amsterdam 18 Oktober 2012 Jan Odijk 1 Overzicht META-NET Studie Het Nederlands in de META-NET studie Het Nederlands in Nuance Spraaktechnologie De ontwikkeling
Inleiding: Combinaties
 Zinnen 1 Inleiding: Combinaties Combinaties op verschillende niveaus: Lettergrepen als combinaties van fonemen. Woorden als combinaties van morfemen. Zinnen als combinaties van woorden en woordgroepen.
Zinnen 1 Inleiding: Combinaties Combinaties op verschillende niveaus: Lettergrepen als combinaties van fonemen. Woorden als combinaties van morfemen. Zinnen als combinaties van woorden en woordgroepen.
Taalkunde en Computertaalkunde in de Lage Landen: een verhouding die eerst spannend was, dan gespannen en nu gewoon ontspannen
 Taalkunde en Computertaalkunde in de Lage Landen: een verhouding die eerst spannend was, dan gespannen en nu gewoon ontspannen Frank Van Eynde Centrum voor Computerlinguïstiek KULeuven CLIN 25, Antwerpen,
Taalkunde en Computertaalkunde in de Lage Landen: een verhouding die eerst spannend was, dan gespannen en nu gewoon ontspannen Frank Van Eynde Centrum voor Computerlinguïstiek KULeuven CLIN 25, Antwerpen,
Tentamen Spraakherkenning en -synthese
 Tentamen Spraakherkenning en -synthese Rob van Son 25 maart 2008 Vermeld op iedere pagina je naam, je studentnummer en het volgnummer per pagina. Gebruik voor elke opgave (1-5) een apart vel. Als je voor
Tentamen Spraakherkenning en -synthese Rob van Son 25 maart 2008 Vermeld op iedere pagina je naam, je studentnummer en het volgnummer per pagina. Gebruik voor elke opgave (1-5) een apart vel. Als je voor
Onderwijs- en examenregeling
 Onderwijs- en examenregeling geldig vanaf 1 september 2016 Opleidingsspecifiek deel: Bacheloropleiding: Taalwetenschap Deze Onderwijs- en examenregeling is opgesteld overeenkomstig artikel 7.13 van de
Onderwijs- en examenregeling geldig vanaf 1 september 2016 Opleidingsspecifiek deel: Bacheloropleiding: Taalwetenschap Deze Onderwijs- en examenregeling is opgesteld overeenkomstig artikel 7.13 van de
Studentnummer: Inleiding Taalkunde 2013 Eindtoets Zet op ieder vel je naam en studentnummer!
 Inleiding Taalkunde 2013 Eindtoets Zet op ieder vel je naam en studentnummer! Dit tentamen bestaat uit 7 vragen. Lees elke vraag goed, en gebruik steeds de witte ruimte op de pagina, of de achterkant van
Inleiding Taalkunde 2013 Eindtoets Zet op ieder vel je naam en studentnummer! Dit tentamen bestaat uit 7 vragen. Lees elke vraag goed, en gebruik steeds de witte ruimte op de pagina, of de achterkant van
Natuurlijke-taalverwerking
 Natuurlijke-taalverwerking Parse disambiguatie Week 6 Overzicht Probabilistische CFG Parsen met PCFG Afleiden van PCFG uit treebank Evaluatie Disambiguatie voor unificatiegrammatica s Disambiguatie Ambiguïteit:
Natuurlijke-taalverwerking Parse disambiguatie Week 6 Overzicht Probabilistische CFG Parsen met PCFG Afleiden van PCFG uit treebank Evaluatie Disambiguatie voor unificatiegrammatica s Disambiguatie Ambiguïteit:
Inleiding taalkunde. Inleiding - 23 april 2013 Marieke Schouwstra
 Inleiding taalkunde Inleiding - 23 april 2013 Marieke Schouwstra 1 Dit college Overzicht cursus Wat is natuurlijke taal? Wat is taalkunde? 2 Docenten Marieke Schouwstra taalevolutie en betekenis Yoad Winter
Inleiding taalkunde Inleiding - 23 april 2013 Marieke Schouwstra 1 Dit college Overzicht cursus Wat is natuurlijke taal? Wat is taalkunde? 2 Docenten Marieke Schouwstra taalevolutie en betekenis Yoad Winter
Schriftelijk tentamen Spraakherkenning en spraaksynthese (do. 23 december 2004, 13.30 16.30 u; zaal C.206)
") Schriftelijk tentamen Spraakherkenning en spraaksynthese (do. 23 december 2004, 13.30 16.30 u; zaal C.206) Vermeld op iedere pagina je naam, je studentennummer en het vervolgnummer per pagina. Als je voor
Schriftelijk tentamen Spraakherkenning en spraaksynthese (do. 23 december 2004, 13.30 16.30 u; zaal C.206) Vermeld op iedere pagina je naam, je studentennummer en het vervolgnummer per pagina. Als je voor
HANDLEIDING EUROGLOT TRANSLATOR MODULE
 Linguistic Systems BV - Euroglot 2013 Leo Konst Handleiding voor het gebruik van de Euroglot Translator vertaalmodule. Euroglot Translator is een nieuw product in de Euroglot reeks, dat de Euroglot Professional
Linguistic Systems BV - Euroglot 2013 Leo Konst Handleiding voor het gebruik van de Euroglot Translator vertaalmodule. Euroglot Translator is een nieuw product in de Euroglot reeks, dat de Euroglot Professional
HANDLEIDING EUROGLOT TRANSLATOR MODULE
 Linguistic Systems BV - Euroglot 2017 Leo Konst HANDLEIDING MODULE Handleiding voor het gebruik van de Euroglot Translator vertaalmodule. Euroglot Translator is een nieuw product in de Euroglot reeks,
Linguistic Systems BV - Euroglot 2017 Leo Konst HANDLEIDING MODULE Handleiding voor het gebruik van de Euroglot Translator vertaalmodule. Euroglot Translator is een nieuw product in de Euroglot reeks,
Automatisch Vertalen SMT
 Automatisch Vertalen SMT Véronique Hoste (met dank aan Lieve Macken) Hoe leert een computer vertalen? Woordverwerving in SMT 鱼 汤 糖 醋 老 鸭 yú tāng táng cù lǎo yā Co-occurrence frequency 鸡 汤 jī tāng
Automatisch Vertalen SMT Véronique Hoste (met dank aan Lieve Macken) Hoe leert een computer vertalen? Woordverwerving in SMT 鱼 汤 糖 醋 老 鸭 yú tāng táng cù lǎo yā Co-occurrence frequency 鸡 汤 jī tāng
1e Deeltentamen Inleiding Taalkunde
 1e Deeltentamen Inleiding Taalkunde 28/05/2009 13.15-16.15 Dit tentamen heeft 5 vragen. Je hebt drie uur de tijd om deze te beantwoorden. Vergeet niet je naam en studentnummer steeds duidelijk te vermelden.
1e Deeltentamen Inleiding Taalkunde 28/05/2009 13.15-16.15 Dit tentamen heeft 5 vragen. Je hebt drie uur de tijd om deze te beantwoorden. Vergeet niet je naam en studentnummer steeds duidelijk te vermelden.
Logische Complexiteit Hoorcollege 4
 Logische Complexiteit Hoorcollege 4 Jacob Vosmaer Bachelor CKI, Universiteit Utrecht 8 februari 2011 Contextvrije grammatica s Inleiding + voorbeeld Definities Meer voorbeelden Ambiguiteit Chomsky-normaalvormen
Logische Complexiteit Hoorcollege 4 Jacob Vosmaer Bachelor CKI, Universiteit Utrecht 8 februari 2011 Contextvrije grammatica s Inleiding + voorbeeld Definities Meer voorbeelden Ambiguiteit Chomsky-normaalvormen
LTX016B05. Nieuwe ontwikkelingen in de syntaxis. College 2
 LTX016B05 Nieuwe ontwikkelingen in de syntaxis College 2 2/104 Vandaag: 3/104 Vandaag:! Algemene aspecten van de generatieve syntaxistheorie 4/104 Vandaag:! Algemene aspecten van de generatieve syntaxistheorie
LTX016B05 Nieuwe ontwikkelingen in de syntaxis College 2 2/104 Vandaag: 3/104 Vandaag:! Algemene aspecten van de generatieve syntaxistheorie 4/104 Vandaag:! Algemene aspecten van de generatieve syntaxistheorie
Achtergrond Spraakherkenning De uitdaging van spraakherkenning
 Achtergrond Spraakherkenning is het herkennen van menselijke spraak door een computer. Al tweehonderd jaar lang proberen wetenschappers een computer spraak naar tekst te laten omzetten. De technieken voor
Achtergrond Spraakherkenning is het herkennen van menselijke spraak door een computer. Al tweehonderd jaar lang proberen wetenschappers een computer spraak naar tekst te laten omzetten. De technieken voor
Klanken 1. Tekst en spraak. Colleges en hoofdstukken. Dit college
 Tekst en spraak Klanken 1 Representatie van spraak vereist representaties van gedeeltes die kleiner dan woorden zijn. spraaksynthese (tekst-naar-spraak) rijtje letters! akoestische golfvorm http://www.fluency.nl/
Tekst en spraak Klanken 1 Representatie van spraak vereist representaties van gedeeltes die kleiner dan woorden zijn. spraaksynthese (tekst-naar-spraak) rijtje letters! akoestische golfvorm http://www.fluency.nl/
Bel dan James, onze huiscomputer! Toekomst of realiteit?
 Bel dan James, onze huiscomputer! Toekomst of realiteit? Inleiding Het is plotseling gaan sneeuwen en Monique staat in een lange file. Ze kijkt zenuwachtig op de klok. Opeens roept zij bel naar huis, en
Bel dan James, onze huiscomputer! Toekomst of realiteit? Inleiding Het is plotseling gaan sneeuwen en Monique staat in een lange file. Ze kijkt zenuwachtig op de klok. Opeens roept zij bel naar huis, en
LUISTERVAARDIGHEID EN
 LUISTERVAARDIGHEID EN SCHRIJFVAARDIGHEID IN DE ISK Goede zinnen schrijven vind ik best moeilijk. Lies Alons Bijeenkomst 8-15 november 2016 DOELEN VANDAAG 1. Je kijkt nog een keer naar luistervaardigheid
LUISTERVAARDIGHEID EN SCHRIJFVAARDIGHEID IN DE ISK Goede zinnen schrijven vind ik best moeilijk. Lies Alons Bijeenkomst 8-15 november 2016 DOELEN VANDAAG 1. Je kijkt nog een keer naar luistervaardigheid
Dutch Parallel Corpus Multilinguaal & multifunctioneel. Lieve Macken LT 3 Hogeschool Gent
 Dutch Parallel Corpus Multilinguaal & multifunctioneel Lieve Macken LT 3 Hogeschool Gent Dutch Parallel Corpus Parallel corpus Teksten + vertaling Gealigneerd op zinsniveau 10 miljoen woorden Nederlands
Dutch Parallel Corpus Multilinguaal & multifunctioneel Lieve Macken LT 3 Hogeschool Gent Dutch Parallel Corpus Parallel corpus Teksten + vertaling Gealigneerd op zinsniveau 10 miljoen woorden Nederlands
[Dossier] Taal- en spraaktechnologie in Vlaanderen: dood of levend? Els Lefever en Lieve Macken. <foto s auteurs: zie gelijknamig bestand>
![[Dossier] Taal- en spraaktechnologie in Vlaanderen: dood of levend? Els Lefever en Lieve Macken. <foto s auteurs: zie gelijknamig bestand>](/thumbs/25/6021206.jpg "[Dossier] Taal- en spraaktechnologie in Vlaanderen: dood of levend? Els Lefever en Lieve Macken. <foto s auteurs: zie gelijknamig bestand>") [Dossier] Taal- en spraaktechnologie in Vlaanderen: dood of levend? Els Lefever en Lieve Macken Zo n kleine tien jaar geleden spatte de financiële luchtbel rond
[Dossier] Taal- en spraaktechnologie in Vlaanderen: dood of levend? Els Lefever en Lieve Macken Zo n kleine tien jaar geleden spatte de financiële luchtbel rond
Technische publicatie van SmalS-MvM 04/2005
 29 Technische publicatie van SmalS-MvM 04/2005 Spraakherkenning Systemen voor continu dicteren Taal geeft kleur aan onze ideeën... (de Graaf van Rivarol) 1 1. Inleiding De automatische verwerking van talen
29 Technische publicatie van SmalS-MvM 04/2005 Spraakherkenning Systemen voor continu dicteren Taal geeft kleur aan onze ideeën... (de Graaf van Rivarol) 1 1. Inleiding De automatische verwerking van talen
Voorbeeld casus mondeling college-examen
 Voorbeeld casus mondeling college-examen Examenvak en niveau informatica vwo Naam kandidaat Examennummer Examencommissie Datum Voorbereidingstijd Titel voorbereidingsopdracht 20 minuten van analoog naar
Voorbeeld casus mondeling college-examen Examenvak en niveau informatica vwo Naam kandidaat Examennummer Examencommissie Datum Voorbereidingstijd Titel voorbereidingsopdracht 20 minuten van analoog naar
Dyslexie & meertaligheid. Danielle van der Werf Onderwijsadviseur & GZ-psycholoog
 Dyslexie & meertaligheid Danielle van der Werf Onderwijsadviseur & GZ-psycholoog Doel Herkennen van signalen van dyslexie bij kinderen met Nederlands als tweede taal. Het kunnen onderzoeken of leerproblemen
Dyslexie & meertaligheid Danielle van der Werf Onderwijsadviseur & GZ-psycholoog Doel Herkennen van signalen van dyslexie bij kinderen met Nederlands als tweede taal. Het kunnen onderzoeken of leerproblemen
Cover Page. The handle holds various files of this Leiden University dissertation.
 Cover Page The handle http://hdl.handle.net/1887/20984 holds various files of this Leiden University dissertation. Author: Hosono, Mayumi Title: Object shift in the Scandinavian languages : syntax, information
Cover Page The handle http://hdl.handle.net/1887/20984 holds various files of this Leiden University dissertation. Author: Hosono, Mayumi Title: Object shift in the Scandinavian languages : syntax, information
Dutch Parallel Corpus Multilinguaal & multifunctioneel. Lieve Macken Hogeschool Gent
 Dutch Parallel Corpus Multilinguaal & multifunctioneel Lieve Macken Hogeschool Gent Dutch Parallel Corpus Parallel corpus Teksten + vertaling Gealigneerd op zinsniveau 10 miljoen woorden Nederlands Engels
Dutch Parallel Corpus Multilinguaal & multifunctioneel Lieve Macken Hogeschool Gent Dutch Parallel Corpus Parallel corpus Teksten + vertaling Gealigneerd op zinsniveau 10 miljoen woorden Nederlands Engels
BEHANDELINGSADVIEZEN BIJ LAGERE SCHOOL KINDEREN L U T S C H E L P E OPBOUW
 BEHANDELINGSADVIEZEN BIJ LAGERE SCHOOL KINDEREN L U T S C H E L P E OPBOUW Belang van het bekijken van de taalontwikkeling bij de aanvang van therapie De therapie zelf Beroep doen op het metalinguïstisch
BEHANDELINGSADVIEZEN BIJ LAGERE SCHOOL KINDEREN L U T S C H E L P E OPBOUW Belang van het bekijken van de taalontwikkeling bij de aanvang van therapie De therapie zelf Beroep doen op het metalinguïstisch
Master in de taalkunde. Masterinfoavond Le/eren 26 april 2016
 Master in de taalkunde Masterinfoavond Le/eren 26 april 2016 MA taalkunde - Overzicht Doelstelling Structuur & programma Meesterproef Toelatingsvoorwaarden Uit- en doorstroommogelijkheden Meer info 2 MA
Master in de taalkunde Masterinfoavond Le/eren 26 april 2016 MA taalkunde - Overzicht Doelstelling Structuur & programma Meesterproef Toelatingsvoorwaarden Uit- en doorstroommogelijkheden Meer info 2 MA
SPRAAKTECHNOLOGIE: INLEIDING
 SAMENVATTING HOORCOLLEGE 12/12/2002 SPRAAKPRODUCTIE EN -PERCEPTIE Docent: Bart de Boer Taakgroep 3: Daniel Kucharski, e-mail Daniel.Kucharski@vub.ac.be Jeroen Schaeken, e-mail Jeroen.Schaeken@vub.ac.be
SAMENVATTING HOORCOLLEGE 12/12/2002 SPRAAKPRODUCTIE EN -PERCEPTIE Docent: Bart de Boer Taakgroep 3: Daniel Kucharski, e-mail Daniel.Kucharski@vub.ac.be Jeroen Schaeken, e-mail Jeroen.Schaeken@vub.ac.be
Woordenboekencomponent van de Geïntegreerde Taalbank (GTB): het WNT en VMNW met andere databestanden geïntegreerd in 1 zoeksysteem demo gtb.inl.
: het WNT en VMNW met andere databestanden geïntegreerd in 1 zoeksysteem demo gtb.inl.") Woordenboekencomponent van de Geïntegreerde Taalbank (GTB): het WNT en VMNW met andere databestanden geïntegreerd in 1 zoeksysteem demo gtb.inl.nl: basiszoeken en uitgebreid zoeken links vanuit een artikel
Woordenboekencomponent van de Geïntegreerde Taalbank (GTB): het WNT en VMNW met andere databestanden geïntegreerd in 1 zoeksysteem demo gtb.inl.nl: basiszoeken en uitgebreid zoeken links vanuit een artikel
Door: Dàzz Hityahubessy (3/4/6) Edyta Gil (deel 1/2/5/) Technologie verslag Spraakherkenning
 Edyta Gil (deel 1/2/5/) Technologie verslag Spraakherkenning") Technologie verslag Spraakherkenning 1. Geschiedenis Spraakherkenning heeft een langere geschiedenis dan we wellicht denken. Als mens zijnde hebben we sinds eeuwenlang de behoefte gehad om moeilijke taken
Technologie verslag Spraakherkenning 1. Geschiedenis Spraakherkenning heeft een langere geschiedenis dan we wellicht denken. Als mens zijnde hebben we sinds eeuwenlang de behoefte gehad om moeilijke taken
Choral + Spraaktechnologie: ingezet voor de ontsluiting van audiovisuele
 Choral + Spraaktechnologie: ingezet voor de ontsluiting van audiovisuele archieven De benadering Doel van het NWO CATCH project CHoral (2006-2011): onderzoek en ontwikkel geautomatiseerde annotatieen zoek
Choral + Spraaktechnologie: ingezet voor de ontsluiting van audiovisuele archieven De benadering Doel van het NWO CATCH project CHoral (2006-2011): onderzoek en ontwikkel geautomatiseerde annotatieen zoek
Collectie POR: Portugese taal- en letterkunde
 Inhoud Collectie 2 Plaatsingssysteem 3 Hoofdindeling 4 Taal- en letterkunde 5 Taalkunde 6 Letterkunde 10 Handboeken en naslagwerken 14 p. 1 / 14 Collectie De collectie omvat ca. 10.000 banden en bestrijkt
Inhoud Collectie 2 Plaatsingssysteem 3 Hoofdindeling 4 Taal- en letterkunde 5 Taalkunde 6 Letterkunde 10 Handboeken en naslagwerken 14 p. 1 / 14 Collectie De collectie omvat ca. 10.000 banden en bestrijkt
Geest, brein en cognitie
 Geest, brein en cognitie Filosofie van de geest en Grondslagen van de cognitiewetenschap Fred Keijzer 1 Overzicht: Wat is filosofie en waarom is dit relevant voor cognitiewetenschap en kunstmatige intelligentie?
Geest, brein en cognitie Filosofie van de geest en Grondslagen van de cognitiewetenschap Fred Keijzer 1 Overzicht: Wat is filosofie en waarom is dit relevant voor cognitiewetenschap en kunstmatige intelligentie?
Programma van Inhoud en Toetsing (PIT)
") 2016-2017 Vak: Nederlands Klas: vmbo-tl 2 Onderdeel: Spelling 1 & 2 Digitale methode 1F Spelling: verdubbeling en verenkeling. 1F Spelling: vorming van het bijvoeglijk naamwoord. 1F Werkwoordspelling waarvan
2016-2017 Vak: Nederlands Klas: vmbo-tl 2 Onderdeel: Spelling 1 & 2 Digitale methode 1F Spelling: verdubbeling en verenkeling. 1F Spelling: vorming van het bijvoeglijk naamwoord. 1F Werkwoordspelling waarvan
Voorbeeld casus mondeling college-examen
 Voorbeeld casus mondeling college-examen Examenvak en niveau informatica havo Naam kandidaat Examennummer Examencommissie Datum Voorbereidingstijd Titel voorbereidingsopdracht 20 minuten van analoog naar
Voorbeeld casus mondeling college-examen Examenvak en niveau informatica havo Naam kandidaat Examennummer Examencommissie Datum Voorbereidingstijd Titel voorbereidingsopdracht 20 minuten van analoog naar
Oriëntatie Kunstmatige Intelligentie. Taalverwerving
 Oriëntatie Kunstmatige Intelligentie Taalverwerving Taalverwervingsparadox Het leren van een taal: Makkelijk voor kinderen Maar moeilijk voor volwassenen en computers Hoe leren kinderen hun moedertaal?
Oriëntatie Kunstmatige Intelligentie Taalverwerving Taalverwervingsparadox Het leren van een taal: Makkelijk voor kinderen Maar moeilijk voor volwassenen en computers Hoe leren kinderen hun moedertaal?
Collectie KLA: Griekse en Latijnse taal- en letterkunde
 Inhoud Collectie 2 Plaatsingssysteem 3 Hoofdindeling 4 Taal- en letterkunde 5 Taalkunde 5 Letterkunde 8 Handboeken en naslagwerken 11 p. 1 / 11 Collectie De collectie KLA bevat Griekse en Latijnse taal-
Inhoud Collectie 2 Plaatsingssysteem 3 Hoofdindeling 4 Taal- en letterkunde 5 Taalkunde 5 Letterkunde 8 Handboeken en naslagwerken 11 p. 1 / 11 Collectie De collectie KLA bevat Griekse en Latijnse taal-
Natuurlijke-taalverwerking. Week 2
 Natuurlijke-taalverwerking Week 2 Overzicht Context-vrije Grammatica s CFGs in Prolog Definite Clause Grammars (DCGs) Construeren van bomen Recapitulatie Doel: computers taal laten begrijpen Noodzaak:
Natuurlijke-taalverwerking Week 2 Overzicht Context-vrije Grammatica s CFGs in Prolog Definite Clause Grammars (DCGs) Construeren van bomen Recapitulatie Doel: computers taal laten begrijpen Noodzaak:
Automaten & Complexiteit (X )
") Automaten & Complexiteit (X 401049) Inleiding Jeroen Keiren j.j.a.keiren@vu.nl VU University Amsterdam Materiaal Peter Linz An Introduction to Formal Languages and Automata (5th edition) Jones and Bartlett
Automaten & Complexiteit (X 401049) Inleiding Jeroen Keiren j.j.a.keiren@vu.nl VU University Amsterdam Materiaal Peter Linz An Introduction to Formal Languages and Automata (5th edition) Jones and Bartlett
PLANETS - Testbed. duizend jaar geschiedenis ligt op honderd kilometer plank van het de geschiedenis dijt uit, jaarlijks met kilometers
 duizend jaar geschiedenis ligt op honderd kilometer plank van het de geschiedenis dijt uit, jaarlijks met kilometers PLANETS - Testbed Petra Helwig Senior adviseur Digitale Duurzaamheid Stel je voor Je
duizend jaar geschiedenis ligt op honderd kilometer plank van het de geschiedenis dijt uit, jaarlijks met kilometers PLANETS - Testbed Petra Helwig Senior adviseur Digitale Duurzaamheid Stel je voor Je
Compilers (2IC25) docent: G. Zwaan, HG 5.41, tel. ( )4291, webpagina:
 docent: G. Zwaan, HG 5.41, tel. ( )4291, webpagina:") Compilers (2IC25) docent: G. Zwaan, HG 5.41, tel. (040 247)4291, e-mail: G.Zwaan@tue.nl webpagina: http://www.win.tue.nl/~wsinswan/compilers/ compileren compilatie vertalen (een werk) bijeenbrengen door
Compilers (2IC25) docent: G. Zwaan, HG 5.41, tel. (040 247)4291, e-mail: G.Zwaan@tue.nl webpagina: http://www.win.tue.nl/~wsinswan/compilers/ compileren compilatie vertalen (een werk) bijeenbrengen door
Oriëntatie Kunstmatige Intelligentie. Inleidend College Niels Taatgen
 Oriëntatie Kunstmatige Intelligentie Inleidend College Niels Taatgen Inhoud vandaag! Wat is kunstmatige intelligentie?! Vakgebieden die bijdragen aan de AI! Kunnen computers denken?! Hoe denken mensen
Oriëntatie Kunstmatige Intelligentie Inleidend College Niels Taatgen Inhoud vandaag! Wat is kunstmatige intelligentie?! Vakgebieden die bijdragen aan de AI! Kunnen computers denken?! Hoe denken mensen
Taal- en Informatietechnologie. Taal- en Informatietechnologie. Informatie en tekst. Over de cursus. Over de cursus: opbouw. Over de cursus (2)
") Taal- en Informatietechnologie Emiel Krahmer & Antal van den Bosch {E.J.Krahmer,antalb}@uvt.nl eerste semester 2003-2004 Taal- en Informatietechnologie Informatietechnologie: informatie halen uit tekst
Taal- en Informatietechnologie Emiel Krahmer & Antal van den Bosch {E.J.Krahmer,antalb}@uvt.nl eerste semester 2003-2004 Taal- en Informatietechnologie Informatietechnologie: informatie halen uit tekst
Spreken en Verstaan: Inleiding Fonetiek
 2011-2012, blok 2 Spreken en Verstaan: Inleiding Fonetiek werkcollege 10: functies van prosodie prosodie C est le ton qui fait la musique. It s not what you say, it s how you say it. prosodie resulteert
2011-2012, blok 2 Spreken en Verstaan: Inleiding Fonetiek werkcollege 10: functies van prosodie prosodie C est le ton qui fait la musique. It s not what you say, it s how you say it. prosodie resulteert
Introductie tot de cursus
 Inhoud introductietalen en ontleders Introductie tot de cursus 1 Plaats en functie van de cursus 7 2 Inhoud van de cursus 7 2.1 Voorkennis 7 2.2 Leerdoelen 8 2.3 Opbouw van de cursus 8 3 Leermiddelen en
Inhoud introductietalen en ontleders Introductie tot de cursus 1 Plaats en functie van de cursus 7 2 Inhoud van de cursus 7 2.1 Voorkennis 7 2.2 Leerdoelen 8 2.3 Opbouw van de cursus 8 3 Leermiddelen en
En de beste gratis online vertaalmachine is
 En de beste gratis online vertaalmachine is Ja, de gratis vertaalmachine van Google is de bekendste. Maar is het ook de beste? En als je de kwaliteit niet vertrouwt, kun je daar dan als leek zelf iets
En de beste gratis online vertaalmachine is Ja, de gratis vertaalmachine van Google is de bekendste. Maar is het ook de beste? En als je de kwaliteit niet vertrouwt, kun je daar dan als leek zelf iets
Vervolg op het STEVIN Programma
 Vervolg op het STEVIN Programma Onderzoek en Ontwikkeling Internationaal Europa Focus op Multilingual en Cross-lingual Information Processing Meer development dan Research Kan verschuiven in de komende
Vervolg op het STEVIN Programma Onderzoek en Ontwikkeling Internationaal Europa Focus op Multilingual en Cross-lingual Information Processing Meer development dan Research Kan verschuiven in de komende
Kennisbasis Duits 8 juli 2009. 2. Taalkundige kennis
 Kennisbasis Duits 8 juli 2009 Thema Categorie/kernconcept Omschrijving van de categorie / het kernconcept De student 1. Taalvaardigheden 1.1 De vaardigheden 1.1.1 beheerst de kijkvaardigheid en de luistervaardigheid
Kennisbasis Duits 8 juli 2009 Thema Categorie/kernconcept Omschrijving van de categorie / het kernconcept De student 1. Taalvaardigheden 1.1 De vaardigheden 1.1.1 beheerst de kijkvaardigheid en de luistervaardigheid
Het computationeel denken van een informaticus Maarten van Steen Center for Telematics and Information Technology (CTIT)
") Het computationeel denken van een informaticus Maarten van Steen Center for Telematics and Information Technology (CTIT) 2-2-2015 1 Computationeel denken vanuit Informatica Jeannette Wing President s Professor
Het computationeel denken van een informaticus Maarten van Steen Center for Telematics and Information Technology (CTIT) 2-2-2015 1 Computationeel denken vanuit Informatica Jeannette Wing President s Professor
 Samenvatting De hoofdonderzoeksvraag van dit proefschrift is vast te stellen hoe term- en relatie-extractietechnieken kunnen bijdragen tot het beantwoorden van medische vragen. Deze vraag is ingegeven
Samenvatting De hoofdonderzoeksvraag van dit proefschrift is vast te stellen hoe term- en relatie-extractietechnieken kunnen bijdragen tot het beantwoorden van medische vragen. Deze vraag is ingegeven
AI Kaleidoscoop. College 9: Natuurlijke taal. Natuurlijke taal: het probleem. Fases in de analyse van natuurlijke taal.
 AI Kaleidoscoop College 9: atuurlijke taal Het Probleem Grammatica s Transitie netwerken Leeswijzer: Hoofdstuk 14.0-14.3 AI9 1 atuurlijke taal: het probleem Communiceren met computers als met mensen, middels
AI Kaleidoscoop College 9: atuurlijke taal Het Probleem Grammatica s Transitie netwerken Leeswijzer: Hoofdstuk 14.0-14.3 AI9 1 atuurlijke taal: het probleem Communiceren met computers als met mensen, middels
Een hele eenvoudige benadering van de oplossing van dit probleem die men wel voorgesteld heeft, is de volgende regel:
 Accent op voorzetsels en partikels Het tweede probleem dat ik wil gebruiken ter illustratie is een probleem dat meer van belang is voor de spraaktechnologie. Een van de technologieën die spraaktechnologen
Accent op voorzetsels en partikels Het tweede probleem dat ik wil gebruiken ter illustratie is een probleem dat meer van belang is voor de spraaktechnologie. Een van de technologieën die spraaktechnologen
Autonomata, Too. Henk van den Heuvel. CLST, Radboud Universiteit Nijmegen
 Autonomata, Too Henk van den Heuvel CLST, Radboud Universiteit Nijmegen Het project Opvolger van Autonomata (2005-2007) Gesubsidieerd in de 3e open call van STEVIN Toepassingsgerichtproject Start: 1 februari
Autonomata, Too Henk van den Heuvel CLST, Radboud Universiteit Nijmegen Het project Opvolger van Autonomata (2005-2007) Gesubsidieerd in de 3e open call van STEVIN Toepassingsgerichtproject Start: 1 februari
Automaten en Berekenbaarheid 2016 Oplossingen #4
 Automaten en Berekenbaarheid 2016 Oplossingen #4 28 oktober 2016 Vraag 1: Toon aan dat de klasse van context vrije talen gesloten is onder concatenatie en ster. Antwoord Meerdere manieren zijn mogelijk:
Automaten en Berekenbaarheid 2016 Oplossingen #4 28 oktober 2016 Vraag 1: Toon aan dat de klasse van context vrije talen gesloten is onder concatenatie en ster. Antwoord Meerdere manieren zijn mogelijk:
Parse and Corpus-based Machine Translation. STEVIN Programmadag 2010 1
 PaCo-MT Parse and Corpus-based Machine Translation STEVIN Programmadag 2010 1 Project: PaCo-MT 2008-2011 Gesponsord door NL EN NL FR Consortium partners CCL KULeuven Alfa-Informatics RUGroningen OneLiner
PaCo-MT Parse and Corpus-based Machine Translation STEVIN Programmadag 2010 1 Project: PaCo-MT 2008-2011 Gesponsord door NL EN NL FR Consortium partners CCL KULeuven Alfa-Informatics RUGroningen OneLiner
Syllabus Natuurlijke-Taalverwerking I. Gosse Bouma Afdeling Informatiekunde Rijksuniversiteit Groningen
 Syllabus Natuurlijke-Taalverwerking I Gosse Bouma Afdeling Informatiekunde Rijksuniversiteit Groningen gosse@let.rug.nl Februari, 2006 Inhoudsopgave 1 Inleiding 4 1.1 Taal en computer.................................
Syllabus Natuurlijke-Taalverwerking I Gosse Bouma Afdeling Informatiekunde Rijksuniversiteit Groningen gosse@let.rug.nl Februari, 2006 Inhoudsopgave 1 Inleiding 4 1.1 Taal en computer.................................
Herkennen van symbolenreeksen binnen een oneindige reeks met Hidden Markov Modellen. Werner ( ), Maaike ( ) begeleider Bart de Boer
, Maaike ( ) begeleider Bart de Boer") Herkennen van symbolenreeksen binnen een oneindige reeks met Hidden Markov Modellen Werner (1101021), Maaike (1211307) begeleider Bart de Boer 3 september 2005 Inhoudsopgave 1 Introductie 2 2 Onderzoeksopzet
Herkennen van symbolenreeksen binnen een oneindige reeks met Hidden Markov Modellen Werner (1101021), Maaike (1211307) begeleider Bart de Boer 3 september 2005 Inhoudsopgave 1 Introductie 2 2 Onderzoeksopzet
TENTAMEN Basismodellen in de Informatica VOORBEELDUITWERKING
 TENTAMEN Basismodellen in de Informatica vakcode: 211180 datum: 2 juli 2009 tijd: 9:00 12:30 uur VOORBEELDUITWERKING Algemeen Bij dit tentamen mag gebruik worden gemaakt van het boek van Sudkamp, van de
TENTAMEN Basismodellen in de Informatica vakcode: 211180 datum: 2 juli 2009 tijd: 9:00 12:30 uur VOORBEELDUITWERKING Algemeen Bij dit tentamen mag gebruik worden gemaakt van het boek van Sudkamp, van de
THERAPIEPLAN Logopedie
 NAAM: Geboortedatum:. Klas:.. THERAPIEPLAN Logopedie Bron: GWP Taal School Ter Elst Therapiedoelen Articulatie Domein Doel nr. Opmerkingen - Mondmotoriek - Correct uitspreken van de klinkers - Correct
NAAM: Geboortedatum:. Klas:.. THERAPIEPLAN Logopedie Bron: GWP Taal School Ter Elst Therapiedoelen Articulatie Domein Doel nr. Opmerkingen - Mondmotoriek - Correct uitspreken van de klinkers - Correct
Technologieverkenning Nederlandstalige Taalen Spraaktechnologie
 Technologieverkenning Nederlandstalige Taalen Spraaktechnologie Rapport bij project 103185, versie 1.1 Dit rapport is geschreven in opdracht van het ministerie van Economische Zaken door Jaap Akkermans,
Technologieverkenning Nederlandstalige Taalen Spraaktechnologie Rapport bij project 103185, versie 1.1 Dit rapport is geschreven in opdracht van het ministerie van Economische Zaken door Jaap Akkermans,
Analyse van veiligheidscommunicatie bij de Belgische spoorwegen met behulp van automatische spraakherkenning
 Analyse van veiligheidscommunicatie bij de Belgische spoorwegen met behulp van automatische spraakherkenning Inge Gielis Thesis voorgedragen tot het behalen van de graad van Master of Science in de ingenieurswetenschappen:
Analyse van veiligheidscommunicatie bij de Belgische spoorwegen met behulp van automatische spraakherkenning Inge Gielis Thesis voorgedragen tot het behalen van de graad van Master of Science in de ingenieurswetenschappen:
Van welk station naar welk station wilt u reizen? REISINFORMATIE VIA EEN GESPROKEN-DIALOOGSYSTEEM
 nederlands akoestisch genootschap NAG journaal nr. 134 nov. 1996 Van welk station naar welk station wilt u reizen? REISINFORMATIE VIA EEN GESPROKEN-DIALOOGSYSTEEM dr. Helmer Strik Vakgroep Taal & Spraak
nederlands akoestisch genootschap NAG journaal nr. 134 nov. 1996 Van welk station naar welk station wilt u reizen? REISINFORMATIE VIA EEN GESPROKEN-DIALOOGSYSTEEM dr. Helmer Strik Vakgroep Taal & Spraak
Computercommunicatie B: Informatiesystemen
 Computercommunicatie B: Informatiesystemen Markus Egg Rijksuniversiteit Groningen Voorjaar 2007 Introductie: doelen van de cursus definitie van informatiesystemen voorbeelden van informatiesystemen klassieke
Computercommunicatie B: Informatiesystemen Markus Egg Rijksuniversiteit Groningen Voorjaar 2007 Introductie: doelen van de cursus definitie van informatiesystemen voorbeelden van informatiesystemen klassieke
Vorig college. IN2505-II Berekenbaarheidstheorie College 4. Opsommers versus herkenners (Th. 3.21) Opsommers
 Opsommers") Vorig college College 4 Algoritmiekgroep Faculteit EWI TU Delft Vervolg NDTM s Vergelijking rekenkracht TM s en NDTM s Voorbeelden NDTM s 20 april 2009 1 2 Opsommers Opsommers versus herkenners (Th. 3.21)
Vorig college College 4 Algoritmiekgroep Faculteit EWI TU Delft Vervolg NDTM s Vergelijking rekenkracht TM s en NDTM s Voorbeelden NDTM s 20 april 2009 1 2 Opsommers Opsommers versus herkenners (Th. 3.21)
Invloed van taalvaardigheid op spraakverstaan in rumoer
 Invloed van taalvaardigheid op spraakverstaan in rumoer E. Huysmans (VUmc, Amsterdam) N. Stolk (UvA Taalwetenschap, Amsterdam) S.T. Goverts (VUmc, Amsterdam) Visuele variant van de SRT: Text Reception
Invloed van taalvaardigheid op spraakverstaan in rumoer E. Huysmans (VUmc, Amsterdam) N. Stolk (UvA Taalwetenschap, Amsterdam) S.T. Goverts (VUmc, Amsterdam) Visuele variant van de SRT: Text Reception
Zoeken in een Afrikaans corpus: baie maklik! Liesbeth Augustinus Ineke Schuurman Vincent Vandeghinste Peter Dirix Frank Van Eynde
 Zoeken in een Afrikaans corpus: baie maklik! Liesbeth Augustinus Ineke Schuurman Vincent Vandeghinste Peter Dirix Frank Van Eynde Colloquium Afrikaans - 23 oktober 2015 AFRIBOOMS PROJECT Syntactisch geannoteerd
Zoeken in een Afrikaans corpus: baie maklik! Liesbeth Augustinus Ineke Schuurman Vincent Vandeghinste Peter Dirix Frank Van Eynde Colloquium Afrikaans - 23 oktober 2015 AFRIBOOMS PROJECT Syntactisch geannoteerd
David Weenink. Instituut voor Fonetische Wetenschapen ACLC Universiteit van Amsterdam. Spraakverwerking per computer.
 Instituut voor Fonetische Wetenschapen ACLC Universiteit van Amsterdam AMSTERDAM CENTER FOR LANGUAGE AND C O M M U N I C A T I O N 5000 4000 3000 Hz 2000 1000 0 de vrouw loopt met haar dure schoenen 0.3
Instituut voor Fonetische Wetenschapen ACLC Universiteit van Amsterdam AMSTERDAM CENTER FOR LANGUAGE AND C O M M U N I C A T I O N 5000 4000 3000 Hz 2000 1000 0 de vrouw loopt met haar dure schoenen 0.3
Bachelorproef. Het gebruik van spraaktechnologie bij medical management assistants (MMA's) in West-Vlaanderen. Ellen De Backer
 in West-Vlaanderen. Ellen De Backer") Bachelorproef Studiegebied Handelswetenschappen en bedrijfskunde Bachelor Office management Afstudeerrichting Medical management assistant Academiejaar 2012-2013 Studente Ellen De Backer Het gebruik van
Bachelorproef Studiegebied Handelswetenschappen en bedrijfskunde Bachelor Office management Afstudeerrichting Medical management assistant Academiejaar 2012-2013 Studente Ellen De Backer Het gebruik van
# 4 De leerling leert strategieën te gebruiken bij het verwerven van informatie uit gesproken en geschreven teksten.
 A. LEER- EN TOETSPLAN Onderwerp: Grammatica De leerlingen kunnen onderscheiden. De leerlingen kennen elementen van het verbuiging- en vervoegingsysteem. De leerlingen kunnen m.b.v. de betekenis van een
A. LEER- EN TOETSPLAN Onderwerp: Grammatica De leerlingen kunnen onderscheiden. De leerlingen kennen elementen van het verbuiging- en vervoegingsysteem. De leerlingen kunnen m.b.v. de betekenis van een
Why speech? Spraak. Remote history. Speech not NLP. History after computers. Desire to speak with machines and animals is very old.
 Why speech? Spraak Bart de Boer Desire to speak with machines and animals is very old Speech is intuitive Speech is fast Speech defines man, social groups and individuals Speech can make machines more
Why speech? Spraak Bart de Boer Desire to speak with machines and animals is very old Speech is intuitive Speech is fast Speech defines man, social groups and individuals Speech can make machines more
Wiskunde en taal. Contents First Last Prev Next
 Wiskunde en taal Bèta Themadag 2002 1. Intro Jullie kennen vast de Internet Movie Database, waar je alles in kan opzoeken wat je over films, acteurs, regisseurs... zou willen weten. De interface werkt
Wiskunde en taal Bèta Themadag 2002 1. Intro Jullie kennen vast de Internet Movie Database, waar je alles in kan opzoeken wat je over films, acteurs, regisseurs... zou willen weten. De interface werkt
Cover Page. The handle http://hdl.handle.net/1887/20358 holds various files of this Leiden University dissertation.
 Cover Page The handle http://hdl.handle.net/1887/20358 holds various files of this Leiden University dissertation. Author: Witsenburg, Tijn Title: Hybrid similarities : a method to insert relational information
Cover Page The handle http://hdl.handle.net/1887/20358 holds various files of this Leiden University dissertation. Author: Witsenburg, Tijn Title: Hybrid similarities : a method to insert relational information
Samenvatting SAMENVATTING
 SAMENVATTING Introductie Dit proefschrift geeft het theoretische en experimentele werk weer rondom de auditieve en cognitieve mechanismen van het top-down herstel van gedegradeerde spraak. In het dagelijks
SAMENVATTING Introductie Dit proefschrift geeft het theoretische en experimentele werk weer rondom de auditieve en cognitieve mechanismen van het top-down herstel van gedegradeerde spraak. In het dagelijks
Spraakherkenning in dialoogsystemen
 Spraakherkenning in dialoogsystemen Praten met een computer Dipl.-Ing. Franz-Peter Zantis In de nabije toekomst zullen we met computers kunnen praten. In dit artikel zullen basisbegrippen van spraakherkenning
Spraakherkenning in dialoogsystemen Praten met een computer Dipl.-Ing. Franz-Peter Zantis In de nabije toekomst zullen we met computers kunnen praten. In dit artikel zullen basisbegrippen van spraakherkenning
Complexiteit. Rick Nouwen. Inleiding Taalkunde
 Complexiteit Rick Nouwen Inleiding Taalkunde Vandaag: Complexiteit Hoofdstuk 12, sectie 12.6: voorproefje op hoofdstuk 16 Hoofdstuk 14, sectie 14.10: complexiteit van parsing (achtergrondmateriaal, hier
Complexiteit Rick Nouwen Inleiding Taalkunde Vandaag: Complexiteit Hoofdstuk 12, sectie 12.6: voorproefje op hoofdstuk 16 Hoofdstuk 14, sectie 14.10: complexiteit van parsing (achtergrondmateriaal, hier
Opdrachten Werkcollege 4
 1. Vertaling in predicatenlogica Opdrachten Werkcollege 4 Vertaal de volgende zinnen naar de eerste orde predicatenlogica: Jan of Piet studeert wiskunde Moskou is een stad in Rusland Geen student die 5
1. Vertaling in predicatenlogica Opdrachten Werkcollege 4 Vertaal de volgende zinnen naar de eerste orde predicatenlogica: Jan of Piet studeert wiskunde Moskou is een stad in Rusland Geen student die 5
Vakles 1 / 2 / 3 / 4. # 3 De leerling leert strategieën te gebruiken voor het uitbreiden van zijn woordenschat.
 A. LEER- EN TOETSPLAN Onderwerp: Grammatica De leerlingen kunnen onderscheiden. De leerlingen kennen elementen van het verbuiging- en vervoegingsysteem. De leerlingen kunnen m.b.v. de betekenis van een
A. LEER- EN TOETSPLAN Onderwerp: Grammatica De leerlingen kunnen onderscheiden. De leerlingen kennen elementen van het verbuiging- en vervoegingsysteem. De leerlingen kunnen m.b.v. de betekenis van een
Lexicografie en lexicologie
 Lexicografie en lexicologie Basisliteratuur: Piet van Sterkenburg (ed.) (2003), A Practical Guide to Lexicography. John Benjamins Publishing Company, Amsterdam/Philadelphia. + aanvullende literatuur op
Lexicografie en lexicologie Basisliteratuur: Piet van Sterkenburg (ed.) (2003), A Practical Guide to Lexicography. John Benjamins Publishing Company, Amsterdam/Philadelphia. + aanvullende literatuur op
Aanvullende informatie ter voorbereiding op de TGN A1. Inleiding. Hoe maakt u de TGN?
 Aanvullende informatie ter voorbereiding op de TGN A1 Inleiding Dit is informatie over de Toets Gesproken Nederlands (of TGN) 1. De TGN maakt deel uit van het inburgeringsexamen buitenland. Moet u de TGN
Aanvullende informatie ter voorbereiding op de TGN A1 Inleiding Dit is informatie over de Toets Gesproken Nederlands (of TGN) 1. De TGN maakt deel uit van het inburgeringsexamen buitenland. Moet u de TGN
IN2505 II Berekenbaarheidstheorie Tentamen Maandag 2 juli 2007, uur
 TECHNISCHE UNIVERSITEIT DELFT Faculteit Elektrotechniek, Wiskunde en Informatica Mekelweg 4 2628 CD Delft IN2505 II Berekenbaarheidstheorie Tentamen Maandag 2 juli 2007, 14.00-17.00 uur BELANGRIJK Beschikbare
TECHNISCHE UNIVERSITEIT DELFT Faculteit Elektrotechniek, Wiskunde en Informatica Mekelweg 4 2628 CD Delft IN2505 II Berekenbaarheidstheorie Tentamen Maandag 2 juli 2007, 14.00-17.00 uur BELANGRIJK Beschikbare
- Communicatie- en informatiewetenschappen
 Bijlage bij OER domein Taal en Communicatie Overzicht majoren en onderwijsonderdelen Opleidingen (met de bijbehorende e major(en)) die binnen Taal en Communicatie vallen: - Communicatie- en informatiewetenschappen
Bijlage bij OER domein Taal en Communicatie Overzicht majoren en onderwijsonderdelen Opleidingen (met de bijbehorende e major(en)) die binnen Taal en Communicatie vallen: - Communicatie- en informatiewetenschappen
Dat heb ik helemaal niet gezegd! De prestaties van de spraakherkenner. Helmer Strik
 Bij mobiele telefonie en automatische informatiediensten wordt vaak gebruikgemaakt van geavanceerde spraaktechnologie: de automatische spraakherkenning. Waarom is de techniek van de spraakherkenning zo
Bij mobiele telefonie en automatische informatiediensten wordt vaak gebruikgemaakt van geavanceerde spraaktechnologie: de automatische spraakherkenning. Waarom is de techniek van de spraakherkenning zo
Vergadering TTNWW, gedeelte Spraak
 Vergadering TTNWW, gedeelte Spraak Nijmegen, 6 april 2010 Aanwezig: Lou Boves, Patrick Wambacq, Jean Pierre Martens, Marc Kemps Snijders, Kris Demuynck, Marijn Huijbregts, Daan Broeder, Arjan van Hessen
Vergadering TTNWW, gedeelte Spraak Nijmegen, 6 april 2010 Aanwezig: Lou Boves, Patrick Wambacq, Jean Pierre Martens, Marc Kemps Snijders, Kris Demuynck, Marijn Huijbregts, Daan Broeder, Arjan van Hessen
2. Syntaxis en semantiek
 2. Syntaxis en semantiek In dit hoofdstuk worden de begrippen syntaxis en semantiek behandeld. Verder gaan we in op de fouten die hierin gemaakt kunnen worden en waarom dit in de algoritmiek zo desastreus
2. Syntaxis en semantiek In dit hoofdstuk worden de begrippen syntaxis en semantiek behandeld. Verder gaan we in op de fouten die hierin gemaakt kunnen worden en waarom dit in de algoritmiek zo desastreus
De richtprijs voor een lezing is 400,- excl. reiskosten. Voor een workshop zijn de kosten afhankelijk van de invulling van de workshop.
 Lezingen Een lezing duurt 45 minuten tot een uur, gevolgd door de mogelijkheid om vragen te stellen en te discussiëren. De lezingen worden op locatie gegeven. Workshops Meer dan tijdens een lezing zijn
Lezingen Een lezing duurt 45 minuten tot een uur, gevolgd door de mogelijkheid om vragen te stellen en te discussiëren. De lezingen worden op locatie gegeven. Workshops Meer dan tijdens een lezing zijn
Flitsend Spellen en Lezen 1
 Flitsend Spellen en Lezen 1 Flitsend Spellen en Lezen 1 is gericht op het geven van ondersteuning bij het leren van Nederlandse woorden, om te beginnen bij de klanklettercombinaties. Doelgroep Flitsend
Flitsend Spellen en Lezen 1 Flitsend Spellen en Lezen 1 is gericht op het geven van ondersteuning bij het leren van Nederlandse woorden, om te beginnen bij de klanklettercombinaties. Doelgroep Flitsend
Fries in data-gestuurde automatische vertaling
 Juni 2012 Inleiding Automatisch vertalen Fries-Nederlands Doelstelling: Het ontwikkelen van een automatisch vertaalsysteem voor Fries-Nederlands en Nederlands-Fries Samenwerking Fryske Akademy Radboud
Juni 2012 Inleiding Automatisch vertalen Fries-Nederlands Doelstelling: Het ontwikkelen van een automatisch vertaalsysteem voor Fries-Nederlands en Nederlands-Fries Samenwerking Fryske Akademy Radboud
Taaljournaal Leerlijnenoverzicht - Lezen
 Taaljournaal Leerlijnenoverzicht - Lezen 1.1 Eigen kennis 1.1.1 Kinderen kunnen hun eigen kennis activeren, m.a.w. ze kunnen aangeven wat ze over een bepaald onderwerp al weten en welke ervaringen ze er
Taaljournaal Leerlijnenoverzicht - Lezen 1.1 Eigen kennis 1.1.1 Kinderen kunnen hun eigen kennis activeren, m.a.w. ze kunnen aangeven wat ze over een bepaald onderwerp al weten en welke ervaringen ze er
- Denkt zoals een mens (activiteiten die we associëren met menselijk denken.)
") Samenvatting door S. 942 woorden 19 maart 2017 4,8 6 keer beoordeeld Vak Informatica Hoofdstuk 1: Een entiteit is intelligent wanneer het: - Denkt zoals een mens (activiteiten die we associëren met menselijk
Samenvatting door S. 942 woorden 19 maart 2017 4,8 6 keer beoordeeld Vak Informatica Hoofdstuk 1: Een entiteit is intelligent wanneer het: - Denkt zoals een mens (activiteiten die we associëren met menselijk
Informatiekunde in Groningen
 kunde in John Alfa-informatica Rijksuniversiteit Huus van de Taol 3 juni 2009 Technologie voor taal kunde Studie waar computer centraal staat: Programmeren, ontwerpen, analyseren van ICT producten Gericht
kunde in John Alfa-informatica Rijksuniversiteit Huus van de Taol 3 juni 2009 Technologie voor taal kunde Studie waar computer centraal staat: Programmeren, ontwerpen, analyseren van ICT producten Gericht
Collectie FRA: Franse taal- en letterkunde
 Inhoud Collectie 2 Plaatsingssysteem 3 Hoofdindeling 4 Taal- en letterkunde 5 Taalkunde 6 Letterkunde 10 Geografische codes 14 Handboeken en naslagwerken 14 p. 1 / 14 Collectie Binnen de collectie Frans
Inhoud Collectie 2 Plaatsingssysteem 3 Hoofdindeling 4 Taal- en letterkunde 5 Taalkunde 6 Letterkunde 10 Geografische codes 14 Handboeken en naslagwerken 14 p. 1 / 14 Collectie Binnen de collectie Frans
Het Nederlands in taal- en spraaktechnologie: prioriteiten voor basisvoorzieningen
 Het Nederlands in taal- en spraaktechnologie: prioriteiten voor basisvoorzieningen Walter Daelemans & Helmer Strik (red.) Een rapport in opdracht van de Nederlandse Taalunie 01/07/2002 Projectuitvoerders:
Het Nederlands in taal- en spraaktechnologie: prioriteiten voor basisvoorzieningen Walter Daelemans & Helmer Strik (red.) Een rapport in opdracht van de Nederlandse Taalunie 01/07/2002 Projectuitvoerders: