De bijbel der SPSS procedures
|
|
|
- Willem Kuiper
- 7 jaren geleden
- Aantal bezoeken:
Transcriptie
1 De bijbel der SPSS procedures Onze SPSS die op de computer zijt Geheiligd zijn uw functies Uw regressies kome, Uw output geschiede op papier als op scherm. Geef ons heden onze dagelijkse anova en vergeef ons dat wij niet naar de lessen gingen gelijk ook wij vergeven aan onze proffen. En leid ons niet naar een onvoldoende, maar verlos ons van een tweede zit. Amen Samenvatting van de SPSS procedures die deel uitmaken van de cursus Data-Analyse I. Joris Pieters 2006

2 Inhoud 2 Opmerkingen 3 1. Univariaat lineair model (1 afhankelijke variabele) Algemeen lineair model (Afhankelijke variabele op intervalniveau) Enkelvoudige regressie (1 predictor op intervalniveau) Meervoudige regressie (Meer dan 1 predictor op intervalniveau) Anova (Predictoren zijn categorisch) Ancova (Zowel interval als categorische predictoren) Veralgemeend lineair model (Afhankelijke variabele categorisch) Binaire logistische regressie (Afhankelijke is categorisch) Loglineaire modellen (Afhankelijke is frequentie of percentage) Poisson Regressie (Afhankelijke is een count ) Bilineaire modellen Verschil tussen PCA en FA Rotatie Principale component analyse Factoranalyse Clusteranalyse Hiërarchische clusteranalyse K-Means clusteranalyse Uitgewerkte oefening Ancova of meervoudige regressie??? Oefening Opgave Oplossing Rapport 34 2
 18 2. Bilineaire modellen 19 2.1 Verschil tussen PCA en FA 19 2.2 Rotatie 19 2.3 Principale component analyse 22 2.4 Factoranalyse 23 3.")
3 Opmerkingen Ter verduidelijking van output: Alle zaken die handig zouden kunnen zijn bij de rapportage staan vermeld. Per puntje ( a.), b.), ) staat eerst vermeldt wat het is, achter de dubbele punt staat de naam van de SPSS-tabel. Na het pijltje staat in de naam van de kolom. Daarachter staat tussen vierkante haakjes de rij van de tabel. Voorbeeld: e.) Significantie van het model: ANOVA Sig. [Regression] Betekent: Om te weten of in dit model de afhankelijke variabele significant wordt voorspeld door de onafhankelijke variabelen ga je kijken in de output in de tabel ANOVA. Kijk dan op het kruispunt van de kolom Sig. en de rij Regression. We zien enkel modellen met één afhankelijke variabele. Voor modellen met meerdere afhankelijke variabelen (multivariate modellen) zie data-analyse II en toegepaste dataanalyse. 3

4 1. Univariaat lineair model 1.1 Algemeen lineair model (Afhankelijke variabele op intervalniveau) Enkelvoudige regressie (1 predictor op intervalniveau) Analyze Regression Linear Dependent: Afhankelijke variabele Independent(s): Onafhankelijke variabele Output a.) Verklaarde variantie in steekproef: Model Summary R Square b.) Verklaarde variantie in populatie: Model Summary Adjusted R Square c.) β0: Coefficients B [Constant] d.) β1: Coefficients B [naam van de predictor] e.) Significantie van het model: ANOVA Sig. [Regression] f.) Significantie van predictor: Coefficients Sig. [naam van de predictor] OPMERKING: (e) en (f) zijn hier (uiteraard) gelijk aan elkaar Meervoudige regressie (Meer dan 1 predictor op intervalniveau) A.) Gewoon: Volledig model vergelijken met een model met geen enkele parameter Analyze Regression Linear Dependent: Afhankelijke variabele Independent(s): Onafhankelijke variabelen Output a.) Verklaarde variantie in steekproef: Model Summary R Square b.) Verklaarde variantie in populatie: Model Summary Adjusted R Square c.) β0: Coefficients B [Constant] d.) β1: Coefficients B [naam van de eerste predictor] e.) β : Coefficients B [naam van de predictor] f.) Significantie van het model: ANOVA Sig. [Regression] g.) Significantie van predictor: Coefficients Sig. [naam van de predictor] 4
![) β1: Coefficients B [naam van de predictor] e.) Significantie van het model: ANOVA Sig. [Regression] f.) Significantie van predictor: Coefficients Sig.](/docs-images/49/19254799/images/page_4.jpg "[naam van de predictor] OPMERKING: (e) en (f) zijn hier (uiteraard) gelijk aan elkaar. 1.1.2 Meervoudige regressie (Meer dan 1 predictor op intervalniveau) A.")
5 B.) Modelvergelijking - hiërarchische regressie: Model vergelijken met beperkter model (MODEL 2 bevat meer predictoren dan MODEL 1. MODEL 0 is het model zonder predictoren) Analyze Regression Linear Dependent: Afhankelijke variabele Independent(s): Onafhankelijke variabelen MODEL 1 [Next] Independent(s): Onafhankelijke variabelen die wel in MODEL 2 [Statistics ] R squared change maar niet in MODEL 1 zitten. Output a.) Verklaarde variantie MODEL 1 (of 2) t.o.v. MODEL 0 in steekproef: Model Summary R Square [1 (of 2)] b.) Verklaarde variantie MODEL 1 (of 2) t.o.v. MODEL 0 in populatie: Model Summary Adjusted R Square [1 (of 2)] c.) Verklaarde variantie MODEL 2 bovenop verklaarde variantie MODEL 1: Model Summary R Square Change [2] d.) Significantie van MODEL 1 t.o.v. MODEL 0: Model Summary Sig. F Change [1] e.) Significantie van MODEL 2 t.o.v. MODEL 1: Model Summary Sig. F Change [2] f.) β0, β1, β & Significantie van de predictoren: Zie eerder. C.) Confidentie-interval voor de impact van een predictor (β) Analyze Regression Linear Dependent: Afhankelijke variabele Independent(s): Onafhankelijke variabele [Statistics ] Confidence intervals Output a.) 95% Confidentie-interval voor de impact van een variabele: Coefficients Lower/Upper Bound [naam van de predictor] 5
![die wel in MODEL 2 [Statistics ] R squared change maar niet in MODEL 1 zitten. Output a.) Verklaarde variantie MODEL 1 (of 2) t.o.v. MODEL 0 in steekproef: Model Summary R Square [1 (of 2)] b.](/docs-images/49/19254799/images/page_5.jpg ") Verklaarde variantie MODEL 1 (of 2) t.o.v. MODEL 0 in populatie: Model Summary Adjusted R Square [1 (of 2)] c.")
6 D.) Modelvergelijking waarin ook (of enkel) categorische predictoren zitten. OPMERKING: Indien je met categorische predictoren zit maar geen modelvergelijking moet doen gebruik dan Anova of Ancova, dan moet je niet hercoderen. voor hercoderen (Hier enkel effectcodering. Voorbeeld voor een variabele met 3 niveaus 2 hulpveranderlijken) Transform Recode Into Different Variables Input Variable -> Output Variable: [naam van de variabele] Name: EffectEduclev1 (of iets anders, noem het zoals je wilt) [Change] [Old and New Values ] Old Value: 1 New Value: -1 [Add] Old Value: 2 New Value: 1 [Add] Old Value: 3 New Value: 0 [Add] Transform Recode Into Different Variables Input Variable -> Output Variable: [naam van de variabele] Name: EffectEduclev2 [Change] [Old and New Values ] Old Value: 1 New Value: -1 [Add] Old Value: 2 New Value: 0 [Add] Old Value: 3 New Value: 1 [Add] De modelvergelijking loopt net hetzelfde als eerder besproken, maar in plaats van de categorische variabele in te voegen bij Independent voeg je daar de hulpveranderlijken in. Als je meer dan één hulpveranderlijke nodig had is het niet mogelijk om te zien of het effect van deze variabele significant is aangezien de significantie van de hulpveranderlijken 6
![Voorbeeld voor een variabele met 3 niveaus 2 hulpveranderlijken) Transform Recode Into Different Variables Input Variable -> Output Variable: [naam van de variabele] Name: EffectEduclev1 (of iets](/docs-images/49/19254799/images/page_6.jpg "anders, noem het zoals je wilt) [Change] [Old and New Values ] Old Value: 1 New Value: -1 [Add] Old Value: 2 New Value: 1 [Add] Old Value: 3 New Value: 0 [Add] Transform Recode Into Different")
7 getoond wordt. Oplossing: De twee of meer gebruikte hulpveranderlijken invoegen als een apart model. E.) Interactietermen in regressie. Stel: B modereert de relatie tussen A en Z voor niet-gestandaardiseerde methode Analyze Descriptive Statistics Descriptives Variable(s): A, B Transform Compute Target Variable: Dev[naam van eerste variabele] (vb: DevA ) Numeric Expression: [naam van eerste variabele] [gemiddelde] (zie output onder Mean vb: A 5 ) Transform Compute Target Variable: Dev[naam van tweede variabele] (vb: DevB ) Numeric Expression: [naam van tweede variabele] [gemiddelde] (zie output onder Mean vb: B 9 ) Transform Compute Target Variable: IntAB Numeric Expression: DevA * DevB Analyze Regression Linear Dependent: Z Independent(s): DevA, DevB, IntAB Output a.) β0, β1, β & Significantie van de predictoren: Zie eerder. OPMERKING: Als het effect van de interactie significant is, dan mag je de hoofdeffecten van de variabelen NIET interpreteren! voor gestandaardiseerde methode Analyze Descriptive Statistics Descriptives Variable(s): A, B, Z Save standardized values as variables (SPSS maakt nu 3 nieuwe variabelen aan: de standaardscores van A, B, Z ZA, ZB, ZZ.) 7
![variabele] (vb: DevA ) Numeric Expression: [naam van eerste variabele] [gemiddelde] (zie output onder Mean vb: A 5 ) Transform Compute Target Variable: Dev[naam van tweede variabele] (vb: DevB )](/docs-images/49/19254799/images/page_7.jpg "Numeric Expression: [naam van tweede variabele] [gemiddelde] (zie output onder Mean vb: B 9 ) Transform Compute Target Variable: IntAB Numeric Expression: DevA * DevB Analyze Regression Linear")
8 Transform Compute Target Variable: ZIntAB Numeric Expression: ZA * ZB Analyze Regression Linear Dependent: ZZ Independent(s): ZA, ZB, ZIntAB Output a.) β0, β1, β & Significantie van de predictoren: Zie eerder. OPMERKING: Als het effect van de interactie significant is, dan mag je de hoofdeffecten van de variabelen NIET interpreteren! Ongeacht de niet-gestandaardiseerde of de gestandaardiseerde procedure zijn de significantiewaarden van de predictoren identiek. De β s verschillen. Op basis van voorgaande een predictie doen: voor niet-gestandaardiseerde methode Ź i = b 0 + b 1 *A i + b 2 *B i + b 3 (A*B) i a.) b s: zie Coefficients B b.) A = Geobserveerde waarde voor eerste variabele Gemiddelde voor die variabele (Want het gaat om deviatiescores!) c.) B = Geobserveerde waarde voor tweede variabele Gemiddelde voor die variabele (Want het gaat om deviatiescores!) voor gestandaardiseerde methode Ź i = {[b 0 + b 1 *A i + b 2 *B i + b 3 (A*B) i ] * Standaarddeviatie Z} + Gemiddelde van Z a.) b s: zie Coefficients B b.) A = (Geobserveerde waarde Gemiddelde) / Standaarddeviatie c.) B = (Geobserveerde waarde Gemiddelde) / Standaarddeviatie F.) Meer gecompliceerde modelvergelijkingen Stel: Een model met 4 predictoren 5 β s: 1 voor het intercept en 1 per predictor. Y i = β 0 + β 1 X i1 + β 2 X i2 + β 3 X i3 + β 4 X i4 (De predictoren noemen A, B, C, D. De afhankelijke variabele noemt Z) 8
 i a.) b s: zie Coefficients B b.")
9 Voorbeeld: 3 hypotheses. Schrijf ze zodanig dat het steeds een vergelijking ten opzichte van 0 is. 1.) β 1 = 0 (Merk op dat wanneer je enkel dit wil toetsen je ook een modelvergelijking kan doen.) [1.1.2B; p.5] 2.) 2β 2 = β 1 + β 3 - β 1 + 2β 2 - β 3 = 0 3.) β 2 = β 3 β 2 β 3 = 0 (Merk op dat bij hypothese 2 en 3 appelen met peren vergeleken worden: om te weten of één predictor even veel effect heeft op de afhankelijke variabele als twee andere samen (zoals in hypothese 2) of om te weten of twee predictoren een even groot effect uitoefenen op de afhankelijke variabele (zoals in hypothese 3) moet je de predictoren eerst standaardiseren. Eigenaardig genoeg gebeurt dit niet op de slides van professor De Corte.) Geeft volgende tabel: β 0 β 1 β 2 β 3 β 4 Hypothese Hypothese Hypothese Analyze General Linear Model Univariate Dependent Variable: Afhankelijke variabele Covariate(s): Categorische onafhankelijke variabelen (Onafhankelijke dus NIET bij Fixed Factor(s)!!! + Zet variabelen in de volgorde die overeenkomt met de β s!!!) [Paste] UNIANOVA Z WITH A B C D /lmatrix Toets parameter all ; all ; all /METHOD = SSTYPE(3) /INTERCEPT = INCLUDE /print = parameter test(lmatrix) /CRITERIA = ALPHA(.05) /DESIGN = A B C D. [ ] (Dit is volledig equivalent aan de tabel. Vergeet de punt-komma s niet!!!) (Merk op dat bovenstaande qua procedure een Ancova is en geen meervoudige regressie! Meer hierover in het laatste deel.) Output a.) Significantie contrast 1: Contrast Results [L1: Sig.] b.) Significantie contrast : Contrast Results [L : Sig.] c.) Significantie van de toetsen samen: Test Results Sig. 9
 of om te weten of twee predictoren een even groot effect uitoefenen op de afhankelijke variabele (zoals in hypothese 3) moet je de predictoren eerst standaardiseren.")
10 1.1.3 Anova (Predictoren zijn categorisch) A.) Volledige toets Analyze General Linear Model Univariate Dependent Variable: Afhankelijke variabele Fixed Factor(s): [Options ] [Plots ] Categorische onafhankelijke variabelen Display Means for: Alle variabelen inclusief de interactie(s) Parameter estimates Horizontal Axis: Separate Lines: [Add] De variabele met de meeste waarden De variabele met de minste waarden Output a.) Verklaarde variantie: Test of Between-Subjects Effects [Onder de tabel] b.) Significantie van de predictoren: Test of Between-Subjects Effects Sig. OPMERKING: Als het effect van de interactie significant is, dan kan je de hoofdeffecten van de variabelen NIET eenduidig interpreteren, wel interpretatie van de eenvoudige hoofdeffecten. c.) Geschatte (verwachte) waarde van een celgemiddelde: - Parameter estimates Tel het intercept en alle waarden die voor die cel ter zake doen bij elkaar op. Voorbeeld: Wat is de voorspelde waarde van de cel (2,1)? Oplossing: Intercept + α 2 + β 1 + γ 21 - Andere manier: kijk in de tabel van de desbetreffende interactie Mean Modelvergelijking: Dit is nodig als je de significantie van 1 van de predictoren of van de interactie wil kennen: a.) Hercodeer de onafhankelijke variabelen [1.1.2D; p.6] b.) Maak de interactievariabelen aan. Opgelet, per interactieterm heb je (I-1)(J-1) nieuwe variabelen nodig. Stel predictor A heeft 3 niveaus, en predictor B heeft er 2 2 interactieniveaus (Interact1 & Interact2) Transform Compute Target Variable: Interact1 Numeric Expression: EffectA1 * EffectB 10
![Alle variabelen inclusief de interactie(s) Parameter estimates Horizontal Axis: Separate Lines: [Add] De variabele met de meeste waarden De variabele met de minste waarden Output a.](/docs-images/49/19254799/images/page_10.jpg ") Verklaarde variantie: Test of Between-Subjects Effects [Onder de tabel] b.) Significantie van de predictoren: Test of Between-Subjects Effects Sig.")
11 Transform Compute Target Variable: Interact2 Numeric Expression: EffectA2 * EffectB c.) Doe een modelvergelijking [1.1.2B; p.5] - Bij Block 1 zet je alle variabelen behalve diegene waarvan je het effect wil kennen binnen het volledige model. - De overige variabele zet je in Block 2. - Voor iedere categorisch onafhankelijke variabelen voeg je NIET die variabele in, maar wel de gehercodeerde variabele(n)! - Vergeet niet om de variabele(n) voor de interactie in te voegen in Block 1, of in Block 2 als je het effect van interactie afzonderlijk wil bekijken. B.) Toetsen van contrasten (met A en B zijn onafhankelijke variabelen met respectievelijk 3 en 2 waarden, Z is de afhankelijke) Voorbeeld 1: Eén contrast µ 21 = µ. 2 µ 21 - µ. 2 = 0 Probleem: µ. 2 bestaat niet op zich, maar bestaat uit µ 12, µ 22, µ 32 µ 21 1/3 µ 12 1/3 µ 22 1/3 µ 32 = 0 Deze 4 termen bestaan eveneens niet op zichzelf, maar bestaan uit: µ 21 = µ + α 2 + β 1 + γ 21 µ 12 = µ + α 1 + β 2 + γ 12 µ 22 = µ + α 2 + β 2 + γ 22 µ 32 = µ + α 3 + β 2 + γ 32 Met andere woorden: α krijgt het eerste subscript, β krijgt het tweede subscript, γ krijgt beide. Als we nu de vergelijking uitschrijven krijgen we dit: µ + α 2 + β 1 + γ 21 1/3(µ + α 1 + β 2 + γ 12 ) 1/3(µ + α 2 + β 2 + γ 22 ) 1/3(µ + α 3 + β 2 + γ 32 ) = 0 Vereenvoudigd en in de meest logische volgorde geschreven is dit: - 1/3 α 1 + 2/3 α 2 1/3 α 3 + β 1 - β 2 1/3 γ 12 + γ 21 1/3 γ 22 1/3 γ 32 =0 11
 voor de interactie in te voegen in Bl")
12 Maken we nu een tabel van deze vergelijking: µ α 1 α 2 α 3 β 1 β 2 γ 11 γ 12 γ 21 γ 22 γ 31 γ /3 2/3-1/ /3 1-1/3 0-1/3 Betreffende de γ s: De achterste index loopt het snelste op! Dit is belangrijk, want SPSS gaat er van uit dat je het zo doet. Ter controle: tel na of de som van alle getallen in de tabel gelijk is aan 0. Analyze General Linear Model Univariate Dependent Variable: Afhankelijke variabele Fixed Factor(s): [Paste] UNIANOVA Z BY A B /lmatrix Toets contrast A -1/3 2/3-1/3 B 1-1 Categorische onafhankelijke variabelen (Dit zijn de waarden voor de α s in de tabel) (Dit zijn de waarden voor de β s in de tabel) A*B 0-1/3 1-1/3 0-1/3 (Dit zijn de waarden voor de γ s in de tabel) /METHOD = SSTYPE(3) /INTERCEPT = INCLUDE /CRITERIA = ALPHA(.05) /print = test(lmatrix) /DESIGN = A B A*B. [ ] (Opgelet: Er wordt hier maar één contrast getoetst, er mogen hier daarom geen punt-komma s staan!) Voorbeeld 2: Twee contrasten µ 21 = µ. 2 & µ. 1 = µ 32 Contrast 1: (Zie voorbeeld 1) µ 21 = µ. 2 µ 21-1/3 µ 12-1/3 µ 22 1/3 µ 32 = 0-1/3 α 1 + 2/3 α 2 1/3 α 3 + β 1 - β 2 1/3 γ 12 + γ 21 1/3 γ 22 1/3 γ 32 = 0 Contrast 2: µ. 1 = µ 32 µ. 1 - µ 32 = 0 (µ. 1 bestaat uit µ 11, µ 21, µ 31 ) 1/3 µ /3 µ /3 µ 31 - µ 32 = 0 µ 11 = µ + α 1 + β 1 + γ 11 µ 21 = µ + α 2 + β 1 + γ 21 µ 31 = µ + α 3 + β 1 + γ 31 µ 32 = µ + α 3 + β 2 + γ 32 12
![Analyze General Linear Model Univariate Dependent Variable: Afhankelijke variabele Fixed Factor(s): [Paste] UNIANOVA Z BY A B /lmatrix Toets contrast A -1/3 2/3-1/3 B 1-1 Categorische onafhankelijke](/docs-images/49/19254799/images/page_12.jpg "variabelen (Dit zijn de waarden voor de α s in de tabel) (Dit zijn de waarden voor de β s in de tabel) A*B 0-1/3 1-1/3 0-1/3 (Dit zijn de waarden voor de γ s in de tabel) /METHOD = SSTYPE(3)")
13 1/3(µ + α 1 + β 1 + γ 11 ) + 1/3(µ + α 2 + β 1 + γ 21 ) + 1/3 (µ + α 3 + β 1 + γ 31 ) (µ + α 3 + β 2 + γ 32 ) = 0 Uitgewerkt: 1/3 α 1 + 1/3 α 2 2/3 α 3 + β 1 - β 2 + 1/3 γ /3 γ /3 γ 31 - γ 32 = 0 µ α 1 α 2 α 3 β 1 β 2 γ 11 γ 12 γ 21 γ 22 γ 31 γ 32 Contrast1 0-1/3 2/3-1/ /3 1-1/3 0-1/3 Contrast2 0 1/3 1/3-2/ /3 0 1/3 0 1/3-1 Analyze General Linear Model Univariate Dependent Variable: Afhankelijke variabele Fixed Factor(s): Categorische onafhankelijke variabelen [Paste] UNIANOVA Z BY A B /lmatrix Toets contrast A -1/3 2/3-1/3 B 1-1 (Contrast 1) A*B 0-1/3 1-1/3 0-1/3 ; (Vergeet de punt-komma niet A 1/3 1/3-2/3 tussen de contrasten!!!) B 1-1 (Contrast 2) A*B 1/3 0 1/3 0 1/3-1 /METHOD = SSTYPE(3) /INTERCEPT = INCLUDE /CRITERIA = ALPHA(.05) /print = test(lmatrix) /DESIGN = A B A*B. [ ] Output a.) Significantie contrast 1: Contrast Results [L1: Sig.] b.) Significantie contrast : Contrast Results [L : Sig.] c.) Significantie van de toetsen samen: Test Results Sig. 13
![Dependent Variable: Afhankelijke variabele Fixed Factor(s): Categorische onafhankelijke variabelen [Paste] UNIANOVA Z BY A B /lmatrix Toets contrast A -1/3 2/3-1/3 B 1-1 (Contrast 1) A*B 0-1/3 1-1/3](/docs-images/49/19254799/images/page_13.jpg "0-1/3 ; (Vergeet de punt-komma niet A 1/3 1/3-2/3 tussen de contrasten!!!) B 1-1 (Contrast 2) A*B 1/3 0 1/3 0 1/3-1 /METHOD = SSTYPE(3) /INTERCEPT = INCLUDE /CRITERIA = ALPHA(.")
14 C.) Hiërarchische opzetten (genest(eld)e factoren) Voorbeeld: A = School, B = Provincie, C = Inrichtende macht A is genesteld binnen B * C Notatie: A(B*C) Analyze General Linear Model Univariate Dependent Variable: Afhankelijke variabele Fixed Factor(s): (Niets ingeven hier!) [Paste] UNIANOVA Z by A B C /METHOD = SSTYPE(3) /INTERCEPT = INCLUDE /CRITERIA = ALPHA(.05) /design = A within B by C B C B*C. (Vergeet niet het puntje achter ALPHA(.05) te wissen en achter B*C te zetten!!!) Output a.) Het interactie-effect bevat hier A niet en A zelf staat vermeld als A(A*B) beide omwille van het feit dat A genesteld is binnen B * C Ancova (Zowel interval als categorische predictoren) Hieronder worden twee speciale toepassingen van Ancova beschreven, gebaseerd op de cursus. Algemeen echter is Ancova gewoon die procedure waarbij je zowel categorische als continue predictoren ingeeft. Voorbeelden hiervan komen aan bod in het laatste deel. Merk op dat de procedure er gelijkaardig uitziet als de Anova-procedure. Het enige verschil is het feit dat er ook Covariates (continue predictoren) worden ingevoerd. Zoals eerder gezien [1.1.2D; p.6] kan je ook multipele regressie (Analyze Regression Linear ) gebruiken als je zowel categorische als continue predictoren hebt. Het nadeel daar is echter dat je dan je categorische predictoren moet hercoderen (omdat SPSS die niet beschouwd als zijnde categorisch). Meer duidelijkheid over welk van de twee procedures je nu best kan gebruiken in welke situatie komt aan bod in het laatste deel. A.) Statistische controle: door toevoeging van continue predictoren ( covariaten ) een voorspelling op basis van categorische predictoren statistisch gevoeliger maken. Analyze General Linear Model Univariate Dependent Variable: Afhankelijke variabele Fixed Factor(s): Categorische predictor(en) Covariate(s): Continue predictor(en) 14
 Het interactie-effect bevat hier A niet en A zelf staat vermeld als A(A*B) beide omwille van het feit dat A genesteld is binnen B * C. 1.")
15 Output a.) Significantie van de predictor(en) na statistische controle voor de continue predictor(en): Test of Between-Subjects Effects Sig. [naam van de categorische predictor(en)] B.) Toetsing homogeniteit binnencel regressies: Heeft de regressie van de continue predictor op de afhankelijke variabele de zelfde helling in iedere cel. (Cellen: de verschillende waarden van de categorische predictor) Analyze General Linear Model Univariate Dependent Variable: Afhankelijke variabele Fixed Factor(s): Categorische predictor(en) Covariate(s): Continue predictor(en) [Model ] Custom Model: [naam van de categorische predictor] [naam van de continue predictor] [categorische] * [continue] (selecteer hiervoor beide en druk op het pijltje) Output a.) Zijn de binnencelregressies homogeen: Test of Between-Subjects Effects Sig. [categorische] * [continue] Indien significant (p < 0.05): Binnencelregressies zijn NIET homogeen en verschillen dus van elkaar. Indien niet significant (p > 0.05): Binnencelregressies zijn WEL homogeen. 15
: Continue predictor(en) [Model ] Custom Model: [naam van de categorische predictor] [naam van de continue predictor] [categorische] * [continue] (selecteer hiervoor beide en druk op het")
16 1.2 Veralgemeend lineair model (Afhankelijke variabele categorisch) Binaire logistische regressie (Afhankelijke is categorisch) De afhankelijke variabele is dichotoom Kan enkel waarden 0 of 1 aannemen. A.) Voorspellen op basis van toeval (Model 0) vs. voorspellen met predictoren (Model 1) Opgelet: Je kan zowel categorische als continue predictoren invoeren, maar als het categorische predictoren zijn moet je ze eerst hercoderen. Uitzondering: als de categorische predictor enkel de waarden 0 en 1 heeft mag je hem zo ingeven (aangezien dit overeenkomt met Dummy-codering). [1.2.1C; p.17] Analyze Regression Binary Logistic Dependent: Afhankelijke variabele Covariates: [Options ] Iteration history Onafhankelijke variabelen Output Block 0: Beginning Block a.) Verlies geassocieerd met model 0: Iteration History -2 Log likelihood [onderste] b.) De kans op basis van toeval op waarde 0 op de afhankelijke variabele: Classification Table Percentage Correct [Overal Percentage] (De kans op waarde 1 op de afhankelijke variabele is dan uiteraard 1- aangezien het om een dichtome afhankelijke variabele gaat) c.) De kans op basis van toeval op waarde 0 gedeeld door de kans op basis van toeval op de waarde 1: Variables in the Equation Exp(B) Output Block 1: Method = Enter a.) Verlies geassocieerd met model 1: Iteration History -2 Log likelihood [onderste] b.) Likelihood Ratio: Omnibus Tests of Model Coefficients Chi-square (= Het verschil tussen verlies geassocieerd met model 0 en met model 1) De significantie (Sig.) zegt ons of model 1 beter is dan model 0. Met andere woorden: Hebben de predictoren enig nut bovenop een voorspelling op basis van toeval. c.) Percentage correcte voorspellingen op basis van de onafhankelijke variabelen: Classification Table Percentage Correct [Overall Percentage] d.) Belang van de predictoren: Variables in the Equation Exp(B) * B kleiner dan 1: Hoe hoger de waarde op die predictor, hoe kleiner de kans op waarde 1 op de afhankelijke variabele. * B groter dan 1: Hoe hoger de waarde op die predictor, hoe groter de Kans op waarde 1 op de afhankelijke variabele. 16
. [1.2.1C; p.")
17 B.) Model vergelijken met beperkter model. Analyze Regression Binary Logistic Dependent: Afhankelijke variabele Covariates: Onafhankelijke variabelen MODEL 1 [Next] Covariates: Onafhankelijke variabelen die wel in MODEL 2 [Options ] Iteration history maar niet in MODEL 1 zitten. Output Block 1: Method = Enter a.) Significantie van Model 1 ten opzichte van Model 0: Omnibus Tests of Model Coefficients Sig. Output Block 2: Method = Enter a.) Significantie van Model 2 ten opzichte van Model 1: Omnibus Tests of Model Coefficients Sig. [Step of Block] b.) Significantie van Model 2 ten opzichte van Model 0: Omnibus Tests of Model Coefficients Sig. [Model] C.) Categorische predictoren met meer dan twee waarden. Je kan zowel Dummy-, Effect- en Contrastcodering gebruiken, maar aangezien sommige categorische variabelen reeds in Dummy staan (Als ze enkel de niveaus 0 en 1 hebben) wanneer je de data ingeeft is het het gemakkelijkste om ineens alles in Dummy te doen (Dummy noemt indicator in SPSS). Analyze Regression Binary Logistic Dependent: Afhankelijke variabele Covariates: Onafhankelijke variabelen (zowel interval als categorische) [Categorial ] Categorial Covariates: De onafhankelijke variabele die gehercodeert dient te worden Voor interactietermen tussen categorische variabelen: Selecteer ze links (Ctrl ingedrukt houden) en druk: [>a*b>] 17
 Significantie van Model 2 ten opzichte van Model 1: Omnibus Tests of Model Coefficients Sig. [Step of Block] b.")
18 Output Block 1: Method = Enter a.) Impact van de niveaus van de gehercodeerde categoriale variabele: Variables in the Equation Exp(B) Opgelet: Aangezien het laatste niveau van de variabele referentieniveau is betreft de rij [naam van de variabele] op het laatste niveau. [naam van de variabele](1) betreft dan het 1 e niveau van de variabele en zo verder. Exp(B) geeft telkens de impact van het niveau van de variabele weer ten opzichte van het referentieniveau. Als je ten opzichte van het eerste niveau wil vergelijken doe dan de procedure opnieuw, maar: [Categorial ] Selecteer de variabele in de kolom Categorical Covariates First [Change] Wil je de impact van een variabele vergelijken met de gemiddelde impact, dan moet je effect codering gebruiken ( deviation in SPSS): [Categorial ] Selecteer de variabele in de kolom Categorical Covariates Contrast: Deviation [Change] Loglineaire modellen (Afhankelijke is frequentie of percentage) Geen leerstof Poisson Regressie (Afhankelijke is een count ) Geen leerstof 18
![van de variabele] op het laatste niveau. [naam van de variabele](1) betreft dan het 1 e niveau van de variabele en zo verder.](/docs-images/49/19254799/images/page_18.jpg "Exp(B) geeft telkens de impact van het niveau van de variabele weer ten opzichte van het referentieniveau.")
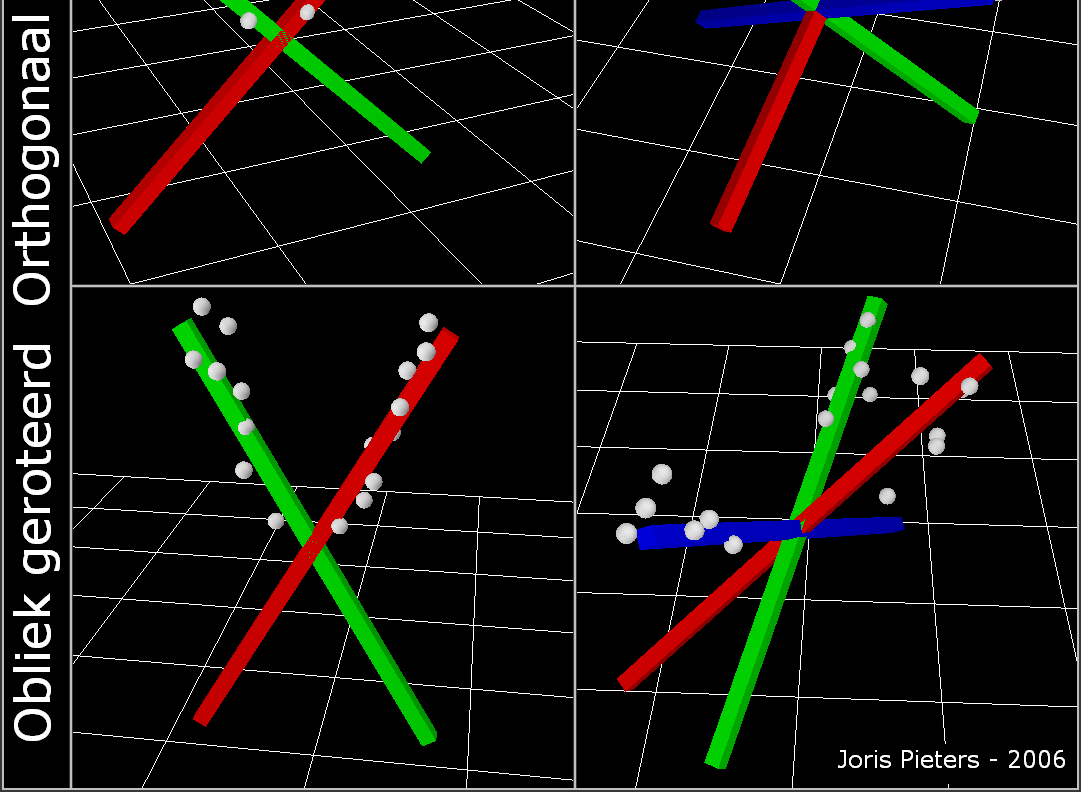
19 2. Bilineaire modellen 2.1 Verschil tussen PCA en FA Zowel principale componentanalyse als factoranalyse hebben als doel een groot aantal variabelen te reduceren tot een kleiner aantal. Dit gebeurt op basis van de correlaties tussen de variabelen. Hoog gecorreleerde variabelen zullen samen één component of factor vormen. Het grote voordeel hiervan is dat je daarna een regressie kan doen met veel minder variabelen. Principale componentanalyse ga je gebruiken wanneer je verschillende variabelen hebt die allemaal éénzelfde observeerbaar construct meten, bijvoorbeeld verschillende soorten metingen van gewicht ( gewicht gemeten door een balans, gewicht gemeten met een elektronische weegschaal, buikomtrek ) kunnen samen worden beschouwd als één nieuwe variabele. Factoranalyse daarentegen gebruik je wanneer de gecorreleerde variabelen éénzelfde onderliggend construct meten. Typevoorbeeld hiervan zijn vragenlijsten: de vragen ik spreek regelmatig onbekenden aan op straat, op feestjes ben ik altijd diegene die zorgt voor de ambiance, en ik durf nooit een vraag te stellen tijdens de les kunnen beschouwd worden aan variabelen onderliggend aan de factor Extraversie. Merk op dat de laatste vraag juist het tegenovergestelde leek te meten. Dit doet totaal niet ter zake aangezien het gaat om hoge absolute correlaties (dus dicht bij -1 of dicht bij 1). Soms is het onderscheid tussen observeerbare en onderliggende constructen misschien niet zo duidelijk, daarom een vuistregeltje: heb je fysieke variabelen gebruik PCA, heb je psychologische variabelen gebruik FA. 2.2 Rotatie Na een PCA of FA zonder rotatie krijg je als resultaat een eerste component/factor waar alle variabelen zo hoog mogelijk op laden. Op de overige factoren laden de variabelen in afnemende mate. Een voorbeeld waarbij zo een ongeroteerde factoranalyse van pas kan komen is een IQ-test: hoewel sommigen van mening zijn dat IQ niet één construct is maar uit twee of meerdere factoren bestaat (Voorbeeld: verbaal en performaal) pleiten anderen ervoor om IQ te vatten in één cijfer; met andere woorden één factor waar alle subtesten van de IQ-test hoog op laden. Rotatie daarentegen zorgt ervoor dat er een meer gelijke verdeling komt. Iedere component/factor zal een aantal variabelen krijgen die hoog op deze component/factor laden. We maken een onderscheid tussen orthogonale en oblieke rotaties. - Bij orthogonale rotaties blijven de verschillende componenten/factoren loodrecht op elkaar staan. Het nadeel is dat meerdere variabelen toch nog een redelijk grote lading kunnen hebben op een andere component/factor. Het voordeel is dat de componenten/factoren ongecorreleerd zijn. Bij de grafische voorstelling zal duidelijk worden waarom ongecorreleerd ook wel loodrecht wordt genoemd. - Bij oblieke rotaties roteren de componenten/factoren vrij: correlaties tussen de componenten/factoren zijn met andere woorden wel toegestaan. 19

20 20

21 Op bovenstaande tekening zie je de twee types rotaties voor twee en voor drie componenten/factoren. Een visuele weergave van een rotatie van één component/factor zit er niet bij om de eenvoudige reden dat één component/factor roteren zinloos is. Een visuele weergave van meer dan drie componenten/factoren zit er niet bij omdat dit onmogelijk is. Mocht je er toch in slagen je vier of meer componenten/factoren orthogonaal voor te stellen dan ben je waarschijnlijk psychotisch. De keuze voor orthogonale of oblieke rotatie ligt in je hypothese. Voorbeeld: twee onderzoekers nemen een persoonlijkheidsvragenlijst af. De ene is van mening dat de vijf factoren die hij vindt (Big-V) volledig onafhankelijk zijn van elkaar. Hij zal een orthogonale rotatie gebruiken. De andere vermoedt dat er wel verbanden tussen de factoren kunnen zijn, bijvoorbeeld dat neurotische mensen minder extravert zijn. Hij zal kiezen voor een oblieke rotatie. De verschillende rotatietechnieken in SPSS: In onderstaande procedures staat Varimax aangeduid. Afhankelijk van de onderzoeksvraag kan een andere rotatie soms meer van toepassing zijn. Voor het examen: kies Varimax tenzij er duidelijk aanwijzingen zijn dat je een oblieke rotatie moet gebruiken. In dat laatste geval gebruik je Oblimin. - Varimax: Orthogonale rotatie. Elke factor heeft slechts enkele hoge ladingen (in absolute zin) en de overige ladingen zijn nagenoeg 0. - Quartimax: Orthogonale rotatie. Elke variabele heeft op slechts een beperkt aantal factoren (liefs één) een hoge lading. De overige ladingen zijn nagenoeg 0. - Equamax: Orthogonale rotatie. Combinatie van Varimax en Quartimax - Oblimin: Oblieke rotatie - Promax: Oblieke rotatie Opgelet: Vergeet niet in je rapport te zetten welke rotatie je hebt gebruikt en de GEROTEERDE component/factor-scores te rapporteren en dus niet de ongeroteerde! 21
22 2.3 Principale component analyse Analyze Data Reduction Factor Variables: [Extraction ] [Rotation ] Alle items Method: Principal components (standaard staat dit op hierop) Varimax [Scores ] Save as variables Display factor score coefficient matrix Output a.) Componenten: Total Variance Explained Total (Het aantal componenten = het aantal getallen boven 1 in deze kolom.) b.) Verklaarde variantie component: Total Variance Explained Rotation Sums of Squared Loadings (Meest rechtse kolommen!!!) % of Variance c.) Cumulatieve verklaarde variantie: Total Variance Explained Rotation Sums of Squared Loadings (Meest rechtse kolommen!!!) Cumulative % (De Cumulative % van de laatste component noemt men ook wel de pasmaat van de componentenanalyse) d.) Lading van een item op een (geroteerde) component: (Rotated) Component Matrix Kolom: Rij: Nummer van de component Naam van het item (Opgelet: NIET de tabel Component Score Coefficient Matrix, ze lijken nogal sterk op elkaar!) e.) Communaliteit van een item (= de proportie verklaarde variantie door dat item): Communalities Extraction (Merk op dat dit de som is van de kwadraten van de waarden per rij van de tabel Component Matrix.) f.) Gewichten waarmee de scores op de variabelen lineair gecombineerd moeten worden om tot de score op de 1 e (2 e, 3 e, ) component te komen: Component Score Coefficient Matrix (NIET (Rotated) Component Matrix ) 1 e (2 e, 3 e, ) kolom. Voorbeeld: Score Subject 1 op Component 1 = [(1 e kolom, 1 e rij) * score op 1 e item] + [(1 e kolom, 2 e rij) * score op 2 e item] + + [(1 e kolom, laatste rij) * score op laatste item] 22
23 Uiteraard kan SPSS dit ook zelf berekenen: Dankzij Save as variables heb je nu in het datascherm (dus niet bij de output) per component een extra kolom die aangeeft hoeveel een subject op die component scoort. Eén probleem: SPSS gebruikt deviatiescores. Deze zullen dus verschillen van wat je zelf uitrekent en je kan er niets mee doen. 2.4 Factoranalyse Analyze Data Reduction Factor Variables: Alle items [Extraction ] Method: Principal axis factoring (standaard staat dit op Principal components, zie voorgaande) [Rotation ] Varimax [Scores ] Save as variables Display factor score coefficient matrix Output a.) Kijk eerst of SPSS wel een zinvol resultaat heeft bereikt: Factor Matrix Onderaan: factors extracted. iterations required. (indien dit er niet staat is het resultaat niets waard!) b.) Factoren: Total Variance Explained (Rechterdeel!!!) Total (Het aantal factoren = het aantal getallen boven 1 in deze kolom.) c.) Verklaarde variantie factor: Total Variance Explained Rotation Sums of Squared Loadings (Meest rechtse kolommen!!!) % of Variance d.) Cumulatieve verklaarde factor: Total Variance Explained Rotation Sums of Squared Loadings (Meest rechtse kolommen!!!) Cumulative % (De Cumulative % van de laatste factor noemt men ook wel de pasmaat van de factoranalyse) e.) Lading van een item op een (geroteerde) factor: (Rotated) Factor Matrix Kolom: Rij: Nummer van de factor Naam van het item (Opgelet: NIET de tabel Factor Score Coefficient Matrix, ze lijken nogal sterk op elkaar!) 23
24 f.) Communaliteit van een item (= de proportie verklaarde variantie door dat item): Communalities Extraction (Merk op dat dit de som is van de kwadraten van de waarden per rij van de tabel Factor Matrix.) g.) Gewichten waarmee de scores op de variabelen lineair gecombineerd moeten worden om tot de score op de 1 e (2 e, 3 e, ) factor te komen: Factor Score Coefficient Matrix (NIET (Rotated) Factor Matrix ) 1 e (2 e, 3 e, ) kolom. Voorbeeld: Score Subject 1 op Factor 1 = [(1 e kolom, 1 e rij) * score op 1 e item] + [(1 e kolom, 2 e rij) * score op 2 e item] + + [(1 e kolom, laatste rij) * score op laatste item] Uiteraard kan SPSS dit ook zelf berekenen: Dankzij Save as variables heb je nu in het datascherm (dus niet bij de output) per factor een extra kolom die aangeeft hoeveel een subject op die factor scoort. Eén probleem: SPSS gebruikt deviatiescores. Deze zullen dus verschillen van wat je zelf uitrekent en je kan er niets mee doen. 24
25 3. Clusteranalyse Doel: Groepering van subjecten of objecten in homogene subgroepen volgens nabijheid. De bedoeling is om een beeld te krijgen van het aantal groepen. Opmerking: De variabelen die je ingeeft moeten allemaal volgens dezelfde schaal zijn (Voorbeeld: Likertschaal variërend van 1 tot 5). Is dit niet zo dan moet je de waarden op alle variabelen standaardiseren. Als je twijfelt standaardiseer ze dan maar om zeker te zijn (een reeds gestandaardiseerde variabele standaardiseren maakt toch geen verschil). Indien je niet weet hoeveel clusters je verwacht doe dan een hiërarchische clusteranalyse. Als je wel op voorrand weet hoeveel clusters je verwacht (bijvoorbeeld omdat dat in de opgave van het examen staat) gebruik dan K-Means clusteranalyse. 3.1 Hiërarchische clusteranalyse Output Analyze Classify Hierarchical Cluster Variable(s): Alle variabelen die je wil betrekken [Plots ] Dendrogram a.) Bekijk het dendrogram en beslis op basis daarvan wat het meest logische aantal clusters is. Nu je beslist hebt hoeveel clusters je wilt doe je de clusteranalyse opnieuw maar nu laat je SPSS weten dat je een nieuwe variabele wilt met een clusternummer voor ieder subject: Analyze Classify Hierarchical Cluster Variable(s): Alle variabelen die je wil betrekken [Plots ] Dendrogram [Save ] Single solution (maakt een nieuwe variabele aan) Number of clusters: [aantal clusters dat je verwacht] Output a.) In het datascherm is een nieuwe variabele toegevoegd met daarin het nummer van de cluster waarin het subject of het object zich bevindt. 25
26 3.2 K-Means clusteranalyse Analyze Classify K-Means Cluster Variable(s): Alle variabelen die je wil betrekken Number of clusters: [aantal clusters dat je verwacht] [Save ] Cluster membership Output a.) In het datascherm is een nieuwe variabele toegevoegd met daarin het nummer van de cluster waarin het subject of het object zich bevindt. 26
27 4. Uitgewerkte oefeningen 4.1 Ancova of meervoudige regressie??? Zoals eerder vermeld kan je als je zowel categorische als interval variabelen hebt als predictoren zowel meervoudige regressie [1.1.2; p.4] als Ancova [1.1.4; p.14] gebruiken. De reden dat je beide hebt in SPSS is eerder historisch. Meervoudige regressie werd oorspronkelijk enkel voor interval predictoren gebruikt terwijl Anova (Ancova zonder interval predictoren) voor het vergelijken van groepen (Een groepsnummer is een categorische predictor!) werd ontwikkeld. Als het aan mij lag was het verleden al lang over boord gegooid en zouden we in programma s als SPSS nog maar één procedure overhouden. Helaas heb ik daar niets over te zeggen dus moeten we beide procedures kunnen gebruiken. Hieronder volgt een overzicht. Dit is wel beperkt tot wat we in de lessen hebben gezien, in feite kan je zowat alle functies met beide procedures doen. Meervoudige regressie Ancova SPSS- Analyze Regression Linear Analyze General Linear Model Univariate Wat te doen met je Moeten eerst gehercodeerd Zet bij Fixed Factor(s) categorische predictoren? worden en dan bij Independent(s) gezet worden. Vergeet ook de interactietermen niet als je meer dan één categorische predictor hebt. Wat te doen met je interval Zet bij Independent(s) Zet bij Covariate(s) predictoren? Modelvergelijkingen Door middel van de verschillende Blocks bij Independent(s). Enkel eenvoudige modelvergelijkingen. [1.1.2B; p.5] Iets ingewikkelder, want hier gebeurt het via de Syntax Editor, maar wel veel meer mogelijkheden: gecompliceerde modelvergelijkingen. [1.1.2F; p.8] Contrasten toetsen Niet mogelijk [1.1.3B; p.11] Wat kan je nu best gebruiken op het examen? Lees eerst je opgave eens goed door. Als er een meer gecompliceerde modelvergelijking of een contrasttoets nodig zal zijn zal je zeker Ancova nodig hebben. Zit er een eenvoudige modelvergelijking bij dan kan je kiezen: meervoudige regressie is gemakkelijker en biedt dus iets meer zekerheid (geen gebruik van de Syntax Editor nodig) maar je moet hercoderen. 27
28 4.2 Oefening Opgave Datafile: Voorbeeld.sav De universiteit van Gent stelt zicht de vraag welke variabelen de punten van Data-analyse I het best voorspellen. Dit is de beschikbare data: [PuntenData1]: Het aantal punten dat een student op het examen Data-analyse I heeft behaald op 20. [PuntenStat2]: Het aantal punten dat een student op het examen Statistiek II heeft behaald op 20. [AttitudeData] & [AttitudeSPSS] De ingesteldheid die een student heeft ten opzichte van het vak Data-analyse I en ten opzichte van SPSS. Dit werd gemeten door middel van een vragenlijst met 5 items die beantwoord konden worden door middel van een Likertschaal met een range van 1 (helemaal niet mee eens) tot 5 (volledig mee eens). De items zijn: Item 1: Ik vind professor De Corte nen toffe Item 2: In mijn vrije tijd bereken ik voor de lol singuliere matrixdecomposities Item 3: De lessen van Data-analyse I waren leuk Item 4: Iedere avond voor het slapen gaan zeg ik het SPSS-gebed op Item 5: Ik heb de bijbel der SPSS procedures onder mijn hoofdkussen liggen Item 6: Ik oefen iedere dag enkele uurtjes SPSS [Geaardheid]: 1 = hetero; 2 = homo/lesbisch (Sorry, maar ik ben die standaardvoorbeeldjes met geslacht als predictor beu, dus hier eens iets anders.) [Kledingmaat]: 1 = Small; 2 = Medium; 3 = Large; 4 = Extra Large A.) Beschouw een model met de volgende predictoren: PuntenStat2, AttitudeData, AttitudeSPSS, Geaardheid, en Kledingmaat. Welke variabelen spelen een rol in het voorspellen van de punten op Data-analyse I? In welke zin kunnen we de significante effecten interpreteren? B.) Is er met betrekking tot de punten op Data-Analyse I een verschil tussen: (gezamenlijk beschoud) Dikke hetero s (Geaardheid = 1; Kledingmaat = 4) Homo s en lesbiennes ongeacht de kledingmaat (Geaardheid = 2) Mensen met een small kledingmaat ongeacht de geaardheid (Kledingmaat = 1) 28
29 C.) Stel dat je enkel de hetero s in beschouwing neemt, is er dan een verschil tussen mensen met een small of een medium enerzijds en mensen met een large en een extra large anderzijds? D.) Kunnen de punten op Data-analyse I even goed voorspeld worden zonder de predictor punten op Statistiek II? Oplossing A.) Bekijk de datafile en je zal merken dat de variabelen AttitudeData en AttitudeSPSS niet bestaan. Wel staan er zes variabelen (Item1 t.e.m. Item6) die de scores zijn op de vragenlijst die peilde naar de ingesteldheid ten opzichte van het vak Data-analyse I en ten opzichte van SPSS. Om zes variabelen te reduceren tot twee variabelen hebben we een bilineair model nodig: Principale component analyse of factoranalyse. Aangezien een attitude geen extern observeerbaar iets is maar een onderliggende trek kiezen we voor factoranalyse. (Opgelet: op het examen kan dit veel minder expliciet vermeld staan. Als je een variabele die je nodig hebt niet vindt moet er dus een belletje gaan rinkelen.) Analyze Data Reduction Factor Variables: Item1 t.e.m. Item6 [Extraction ] Method: Principal axis factoring [Rotation ] Varimax We zien dat SPSS twee overhoudt. Op basis van de opgave hadden we niet anders verwacht. We hebben onze output nu wel, maar wat we eigenlijk nodig hebben is onze predictoren AttitudeData en AttitudeSPSS. Sluit daarom je output af en doe de factoranalyse opnieuw, maar doe nu dit erbij: [Scores ] Save as variables Om de tabel Rotated Factor Matrix die we nodig hebben gemakkelijk te kunnen interpreteren is het aan te raden het volgende er ook bij te doen: [Options ] Suppress absolute values less than: 0,40 In je datascherm zie je nu twee nieuwe variabelen, namelijk FAC1_1 en FAC2_1. Op basis van de tabel Rotated Factor Matrix in de output (NIET de tabel Factor Matrix gebruiken 29
30 want dat is de ongeroteerde oplossing. Ook al is die in dit voorbeeld bijna gelijk, het is fout!) Kan je zien dat op de eerste factor (FAC1_1) vooral items 4, 5, en 6 laden. Op basis van de items (zie opgave) kan je concluderen dat deze factor overeen komt met AttitudeSPSS. Analoog komt de factor FAC2_1 overeen met AttitudeData. Hernoem beide factoren. Vergeet niet in je rapport te vermelden dat je deze factoranalyse hebt gedaan. Dit was maar voorbereiding, nu kunnen we verder. Stel je nu even deze vragen: - Wat is de afhankelijke variabele? Is deze categorisch of interval? - Wat zijn de onafhankelijke variabelen? Welke zijn categorisch, welke interval? Analyze General Linear Model Univariate Dependent Variable: PuntenData1 Fixed Factor(s): Covariate(s): [Options ] Display: Geaardheid, Kledingmaat PuntenStat2, AttitudeData, AttitudeSPSS Parameter estimates Voor de resultaten hiervan: zie rapport. Voor de vrijheidsgraden van de F-toets in het rapport: de eerste vrijheidsgraad is diegene die in de kolom df ter hoogte van de predictor staat, de tweede vrijheidsgraad is steeds die in de kolom df ter hoogte van Error staat. Vergeet ook niet om te vermelden in welke richting de significante effecten wijzen! Gebruik hiervoor kolom B in de tabel Parameter Estimates. Voor diegenen die de laatste jaren op een andere planeet hebben doorgebracht: Significant zijn die predictoren met een p-waarde kleiner of gelijk aan B.) Dit is een voorbeeld van contrasten toetsen. Het eerste wat we moeten bepalen is welke van de twee categorische variabelen α en welke β is. De keuze is vrij maar wel belangrijk aangezien SPSS de eerste die je invoegt als α beschouwt en de tweede als β. Hier zullen we α gebruiken voor Geaardheid en β voor Kledingmaat. Ter recapitulatie: de achterste index van de γ s (die voor de β s staat dus) loopt het snelste op! De opgave komt overeen met volgende vergelijking: µ 14 = µ 2. = µ. 1 Dit is één grote hypothese, maar om deze te toetsen in SPSS gaan we ze opsplitsen in kleinere contrasten: slechts 1 gelijkheidsteken per contrast: µ 14 = µ 2. µ 14 = µ. 1 Merk op dat we ook µ 2. = µ. 1 hadden kunnen invoegen; dit is echter zinloos aangezien deze vergelijking redundant is. De regel is dus: evenveel kleine contrasten als er gelijkheidstekens in het oorspronkelijke contrast zitten. 30
31 µ 14 = µ + α 1 + β 4 + γ 14 µ 2. = 1/4 µ /4 µ /4 µ /4 µ 24 = 1/4(µ + α 2 + β 1 + γ 21 ) + 1/4(µ + α 2 + β 2 + γ 22 ) + 1/4(µ + α 2 + β 3 + γ 23 ) + 1/4(µ + α 2 + β 4 + γ 24 ) = µ + α 2 + 1/4 β 1 + 1/4 β 2 + 1/4 β 3 + 1/4 β 4 + 1/4 γ /4 γ /4 γ /4 γ 24 µ. 1 = 1/2 µ /2 µ 21 = 1/2(µ + α 1 + β 1 + γ 11 ) + 1/2(µ + α 2 + β 1 + γ 21 ) = µ + 1/2 α 1 + 1/2 α 2 + β 1 + 1/2 γ /2 γ 21 Het eerste contrast wordt dan: µ + α 1 + β 4 + γ 14 = µ + α 2 + 1/4 β 1 + 1/4 β 2 + 1/4 β 3 + 1/4 β 4 + 1/4 γ /4 γ /4 γ /4 γ 24 α 1 - α 2-1/4 β 1-1/4 β 2-1/4 β 3 + 3/4 β 4 + γ 14-1/4 γ 21-1/4 γ 22-1/4 γ 23-1/4 γ 24 = 0 En het tweede contrast: µ + α 1 + β 4 + γ 14 = µ + 1/2 α 1 + 1/2 α 2 + β 1 + 1/2 γ /2 γ 21 1/2 α 1-1/2 α 2 - β 1 + β 4-1/2 γ 11 + γ 14-1/2 γ 21 = 0 Dit geeft deze tabel: µ α 1 α 2 β 1 β 2 β 3 β 4 γ 11 γ 12 γ 13 γ 14 γ 21 γ 21 γ 23 γ 24 Contrast /4-1/4-1/4 3/ /4-1/4-1/4-1/4 Contrast2 0 1/2-1/ / / Analyze General Linear Model Univariate Dependent Variable: PuntenData1 Fixed Factor(s): Geaardheid, Kledingmaat (We hadden afgesproken dat Geaardheid overeen zou komen met α en Kledingmaat met β dus let er op dat Geaardheid boven Kledingmaat staat in het venster Fixed Factor(s)!) Covariate(s): PuntenStat2, AttitudeData, AttitudeSPSS [Paste] UNIANOVA PuntenData1 BY Geaardheid Kledingmaat WITH PuntenStat2 AttitudeData AttitudeSPSS /lmatrix Toets contrast Geaardheid 1-1 Kledingmaat -1/4-1/4-1/4 3/4 31
32 Geaardheid*Kledingmaat /4-1/4-1/4-1/4 ; (Punt-komma niet vergeten!!!) Geaardheid 1/2-1/2 Kledingmaat Geaardheid*Kledingmaat -1/ / /METHOD = SSTYPE(3) /INTERCEPT = INCLUDE /CRITERIA = ALPHA(.05) /print = test(lmatrix) /DESIGN = PuntenStat2 AttitudeData AttitudeSPSS Geaardheid Kledingmaat Geaardheid*Kledingmaat. [ ] C.) Ook dit is een contrast. Wederom komt α overeen met geaardheid en β met kledingmaat. 1/2(µ 11 + µ 12 ) = 1/2(µ 13 + µ 14 ) 1/2(µ + α 1 + β 1 + γ 11 ) + 1/2(µ + α 1 + β 2 + γ 12 ) = 1/2(µ + α 1 + β 3 + γ 13 ) + 1/2(µ + α 1 + β 4 + γ 14 ) µ + α 1 + 1/2 β 1 + 1/2 β 2 + 1/2 γ /2 γ 12 = µ + α 1 + 1/2 β 3 + 1/2 β 4 + 1/2 γ /2 γ 14 1/2 β 1 + 1/2 β 2-1/2 β 3-1/2 β 4 + 1/2 γ /2 γ 12-1/2 γ 13-1/2 γ 14 = 0 µ α 1 α 2 β 1 β 2 β 3 β 4 γ 11 γ 12 γ 13 γ 14 γ 21 γ 21 γ 23 γ 24 Contrast /2 1/2-1/2-1/2 1/2 1/2-1/2-1/ Analyze General Linear Model Univariate Dependent Variable: PuntenData1 Fixed Factor(s): Geaardheid, Kledingmaat (We hadden afgesproken dat Geaardheid overeen zou komen met α en Kledingmaat met β dus let er op dat Geaardheid boven Kledingmaat staat in het venster Fixed Factor(s)!) Covariate(s): PuntenStat2, AttitudeData, AttitudeSPSS [Paste] UNIANOVA PuntenData1 BY Geaardheid Kledingmaat WITH PuntenStat2 AttitudeData AttitudeSPSS /lmatrix Toets contrast Geaardheid 0 0 Kledingmaat 1/2 1/2-1/2-1/2 Geaardheid*Kledingmaat 1/2 1/2-1/2-1/ /METHOD = SSTYPE(3) /INTERCEPT = INCLUDE /CRITERIA = ALPHA(.05) /print = test(lmatrix) /DESIGN = PuntenStat2 AttitudeData AttitudeSPSS Geaardheid Kledingmaat Geaardheid*Kledingmaat. [ ] 32
33 D.) Dit komt overeen met een modelvergelijking. In het eerste model zitten alle variabelen behalve PuntenStat2, in het tweede model zit PuntenStat2 er wel bij. Als het tweede model niet significant beter is dan het eerste model betekent dit dat de punten op Data-analyse I even goed kunnen worden voorspeld zonder de predictor PuntenStat2. Als het tweede model wel significant beter is dan het eerste model betekent dit dat de punten op Statistiek II wel degelijk bijdragen tot de predictie van de punten op Data-analyse I. Er zijn twee manieren om dit te toetsen. De eerste is via meervoudige regressie, wat betekent dat we de categorische variabelen zullen moeten hercoderen. Maak effectcoderingsvariabelen aan voor je categorische predictoren. Dat zijn er één voor Geaardheid en drie voor Kledingmaat, we zullen ze EfGeaard, EfKleding1, EfKleding2, en EfKleding3 noemen. Vergeet zeker niet ook drie interactievariabelen aan te maken door EfGeaard te vermenigvuldigen met EfKleding1 (dat wordt dan EfInt1), EfGeaard te vermenigvuldigen met EfKleding2 (dat wordt dan EfInt2), en EfGeaard te vermenigvuldigen met EfKleding3 (dat wordt dan EfInt3). Analyze Regression Linear Dependent: PuntenData1 Independent(s): EfGeaard, EfKleding1, EfKleding2, EfKleding3, EfInt1, EfInt2, EfInt3, AttitudeData, AttitudeSPSS [Next] Independent(s): PuntenStat2 [Statistics ] R squared change De tweede manier is doormiddel van Ancova en de Syntax Editor. We moeten nu niet hercoderen. Analyze General Linear Model Univariate Dependent Variable: PuntenData1 Fixed Factor(s): Geaardheid, Kledingmaat Covariate(s): PuntenStat2, AttitudeData, AttitudeSPSS [Paste] UNIANOVA PuntenData1 BY Geaardheid Kledingmaat WITH PuntenStat2 AttitudeData AttitudeSPSS /lmatrix Toets model PuntenStat2 1 /METHOD = SSTYPE(3) /INTERCEPT = INCLUDE /CRITERIA = ALPHA(.05) /DESIGN = PuntenStat2 AttitudeData AttitudeSPSS Geaardheid Kledingmaat Geaardheid*Kledingmaat. [ ] 33
34 4.2.3 Rapport Een factoranalyse werd uitgevoerd op de zes items van de attitudevragenlijst. Twee factoren werden weerhouden. De bekomen oplossing werd geroteerd via varimax. De cumulatieve variantie verklaard door deze twee factoren bedraagt 68.5%. De eerste factor waarop items 4 t.e.m. 6 hoog laden en daarom hernoemd werd tot AttitudeSPSS verklaart 37.8% van de variantie. De tweede factor waarop items 1 t.e.m. 3 hoog laden en daarom hernoemd werd tot AttitudeData verklaart 30.7% van de variantie. Een covariantie-analyse werd uitgevoerd met de score voor Data-analyse I als afhankelijke variabele. De fixed factors waren de geaardheid en de kledingmaat en de covariaten waren de punten voor Statistiek 2, de attitude ten opzichte van Data-analyse en de attitude ten opzichte van SPSS. Van de fixed factors was enkel het hoofdeffect van geaardheid significant, F(1, 19) = , p = Homo s en lesbiennes blijken beter te presteren op Data-analyse I dan hetero s. Het interactie-effect en het hoofdeffect van kledingmaat waren niet significant, F(3, 19) = 0.081, p = en F(3, 19) = 0.927, p = respectievelijk. Van de covariaten is enkel het effect van de punten op Statistiek II significant, F(1, 19) = , p = Het effect ligt in de verwachte richting: Hoe hoger de punten op Statistiek II, hoe hoger de punten op Data-analyse I. De attitudes ten opzichte van SPSS en ten opzichte van Data-analyse bleken geen significante predictoren te zijn, F(1, 19) = 0.191, p = en F(1, 19) = 0.113, p = Wat de nominale variabelen Geaardheid en Kledingmaat betreft blijkt er een significant verschil te zijn tussen Dikke hetero s, Homo s en lesbiennes ongeacht de kledingmaat, en Mensen met een small kledingmaat ongeacht de geaardheid. F(2, 19) = 8.764, p = Indien men enkel de hetero s in beschouwing neemt, dan blijkt er geen verschil te zijn op punten Data-analyse I tussen diegenen met een small of medium en diegenen met een large of een extra large. F(1, 19) = 0.609, p = De punten op Statistiek II zorgen voor een significant betere predictie van de punten op Data-analyse I bovenop de andere predictoren. F(1, 19) = , p =
DATA-ANALYSE I OEFENINGEN ACADEMIEJAAR 2000 2001. Feedback Praktische Proef
 DATA-ANALYSE I OEFENINGEN ACADEMIEJAAR 2000 2001 Feedback Praktische Proef 1 Vooraf Het is onbegonnen werk om voor elke versie van de praktische proef een volledig uitgeschreven rapport te presenteren.
DATA-ANALYSE I OEFENINGEN ACADEMIEJAAR 2000 2001 Feedback Praktische Proef 1 Vooraf Het is onbegonnen werk om voor elke versie van de praktische proef een volledig uitgeschreven rapport te presenteren.
Meervoudige ANOVA Onderzoeksvraag Voorwaarden
 Er is onderzoek gedaan naar rouw na het overlijden van een huisdier (contactpersoon: Karolijne van der Houwen (Klinische Psychologie)). Mensen konden op internet een vragenlijst invullen. Daarin werd gevraagd
Er is onderzoek gedaan naar rouw na het overlijden van een huisdier (contactpersoon: Karolijne van der Houwen (Klinische Psychologie)). Mensen konden op internet een vragenlijst invullen. Daarin werd gevraagd
Deze menu-aansturingen zijn van toepassing op versies 14.0 en 15.0 van SPSS.
 Menu aansturing van SPSS voorbeeld in hoofdstuk 8 over schaalconstructie met Cronbach s α en principale componenten analyse van meningen over strafdoelen Hieronder wordt uitgelegd hoe alle analyses besproken
Menu aansturing van SPSS voorbeeld in hoofdstuk 8 over schaalconstructie met Cronbach s α en principale componenten analyse van meningen over strafdoelen Hieronder wordt uitgelegd hoe alle analyses besproken
Bij factor ANOVA is er een tweede onafhankelijke variabele in de analyse bij gekomen. Er zijn drie soorten designs mogelijk:
 13. Factor ANOVA De theorie achter factor ANOVA (tussengroep) Bij factor ANOVA is er een tweede onafhankelijke variabele in de analyse bij gekomen. Er zijn drie soorten designs mogelijk: 1. Onafhankelijke
13. Factor ANOVA De theorie achter factor ANOVA (tussengroep) Bij factor ANOVA is er een tweede onafhankelijke variabele in de analyse bij gekomen. Er zijn drie soorten designs mogelijk: 1. Onafhankelijke
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica. Tentamen Statistiek 2 voor TeMa (2S195) op dinsdag , uur.
 op dinsdag , uur.") TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor TeMa (S95) op dinsdag 3-03-00, 9- uur. Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor TeMa (S95) op dinsdag 3-03-00, 9- uur. Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en
Voorbeeld regressie-analyse
 Voorbeeld regressie-analyse In dit voorbeeld wordt gebruik gemaakt van het SPSS data-bestand vb_regr.sav (dit bestand kan gedownload worden via de on-line helpdesk). We schatten een model waarin de afhankelijke
Voorbeeld regressie-analyse In dit voorbeeld wordt gebruik gemaakt van het SPSS data-bestand vb_regr.sav (dit bestand kan gedownload worden via de on-line helpdesk). We schatten een model waarin de afhankelijke
Dit jaar gaan we MULTIVARIAAT TOETSEN. Bijvoorbeeld: We willen zien of de scores op taal en rekenen van kinderen afwijken in de populatie.
 Toetsen van hypothesen Bijvoorbeeld: nagaan of het gemiddeld IQ bij een bepaalde steekproef groter/kleiner is als in de populatie. µ = 100 Normaalverdeling, waarbij we de score van de steekproef gaan vergelijken
Toetsen van hypothesen Bijvoorbeeld: nagaan of het gemiddeld IQ bij een bepaalde steekproef groter/kleiner is als in de populatie. µ = 100 Normaalverdeling, waarbij we de score van de steekproef gaan vergelijken
Oplossingen hoofdstuk Het milieubesef
 Oplossingen hoofdstuk 3 1. Het milieubesef Eerst het hercoderen van item 3 en 5, via het commando Transform, Recode into different variables, nadien verschijnt het dialoogvenster Recode into Different
Oplossingen hoofdstuk 3 1. Het milieubesef Eerst het hercoderen van item 3 en 5, via het commando Transform, Recode into different variables, nadien verschijnt het dialoogvenster Recode into Different
16. MANOVA. Overeenkomsten en verschillen met ANOVA. De theorie MANOVA
 16. MANOVA MANOVA Multivariate variantieanalyse (MANOVA) kan gebruikt worden in een situatie waarin je meerdere afhankelijke variabelen hebt. Met MANOVA kan er 1 onafhankelijke variabele gebruikt worden
16. MANOVA MANOVA Multivariate variantieanalyse (MANOVA) kan gebruikt worden in een situatie waarin je meerdere afhankelijke variabelen hebt. Met MANOVA kan er 1 onafhankelijke variabele gebruikt worden
Bij herhaalde metingen ANOVA komt het effect van het experiment naar voren bij de variantie binnen participanten. Bij de gewone ANOVA is dit de SS R
 14. Herhaalde metingen Introductie Bij herhaalde metingen worden er bij verschillende condities in een experiment dezelfde proefpersonen gebruikt of waarbij dezelfde proefpersonen op verschillende momenten
14. Herhaalde metingen Introductie Bij herhaalde metingen worden er bij verschillende condities in een experiment dezelfde proefpersonen gebruikt of waarbij dezelfde proefpersonen op verschillende momenten
mlw stroom 2.2 Biostatistiek en Epidemiologie College 9: Herhaalde metingen (2) Syllabus Afhankelijke Data Hoofdstuk 4, 5.1, 5.2
 Syllabus Afhankelijke Data Hoofdstuk 4, 5.1, 5.2") mlw stroom 2.2 Biostatistiek en Epidemiologie College 9: Herhaalde metingen (2) Syllabus Afhankelijke Data Hoofdstuk 4, 5.1, 5.2 Bjorn Winkens Methodologie en Statistiek Universiteit Maastricht 21 maart
mlw stroom 2.2 Biostatistiek en Epidemiologie College 9: Herhaalde metingen (2) Syllabus Afhankelijke Data Hoofdstuk 4, 5.1, 5.2 Bjorn Winkens Methodologie en Statistiek Universiteit Maastricht 21 maart
Enkelvoudige ANOVA Onderzoeksvraag Voorwaarden
 Er is onderzoek gedaan naar rouw na het overlijden van een huisdier (contactpersoon: Karolijne van der Houwen (Klinische Psychologie)). Mensen konden op internet een vragenlijst invullen. Daarin werd gevraagd
Er is onderzoek gedaan naar rouw na het overlijden van een huisdier (contactpersoon: Karolijne van der Houwen (Klinische Psychologie)). Mensen konden op internet een vragenlijst invullen. Daarin werd gevraagd
10. Moderatie, mediatie en nog meer regressie
 10. Moderatie, mediatie en nog meer regressie Voordat je moderatie en mediatie analyses gaat uitvoeren in, kun je het best een extra dialog box installeren, PROCESS. Volg hiervoor de stappen op pagina
10. Moderatie, mediatie en nog meer regressie Voordat je moderatie en mediatie analyses gaat uitvoeren in, kun je het best een extra dialog box installeren, PROCESS. Volg hiervoor de stappen op pagina
Zowel correlatie als regressie meten statistische samenhang Correlatie: geen oorzakelijk verband verondersteld: X Y
 1 Regressie analyse Zowel correlatie als regressie meten statistische samenhang Correlatie: geen oorzakelijk verband verondersteld: X Y Regressie: wel een oorzakelijk verband verondersteld: X Y Voorbeeld
1 Regressie analyse Zowel correlatie als regressie meten statistische samenhang Correlatie: geen oorzakelijk verband verondersteld: X Y Regressie: wel een oorzakelijk verband verondersteld: X Y Voorbeeld
Verband tussen twee variabelen
 Verband tussen twee variabelen Inleiding Dit practicum sluit aan op hoofdstuk I-3 van het statistiekboek en geeft uitleg over het maken van kruistabellen, het berekenen van de correlatiecoëfficiënt en
Verband tussen twee variabelen Inleiding Dit practicum sluit aan op hoofdstuk I-3 van het statistiekboek en geeft uitleg over het maken van kruistabellen, het berekenen van de correlatiecoëfficiënt en
c. Geef de een-factor ANOVA-tabel. Formuleer H_0 and H_a. Wat is je conclusie?
 Opdracht 13a ------------ Een-factor ANOVA (ANOVA-tabel, Contrasten, Bonferroni) Bij een onderzoek naar de leesvaardigheid bij kinderen in de V.S. werden drie onderwijsmethoden met elkaar vergeleken. Verschillende
Opdracht 13a ------------ Een-factor ANOVA (ANOVA-tabel, Contrasten, Bonferroni) Bij een onderzoek naar de leesvaardigheid bij kinderen in de V.S. werden drie onderwijsmethoden met elkaar vergeleken. Verschillende
11. Multipele Regressie en Correlatie
 11. Multipele Regressie en Correlatie Meervoudig regressie model Nu gaan we kijken naar een relatie tussen een responsvariabele en meerdere verklarende variabelen. Een bivariate regressielijn ziet er in
11. Multipele Regressie en Correlatie Meervoudig regressie model Nu gaan we kijken naar een relatie tussen een responsvariabele en meerdere verklarende variabelen. Een bivariate regressielijn ziet er in
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica
 TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor TeMa (S95) Avondopleiding. donderdag 6-6-3, 9.-. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor TeMa (S95) Avondopleiding. donderdag 6-6-3, 9.-. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
20. Multilevel lineaire modellen
 20. Multilevel lineaire modellen Hiërarchische gegevens Veel fenomenen zijn ingebed in een bredere context. Variabelen kunnen dus ook hiërarchisch zijn, ingebed zijn in variabelen op hogere niveaus. Deze
20. Multilevel lineaire modellen Hiërarchische gegevens Veel fenomenen zijn ingebed in een bredere context. Variabelen kunnen dus ook hiërarchisch zijn, ingebed zijn in variabelen op hogere niveaus. Deze
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica. Tentamen Statistiek 2 voor TeMa (2S195) op dinsdag ,
 op dinsdag ,") TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek 2 voor TeMa (2S95) op dinsdag 5-03-2005, 9.00-22.00 uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek 2 voor TeMa (2S95) op dinsdag 5-03-2005, 9.00-22.00 uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
We berekenen nog de effectgrootte aan de hand van formule 4.2 en rapporteren:
 INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 4 1. Toets met behulp van SPSS de hypothese van Evelien in verband met de baardlengte van metalfans. Ga na of je dezelfde conclusies
INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 4 1. Toets met behulp van SPSS de hypothese van Evelien in verband met de baardlengte van metalfans. Ga na of je dezelfde conclusies
ANOVA in SPSS. Hugo Quené. opleiding Taalwetenschap Universiteit Utrecht Trans 10, 3512 JK Utrecht 12 maart 2003
 ANOVA in SPSS Hugo Quené hugo.quene@let.uu.nl opleiding Taalwetenschap Universiteit Utrecht Trans 10, 3512 JK Utrecht 12 maart 2003 1 vooraf In dit voorbeeld gebruik ik fictieve gegevens, ontleend aan
ANOVA in SPSS Hugo Quené hugo.quene@let.uu.nl opleiding Taalwetenschap Universiteit Utrecht Trans 10, 3512 JK Utrecht 12 maart 2003 1 vooraf In dit voorbeeld gebruik ik fictieve gegevens, ontleend aan
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica. Tentamen Statistiek 2 voor TeMa (2S195) op vrijdag , 9-12 uur.
 op vrijdag , 9-12 uur.") TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek 2 voor TeMa (2S95) op vrijdag 29-04-2004, 9-2 uur. Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek 2 voor TeMa (2S95) op vrijdag 29-04-2004, 9-2 uur. Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
Oplossingen hoofdstuk XI
 Oplossingen hoofdstuk XI. Hierbij vind je de resultaten van het onderzoek naar de relatie tussen een leestest en een schoolrapport voor lezen. Deze gegevens hebben betrekking op een regressieanalyse bij
Oplossingen hoofdstuk XI. Hierbij vind je de resultaten van het onderzoek naar de relatie tussen een leestest en een schoolrapport voor lezen. Deze gegevens hebben betrekking op een regressieanalyse bij
SPSS. Statistiek : SPSS
 SPSS - hoofdstuk 1 : 1.4. fase 4 : verrichten van metingen en / of verzamelen van gegevens Gegevens gevonden bij een onderzoek worden systematisch weergegeven in een datamatrix bij SPSS De datamatrix Gebruik
SPSS - hoofdstuk 1 : 1.4. fase 4 : verrichten van metingen en / of verzamelen van gegevens Gegevens gevonden bij een onderzoek worden systematisch weergegeven in een datamatrix bij SPSS De datamatrix Gebruik
Voer de gegevens in in een tabel. Definieer de drie kolommen van de tabel en kies als kolomnamen groep, vooraf en achteraf.
 Opdracht 10a ------------ t-procedures voor gekoppelde paren t-procedures voor twee onafhankelijke steekproeven samengestelde t-procedures voor twee onafhankelijke steekproeven Twee groepen van 10 leraren
Opdracht 10a ------------ t-procedures voor gekoppelde paren t-procedures voor twee onafhankelijke steekproeven samengestelde t-procedures voor twee onafhankelijke steekproeven Twee groepen van 10 leraren
Toegepaste data-analyse: oefensessie 2
 Toegepaste data-analyse: oefensessie 2 Depressie 1. Beschrijf de clustering van de dataset en geef aan op welk niveau de verschillende variabelen behoren Je moet weten hoe de data geclusterd zijn om uit
Toegepaste data-analyse: oefensessie 2 Depressie 1. Beschrijf de clustering van de dataset en geef aan op welk niveau de verschillende variabelen behoren Je moet weten hoe de data geclusterd zijn om uit
College 3 Meervoudige Lineaire Regressie
 College 3 Meervoudige Lineaire Regressie - Leary: Hoofdstuk 8 p. 165-169 - MM&C: Hoofdstuk 11 - Aanvullende tekst 3 (alinea 2) Jolien Pas ECO 2012-2013 'Computerprogramma voorspelt Top 40-hits Bron: http://www.nu.nl/internet/2696133/computerprogramma-voorspelt-top-40-hits.html
College 3 Meervoudige Lineaire Regressie - Leary: Hoofdstuk 8 p. 165-169 - MM&C: Hoofdstuk 11 - Aanvullende tekst 3 (alinea 2) Jolien Pas ECO 2012-2013 'Computerprogramma voorspelt Top 40-hits Bron: http://www.nu.nl/internet/2696133/computerprogramma-voorspelt-top-40-hits.html
Classification - Prediction
 Classification - Prediction Tot hiertoe: vooral classification Naive Bayes k-nearest Neighbours... Op basis van predictor variabelen X 1, X 2,..., X p klasse Y (= discreet) proberen te bepalen. Training
Classification - Prediction Tot hiertoe: vooral classification Naive Bayes k-nearest Neighbours... Op basis van predictor variabelen X 1, X 2,..., X p klasse Y (= discreet) proberen te bepalen. Training
Met factoranalyse worden heel veel variabelen ingekort tot een aantal variabelen.
 17. Factor analyse Met factoranalyse worden heel veel variabelen ingekort tot een aantal variabelen. Het gebruik van factoranalyse Variabelen die niet direct gemeten kunnen worden heten latente variabelen.
17. Factor analyse Met factoranalyse worden heel veel variabelen ingekort tot een aantal variabelen. Het gebruik van factoranalyse Variabelen die niet direct gemeten kunnen worden heten latente variabelen.
TYPE EXAMENVRAGEN VOOR TOEGEPASTE STATISTIEK
 TYPE EXAMENVRAGEN VOOR TOEGEPASTE STATISTIEK Prof. Dr. M. Vandebroek 1. Een aantal proefpersonen werd gevraagd een frisdrank te beoordelen door aan te geven in hoeverre ze het eens zijn met de volgende
TYPE EXAMENVRAGEN VOOR TOEGEPASTE STATISTIEK Prof. Dr. M. Vandebroek 1. Een aantal proefpersonen werd gevraagd een frisdrank te beoordelen door aan te geven in hoeverre ze het eens zijn met de volgende
M M M M M M M M M M M M M M La La La La La La La Mid Mid Mid Mid Mid Mid Mid 65 56 83 68 64 47 59 63 93 65 75 68 68 51
 INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 7 1. Een onderzoeker wil nagaan of de fitheid van jongeren tussen 14 en 18 jaar (laag, matig, hoog) en het geslacht (M, V) een
INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 7 1. Een onderzoeker wil nagaan of de fitheid van jongeren tussen 14 en 18 jaar (laag, matig, hoog) en het geslacht (M, V) een
1. Reductie van error variantie en dus verhogen van power op F-test
 Werkboek 2013-2014 ANCOVA Covariantie analyse bestaat uit regressieanalyse en variantieanalyse. Er wordt een afhankelijke variabele (intervalniveau) voorspeld uit meerdere onafhankelijke variabelen. De
Werkboek 2013-2014 ANCOVA Covariantie analyse bestaat uit regressieanalyse en variantieanalyse. Er wordt een afhankelijke variabele (intervalniveau) voorspeld uit meerdere onafhankelijke variabelen. De
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor T (2S070) op vrijdag 8 oktober 1999, uur De u
 op vrijdag 8 oktober 1999, uur De u") TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor T (2S070) op vrijdag 8 oktober 1999, 14.00-17.00 uur De uitwerkingen van de opgaven dienen duidelijk geformuleerd
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek voor T (2S070) op vrijdag 8 oktober 1999, 14.00-17.00 uur De uitwerkingen van de opgaven dienen duidelijk geformuleerd
b. Bepaal b1 en b0 en geef de vergelijking van de kleinste-kwadratenlijn.
 Opdracht 12a ------------ enkelvoudige lineaire regressie Kan de leeftijd waarop een kind begint te spreken voorspellen hoe zijn score zal zijn bij een latere test op verstandelijke vermogens? Een studie
Opdracht 12a ------------ enkelvoudige lineaire regressie Kan de leeftijd waarop een kind begint te spreken voorspellen hoe zijn score zal zijn bij een latere test op verstandelijke vermogens? Een studie
Aanpassingen takenboek! Statistische toetsen. Deze persoon in een verdeling. Iedereen in een verdeling
 Kwantitatieve Data Analyse (KDA) Onderzoekspracticum Sessie 2 11 Aanpassingen takenboek! Check studienet om eventuele verbeteringen te downloaden! Huidige versie takenboek: 09 Gjalt-Jorn Peters gjp@ou.nl
Kwantitatieve Data Analyse (KDA) Onderzoekspracticum Sessie 2 11 Aanpassingen takenboek! Check studienet om eventuele verbeteringen te downloaden! Huidige versie takenboek: 09 Gjalt-Jorn Peters gjp@ou.nl
EIND TOETS TOEGEPASTE BIOSTATISTIEK I. 30 januari 2009
 EIND TOETS TOEGEPASTE BIOSTATISTIEK I 30 januari 2009 - Dit tentamen bestaat uit vier opgaven onderverdeeld in totaal 2 subvragen. - Geef bij het beantwoorden van de vragen een zo volledig mogelijk antwoord.
EIND TOETS TOEGEPASTE BIOSTATISTIEK I 30 januari 2009 - Dit tentamen bestaat uit vier opgaven onderverdeeld in totaal 2 subvragen. - Geef bij het beantwoorden van de vragen een zo volledig mogelijk antwoord.
INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 5
 INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 5 1. De onderzoekers van een preventiedienst vermoeden dat werknemers in een bedrijf zonder liften fitter zijn dan werknemers
INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 5 1. De onderzoekers van een preventiedienst vermoeden dat werknemers in een bedrijf zonder liften fitter zijn dan werknemers
HOOFDSTUK VII REGRESSIE ANALYSE
 HOOFDSTUK VII REGRESSIE ANALYSE 1 DOEL VAN REGRESSIE ANALYSE De relatie te bestuderen tussen een response variabele en een verzameling verklarende variabelen 1. LINEAIRE REGRESSIE Veronderstel dat gegevens
HOOFDSTUK VII REGRESSIE ANALYSE 1 DOEL VAN REGRESSIE ANALYSE De relatie te bestuderen tussen een response variabele en een verzameling verklarende variabelen 1. LINEAIRE REGRESSIE Veronderstel dat gegevens
SPSS Introductiecursus. Sanne Hoeks Mattie Lenzen
 SPSS Introductiecursus Sanne Hoeks Mattie Lenzen Statistiek, waarom? Doel van het onderzoek om nieuwe feiten van de werkelijkheid vast te stellen door middel van systematisch onderzoek en empirische verzamelen
SPSS Introductiecursus Sanne Hoeks Mattie Lenzen Statistiek, waarom? Doel van het onderzoek om nieuwe feiten van de werkelijkheid vast te stellen door middel van systematisch onderzoek en empirische verzamelen
Masterclass: advanced statistics. Bianca de Greef Sander van Kuijk Afdeling KEMTA
 Masterclass: advanced statistics Bianca de Greef Sander van Kuijk Afdeling KEMTA Inhoud Masterclass Deel 1 (theorie): Achtergrond regressie Deel 2 (voorbeeld): Keuzes Output Model Model Dependent variable
Masterclass: advanced statistics Bianca de Greef Sander van Kuijk Afdeling KEMTA Inhoud Masterclass Deel 1 (theorie): Achtergrond regressie Deel 2 (voorbeeld): Keuzes Output Model Model Dependent variable
Meervoudige lineaire regressie
 Meervoudige lineaire regressie Inleiding In dit hoofdstuk dat aansluit op hoofdstuk II- (deel 2) wordt uitgelegd hoe een meervoudige regressieanalyse uitgevoerd kan worden met behulp van SPSS. Aan de hand
Meervoudige lineaire regressie Inleiding In dit hoofdstuk dat aansluit op hoofdstuk II- (deel 2) wordt uitgelegd hoe een meervoudige regressieanalyse uitgevoerd kan worden met behulp van SPSS. Aan de hand
b. Maak een histogram van de verdeling van het groeiseizoen. Kies eerst klassen en maak een geschikte frequentietabel.
 Opdracht 2a ----------- Stamdiagrammen, histogrammen, tijdreeksgrafieken De Old Farmers Almanac vermeldt de groeiseizoenen voor de grote steden in de V.S., zoals gerapporteerd door het National Climatic
Opdracht 2a ----------- Stamdiagrammen, histogrammen, tijdreeksgrafieken De Old Farmers Almanac vermeldt de groeiseizoenen voor de grote steden in de V.S., zoals gerapporteerd door het National Climatic
Meervoudige variantieanalyse
 Meervoudige variantieanalyse Inleiding In dit hoofdstuk, dat aansluit op hoofdstuk II-12 (deel2) van het statistiekboek, wordt besproken hoe met SPSS gemiddelden van verschillende groepen met elkaar vergeleken
Meervoudige variantieanalyse Inleiding In dit hoofdstuk, dat aansluit op hoofdstuk II-12 (deel2) van het statistiekboek, wordt besproken hoe met SPSS gemiddelden van verschillende groepen met elkaar vergeleken
Enkelvoudige lineaire regressie
 Enkelvoudige lineaire regressie Inleiding Dit hoofdstuk sluit aan op hoofdstuk I-9 van het statistiekboek. Er wordt hier steeds gesproken over het verband tussen één afhankelijke variabele Y en één onafhankelijke
Enkelvoudige lineaire regressie Inleiding Dit hoofdstuk sluit aan op hoofdstuk I-9 van het statistiekboek. Er wordt hier steeds gesproken over het verband tussen één afhankelijke variabele Y en één onafhankelijke
LES 2: Data-cleaning en -transformatie 1. Frequentietabel
 Methoden SPSS hoe en waarom LES 1: Introductie SPSS 1. Basiskennis SPSS Eerst 3 stappen uitvoeren in de databank: 1. Definitie van variabelen = variabelen invoegen en values definiëren = missing values
Methoden SPSS hoe en waarom LES 1: Introductie SPSS 1. Basiskennis SPSS Eerst 3 stappen uitvoeren in de databank: 1. Definitie van variabelen = variabelen invoegen en values definiëren = missing values
Pilot vragenlijst communicatieve redzaamheid
 Pilot vragenlijst communicatieve redzaamheid Het instrument Communicatieve redzaamheid kan worden opgevat als een vermogen om wederkerig te communiceren met behulp van woorden, gebaren of symbolen. Communicatief
Pilot vragenlijst communicatieve redzaamheid Het instrument Communicatieve redzaamheid kan worden opgevat als een vermogen om wederkerig te communiceren met behulp van woorden, gebaren of symbolen. Communicatief
Basishandleiding SPSS
 Basishandleiding SPSS Elvira Folmer & Marieke ten Voorde SLO, Juli 2008 Deze handleiding is gebaseerd op SPSS 16.0 for Windows Inhoud 1 Het maken van een gegevensbestand in de Variable View... 4 2 Het
Basishandleiding SPSS Elvira Folmer & Marieke ten Voorde SLO, Juli 2008 Deze handleiding is gebaseerd op SPSS 16.0 for Windows Inhoud 1 Het maken van een gegevensbestand in de Variable View... 4 2 Het
Deze opdracht lossen we eenvoudig op door in de vergelijking X1 en X2 te vervangen door de geobserveerde waarden van deze variabelen:
 INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 10 1. Volgende regressievergelijking werd opgesteld na onderzoek: YY ii = 6 + 2.5 XX ii1 + 3 XX ii2 + εε ii Bereken de voorspelde
INDUCTIEVE STATISTIEK VOOR DE GEDRAGSWETENSCHAPPEN OPLOSSINGEN BIJ HOOFDSTUK 10 1. Volgende regressievergelijking werd opgesteld na onderzoek: YY ii = 6 + 2.5 XX ii1 + 3 XX ii2 + εε ii Bereken de voorspelde
Examen Statistische Modellen en Data-analyse. Derde Bachelor Wiskunde. 14 januari 2008
 Examen Statistische Modellen en Data-analyse Derde Bachelor Wiskunde 14 januari 2008 Vraag 1 1. Stel dat ɛ N 3 (0, σ 2 I 3 ) en dat Y 0 N(0, σ 2 0) onafhankelijk is van ɛ = (ɛ 1, ɛ 2, ɛ 3 ). Definieer
Examen Statistische Modellen en Data-analyse Derde Bachelor Wiskunde 14 januari 2008 Vraag 1 1. Stel dat ɛ N 3 (0, σ 2 I 3 ) en dat Y 0 N(0, σ 2 0) onafhankelijk is van ɛ = (ɛ 1, ɛ 2, ɛ 3 ). Definieer
Fasen in het onderzoeksproces
 Fasen in het onderzoeksproces Gegevensbestand Controleren gegevens Bewerken gegevens Analyseren gegevens Interpreteren resultaten Nieuwe vragen? ja Onderzoeksverslag 1 Bestand opmaken Variabelen definiëren:
Fasen in het onderzoeksproces Gegevensbestand Controleren gegevens Bewerken gegevens Analyseren gegevens Interpreteren resultaten Nieuwe vragen? ja Onderzoeksverslag 1 Bestand opmaken Variabelen definiëren:
Logistische regressie analyse: een handleiding Inge Sieben 1 Liesbeth Linssen
 Logistische regressie analyse: een handleiding Inge Sieben 1 Liesbeth Linssen Inhoudsopgave: Wat is logistische regressie analyse Hoe stuur je logistische regressie analyse in SPSS aan Hoe interpreteer
Logistische regressie analyse: een handleiding Inge Sieben 1 Liesbeth Linssen Inhoudsopgave: Wat is logistische regressie analyse Hoe stuur je logistische regressie analyse in SPSS aan Hoe interpreteer
Analyse van kruistabellen
 Analyse van kruistabellen Inleiding In dit hoofdstuk, dat aansluit op hoofdstuk II-13 (deel2) van het statistiekboek wordt ingegaan op het analyseren van kruistabellen met behulp van SPSS. Met een kruistabel
Analyse van kruistabellen Inleiding In dit hoofdstuk, dat aansluit op hoofdstuk II-13 (deel2) van het statistiekboek wordt ingegaan op het analyseren van kruistabellen met behulp van SPSS. Met een kruistabel
Tentamen Biostatistiek 1 voor BMT (2DM40) woensdag 2 november 2011, uur
 woensdag 2 november 2011, uur") Faculteit der Wiskunde en Informatica Tentamen Biostatistiek 1 voor BMT (2DM40) woensdag 2 november 2011, 9.00-12.00 uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en van een onbeschreven
Faculteit der Wiskunde en Informatica Tentamen Biostatistiek 1 voor BMT (2DM40) woensdag 2 november 2011, 9.00-12.00 uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine en van een onbeschreven
* de percentages goed per klas en volgorde van afnemen. sort cases by klas volgorde. split file by klas volgorde. des var=goedboekperc.
 * Sprekende voorbeelden. * De invloed van lessen op meerkeuzetoetsen Natuurkunde, klas 5 en 6 * Manfred te Grotenhuis en Nico van de Mortel * we gaan uit van de folder 'temp'op de c-drive, svp wijzigen
* Sprekende voorbeelden. * De invloed van lessen op meerkeuzetoetsen Natuurkunde, klas 5 en 6 * Manfred te Grotenhuis en Nico van de Mortel * we gaan uit van de folder 'temp'op de c-drive, svp wijzigen
Statistiek II. 1. Eenvoudig toetsen. Onderdeel toetsen binnen de cursus: Toetsen en schatten ivm één statistiek of steekproef
 Statistiek II Onderdeel toetsen binnen de cursus: 1. Eenvoudig toetsen Toetsen en schatten ivm één statistiek of steekproef Via de z-verdeling, als µ onderzocht wordt en gekend is: Via de t-verdeling,
Statistiek II Onderdeel toetsen binnen de cursus: 1. Eenvoudig toetsen Toetsen en schatten ivm één statistiek of steekproef Via de z-verdeling, als µ onderzocht wordt en gekend is: Via de t-verdeling,
8. Analyseren van samenhang tussen categorische variabelen
 8. Analyseren van samenhang tussen categorische variabelen Er bestaat een samenhang tussen twee variabelen als de verdeling van de respons (afhankelijke) variabele verandert op het moment dat de waarde
8. Analyseren van samenhang tussen categorische variabelen Er bestaat een samenhang tussen twee variabelen als de verdeling van de respons (afhankelijke) variabele verandert op het moment dat de waarde
College 2 Enkelvoudige Lineaire Regressie
 College Enkelvoudige Lineaire Regressie - Leary: Hoofdstuk 7 tot p. 170 (Advanced Correlational Strategies) - MM&C: Hoofdstuk 10 (Inference for Regression) - Aanvullende tekst 3 Jolien Pas ECO 011-01 Correlatie:
College Enkelvoudige Lineaire Regressie - Leary: Hoofdstuk 7 tot p. 170 (Advanced Correlational Strategies) - MM&C: Hoofdstuk 10 (Inference for Regression) - Aanvullende tekst 3 Jolien Pas ECO 011-01 Correlatie:
Hoofdstuk 5 Een populatie: parametrische toetsen
 Hoofdstuk 5 Een populatie: parametrische toetsen 5.1 Gemiddelde, variantie, standaardafwijking: De variantie is als het ware de gemiddelde gekwadrateerde afwijking van het gemiddelde. Hoe groter de variantie
Hoofdstuk 5 Een populatie: parametrische toetsen 5.1 Gemiddelde, variantie, standaardafwijking: De variantie is als het ware de gemiddelde gekwadrateerde afwijking van het gemiddelde. Hoe groter de variantie
SPSS 15.0 in praktische stappen voor AGW-bachelors Uitwerkingen Stap 7: Oefenen I
 SPSS 15.0 in praktische stappen voor AGW-bachelors Uitwerkingen Stap 7: Oefenen I Hieronder volgen de SPSS uitvoer en de antwoorden van de opgaven van Stap 7: Oefenen I. Daarnaast wordt bij elke opgave
SPSS 15.0 in praktische stappen voor AGW-bachelors Uitwerkingen Stap 7: Oefenen I Hieronder volgen de SPSS uitvoer en de antwoorden van de opgaven van Stap 7: Oefenen I. Daarnaast wordt bij elke opgave
9. Lineaire Regressie en Correlatie
 9. Lineaire Regressie en Correlatie Lineaire verbanden In dit hoofdstuk worden methoden gepresenteerd waarmee je kwantitatieve respons variabelen (afhankelijk) en verklarende variabelen (onafhankelijk)
9. Lineaire Regressie en Correlatie Lineaire verbanden In dit hoofdstuk worden methoden gepresenteerd waarmee je kwantitatieve respons variabelen (afhankelijk) en verklarende variabelen (onafhankelijk)
Regressie-analyse doel menu hulp globale werkwijze aandachtspunten Doel: Voor de uitvoering in SPSS: Missing Values Globale werkwijze
 Regressie-analyse Regressie-analyse is gericht op het voorspellen van één (numerieke) afhankelijke variabele met behulp van een of meerdere onafhankelijke variabelen (numerieke en/of dummy-variabelen).
Regressie-analyse Regressie-analyse is gericht op het voorspellen van één (numerieke) afhankelijke variabele met behulp van een of meerdere onafhankelijke variabelen (numerieke en/of dummy-variabelen).
mlw stroom 2.1: Statistisch modelleren
 mlw stroom 2.1: Statistisch modelleren College 5: Regressie en correlatie (2) Rosner 11.5-11.8 Arnold Kester Capaciteitsgroep Methodologie en Statistiek Universiteit Maastricht Postbus 616, 6200 MD Maastricht
mlw stroom 2.1: Statistisch modelleren College 5: Regressie en correlatie (2) Rosner 11.5-11.8 Arnold Kester Capaciteitsgroep Methodologie en Statistiek Universiteit Maastricht Postbus 616, 6200 MD Maastricht
Bijlage 3: Multiple regressie analyse
 Bijlage 3: Multiple regressie analyse REGRESSION /DESCRIPTIVES MEAN STDDEV CORR SIG N /MISSING PAIRWISE /STATISTICS COEFF OUTS CI(95) R ANOVA COLLIN TOL ZPP /CRITERIA=PIN(.05) POUT(.10) /NOORIGIN /DEPENDENT
Bijlage 3: Multiple regressie analyse REGRESSION /DESCRIPTIVES MEAN STDDEV CORR SIG N /MISSING PAIRWISE /STATISTICS COEFF OUTS CI(95) R ANOVA COLLIN TOL ZPP /CRITERIA=PIN(.05) POUT(.10) /NOORIGIN /DEPENDENT
2.9 Het adolescentieonderzoek 69 2.10 Opgaven 72
 Inhoud Hoofdstuk 1 Design en analyse 11 1.1 Specificatie van designs 13 1.2 Definities 14 1.3 Het verschil tussen een afhankelijke variabele en een niveau van een within-subjectfactor 19 1.4 Kiezen van
Inhoud Hoofdstuk 1 Design en analyse 11 1.1 Specificatie van designs 13 1.2 Definities 14 1.3 Het verschil tussen een afhankelijke variabele en een niveau van een within-subjectfactor 19 1.4 Kiezen van
Bij het maken van deze opgave worden de volgende vragen beantwoord:
 Opdracht 1a ----------- Introductie Bij het maken van deze opgave worden de volgende vragen beantwoord: Hoe start ik S-PLUS op? Hoe lees ik gegevens in vanuit een ASCII-bestand in een tabel? Hoe kan ik
Opdracht 1a ----------- Introductie Bij het maken van deze opgave worden de volgende vragen beantwoord: Hoe start ik S-PLUS op? Hoe lees ik gegevens in vanuit een ASCII-bestand in een tabel? Hoe kan ik
Hoofdstuk 8 Het toetsen van nonparametrische variabelen
 Hoofdstuk 8 Het toetsen van nonparametrische variabelen 8.1 Non-parametrische toetsen: deze toetsen zijn toetsen waarbij de aannamen van normaliteit en intervalniveau niet nodig zijn. De aannamen zijn
Hoofdstuk 8 Het toetsen van nonparametrische variabelen 8.1 Non-parametrische toetsen: deze toetsen zijn toetsen waarbij de aannamen van normaliteit en intervalniveau niet nodig zijn. De aannamen zijn
Uitvoer van analyses (SPSS 16) voor het Faalfeedback en Oriëntatie voorbeeld in hoofdstuk 7 (Herhaalde metingen) >
 voor het Faalfeedback en Oriëntatie voorbeeld in hoofdstuk 7 (Herhaalde metingen) >") Uitvoer van analyses (SPSS 6) voor het aalfeedback en Oriëntatie voorbeeld in hoofdstuk 7 (Herhaalde metingen) > ** Berekening van lineaire en kwadratische trendvariabele. Compute ylin = -.77678 * y +
Uitvoer van analyses (SPSS 6) voor het aalfeedback en Oriëntatie voorbeeld in hoofdstuk 7 (Herhaalde metingen) > ** Berekening van lineaire en kwadratische trendvariabele. Compute ylin = -.77678 * y +
Het samenstellen van een multipele indicator index. Harry B.G. Ganzeboom ADEK UvS College 2 28 februari 2011
 Het samenstellen van een multipele indicator index Harry B.G. Ganzeboom ADEK UvS College 2 28 februari 2011 Indices voor attituden Attittuden (opvattingen) zijn complexe kenmerken Moeilijk te meten met
Het samenstellen van een multipele indicator index Harry B.G. Ganzeboom ADEK UvS College 2 28 februari 2011 Indices voor attituden Attittuden (opvattingen) zijn complexe kenmerken Moeilijk te meten met
Examenvragen KBM/EMS 09-15
 THEORIE Examenvragen KBM/EMS 09-15 Je krijgt een logistisch model met lineaire predictor = beta 0. Leid via de maximum likelihoodfunctie een schatter af voor beta 0. Bewijs met principale componenten Vraag
THEORIE Examenvragen KBM/EMS 09-15 Je krijgt een logistisch model met lineaire predictor = beta 0. Leid via de maximum likelihoodfunctie een schatter af voor beta 0. Bewijs met principale componenten Vraag
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica. Tentamenopgaven Statistiek (2DD71) op xx-xx-xxxx, xx.00-xx.00 uur.
 op xx-xx-xxxx, xx.00-xx.00 uur.") VOORAF: Hieronder staat een aantal opgaven over de stof. Veel meer dan op het tentamen zelf gevraagd zullen worden. Op het tentamen zullen in totaal 20 onderdelen gevraagd worden. TECHNISCHE UNIVERSITEIT
VOORAF: Hieronder staat een aantal opgaven over de stof. Veel meer dan op het tentamen zelf gevraagd zullen worden. Op het tentamen zullen in totaal 20 onderdelen gevraagd worden. TECHNISCHE UNIVERSITEIT
introductie Wilcoxon s rank sum toets Wilcoxon s signed rank toets introductie Wilcoxon s rank sum toets Wilcoxon s signed rank toets
 toetsende statistiek week 1: kansen en random variabelen week : de steekproevenverdeling week 3: schatten en toetsen: de z-toets week : het toetsen van gemiddelden: de t-toets week 5: het toetsen van varianties:
toetsende statistiek week 1: kansen en random variabelen week : de steekproevenverdeling week 3: schatten en toetsen: de z-toets week : het toetsen van gemiddelden: de t-toets week 5: het toetsen van varianties:
Statistiek II. Sessie 5. Feedback Deel 5
 Statistiek II Sessie 5 Feedback Deel 5 VPPK Universiteit Gent 2017-2018 Feedback Oefensessie 5 1 Statismex, gewicht en slaperigheid2 1. Lineair model: slaperigheid2 = β 0 + β 1 dosis + β 2 bd + ε H 0 :
Statistiek II Sessie 5 Feedback Deel 5 VPPK Universiteit Gent 2017-2018 Feedback Oefensessie 5 1 Statismex, gewicht en slaperigheid2 1. Lineair model: slaperigheid2 = β 0 + β 1 dosis + β 2 bd + ε H 0 :
Antwoordvel Versie A
 Antwoordvel Versie A Interimtoets Toegepaste Biostatistiek 13 december 013 Naam:... Studentnummer:...... Antwoorden: Vraag Antwoord Antwoord Antwoord Vraag Vraag A B C D A B C D A B C D 1 10 19 11 0 3
Antwoordvel Versie A Interimtoets Toegepaste Biostatistiek 13 december 013 Naam:... Studentnummer:...... Antwoorden: Vraag Antwoord Antwoord Antwoord Vraag Vraag A B C D A B C D A B C D 1 10 19 11 0 3
Hierbij is het steekproefgemiddelde x_gemiddeld= en de steekproefstandaardafwijking
 Opdracht 9a ----------- t-procedures voor een enkelvoudige steekproef Voor de meting van de leesvaardigheid van kinderen wordt als toets de Degree of Reading Power (DRP) gebruikt. In een onderzoek onder
Opdracht 9a ----------- t-procedures voor een enkelvoudige steekproef Voor de meting van de leesvaardigheid van kinderen wordt als toets de Degree of Reading Power (DRP) gebruikt. In een onderzoek onder
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica. Tentamen Biostatistiek voor BMT (2S390) op maandag ,
 op maandag ,") TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Biostatistiek voor BMT (2S390) op maandag 19-11-2001, 14.00-17.00 uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Biostatistiek voor BMT (2S390) op maandag 19-11-2001, 14.00-17.00 uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
Hoofdstuk 8. Toetsende statistiek. 8.1 Associatie van categoriale data: CROSSTABS [dv 32.2]
![Hoofdstuk 8. Toetsende statistiek. 8.1 Associatie van categoriale data: CROSSTABS [dv 32.2]](/thumbs/40/20645084.jpg "Hoofdstuk 8. Toetsende statistiek. 8.1 Associatie van categoriale data: CROSSTABS [dv 32.2]") Hoofdstuk 8 Toetsende statistiek Meestal zijn we niet alleen geïnteresseerd in beschrijvende statistiek (over de steekproef), maar ook in toetsende statistiek. Het doel hiervan is om hypothesen te toetsen,
Hoofdstuk 8 Toetsende statistiek Meestal zijn we niet alleen geïnteresseerd in beschrijvende statistiek (over de steekproef), maar ook in toetsende statistiek. Het doel hiervan is om hypothesen te toetsen,
Statistiek ( ) eindtentamen
 eindtentamen") Statistiek (200300427) eindtentamen studiejaar 2010-11, blok 4; Taalwetenschap, Universiteit Utrecht. woensdag 29 juni 2011, 17:15-19:00u, Educatorium, zaal Gamma. Schrijf je naam en student-nummer op
Statistiek (200300427) eindtentamen studiejaar 2010-11, blok 4; Taalwetenschap, Universiteit Utrecht. woensdag 29 juni 2011, 17:15-19:00u, Educatorium, zaal Gamma. Schrijf je naam en student-nummer op
College 6 Eenweg Variantie-Analyse
 College 6 Eenweg Variantie-Analyse - Leary: Hoofdstuk 11, 1 (t/m p. 55) - MM&C: Hoofdstuk 1 (t/m p. 617), p. 63 t/m p. 66 - Aanvullende tekst 6, 7 en 8 Jolien Pas ECO 01-013 Het Experiment: een voorbeeld
College 6 Eenweg Variantie-Analyse - Leary: Hoofdstuk 11, 1 (t/m p. 55) - MM&C: Hoofdstuk 1 (t/m p. 617), p. 63 t/m p. 66 - Aanvullende tekst 6, 7 en 8 Jolien Pas ECO 01-013 Het Experiment: een voorbeeld
Hoofdstuk 10 Eenwegs- en tweewegs-variantieanalyse
 Hoofdstuk 10 Eenwegs- en tweewegs-variantieanalyse 10.1 Eenwegs-variantieanalyse: Als we gegevens hebben verzameld van verschillende groepen en we willen nagaan of de populatiegemiddelden van elkaar verscihllen,
Hoofdstuk 10 Eenwegs- en tweewegs-variantieanalyse 10.1 Eenwegs-variantieanalyse: Als we gegevens hebben verzameld van verschillende groepen en we willen nagaan of de populatiegemiddelden van elkaar verscihllen,
Menu aansturing van SPSS voorbeeld in hoofdstuk 7 over Kaplan-Meier en Cox regressie survival analyses van recidive bij meisjes
 Menu aansturing van SPSS voorbeeld in hoofdstuk 7 over Kaplan-Meier en Cox regressie survival analyses van recidive bij meisjes Hieronder wordt uitgelegd hoe alle analyses besproken in paragraaf 7.5 van
Menu aansturing van SPSS voorbeeld in hoofdstuk 7 over Kaplan-Meier en Cox regressie survival analyses van recidive bij meisjes Hieronder wordt uitgelegd hoe alle analyses besproken in paragraaf 7.5 van
Toets deel 2 Data-analyse en retrieval Vrijdag 1 Juli 2016:
 Toets deel 2 Data-analyse en retrieval Vrijdag 1 Juli 2016: 11.00-13.00 Algemene aanwijzingen 1. Het is toegestaan een aan beide zijden beschreven A4 met aantekeningen te raadplegen. 2. Het is toegestaan
Toets deel 2 Data-analyse en retrieval Vrijdag 1 Juli 2016: 11.00-13.00 Algemene aanwijzingen 1. Het is toegestaan een aan beide zijden beschreven A4 met aantekeningen te raadplegen. 2. Het is toegestaan
Opdracht 5a ----------- Kruistabellen
 Opdracht 5a ----------- Kruistabellen Aan elk van 36 studenten werd gevraagd of zij alcohol drinken, en zo ja, welke soort alcoholische drank de voorkeur heeft. Tevens werd voor elke student de leeftijd
Opdracht 5a ----------- Kruistabellen Aan elk van 36 studenten werd gevraagd of zij alcohol drinken, en zo ja, welke soort alcoholische drank de voorkeur heeft. Tevens werd voor elke student de leeftijd
11. Meerdere gemiddelden vergelijken, ANOVA
 11. Meerdere gemiddelden vergelijken, ANOVA Analyse van variantie (ANOVA) wordt gebruikt wanneer er situaties zijn waarbij er meer dan twee condities vergeleken worden. In dit hoofdstuk wordt de onafhankelijke
11. Meerdere gemiddelden vergelijken, ANOVA Analyse van variantie (ANOVA) wordt gebruikt wanneer er situaties zijn waarbij er meer dan twee condities vergeleken worden. In dit hoofdstuk wordt de onafhankelijke
Betrouwbaarheid, validiteit en overeenstemming
 Betrouwbaarheid, validiteit en overeenstemming Inleiding Dit practicum sluit aan op het theoriegedeelte over betrouwbaarheidsanalyse van hoofdstuk II-16 (deel 2). In dit hoofdstuk wordt besproken hoe een
Betrouwbaarheid, validiteit en overeenstemming Inleiding Dit practicum sluit aan op het theoriegedeelte over betrouwbaarheidsanalyse van hoofdstuk II-16 (deel 2). In dit hoofdstuk wordt besproken hoe een
Examenvragen KBM (herexamen)
") Examenvragen KBM 2012-2013 (herexamen) THEORIE: - BetaGLS en BetaOLS berekenen - Bewijs met principale componenten - Vraag over variantieanalyse: o wanneer stochastisch gebruiken o wanneer het andere (ben
Examenvragen KBM 2012-2013 (herexamen) THEORIE: - BetaGLS en BetaOLS berekenen - Bewijs met principale componenten - Vraag over variantieanalyse: o wanneer stochastisch gebruiken o wanneer het andere (ben
a. Wanneer kan men in plaats van de Pearson correlatie coefficient beter de Spearman rangcorrelatie coefficient berekenen?
 Opdracht 15a ------------ Spearman rangcorrelatie coefficient (non-parametrische tegenhanger van de Pearson correlatie coefficient) Wilcoxon symmetrie-toets (non-parametrische tegenhanger van de t-procedure
Opdracht 15a ------------ Spearman rangcorrelatie coefficient (non-parametrische tegenhanger van de Pearson correlatie coefficient) Wilcoxon symmetrie-toets (non-parametrische tegenhanger van de t-procedure
Feedback examen Statistiek II Juni 2011
 Feedback examen Statistiek II Juni 2011 Bij elke vraag is alternatief A correct. 1 De variabele X is Student verdeeld in een bepaalde populatie, met verwachting µ X en variantie σ 2 X. Je trekt steekproeven
Feedback examen Statistiek II Juni 2011 Bij elke vraag is alternatief A correct. 1 De variabele X is Student verdeeld in een bepaalde populatie, met verwachting µ X en variantie σ 2 X. Je trekt steekproeven
Opgave 1: (zowel 2DM40 als 2S390)
") TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Biostatistiek voor BMT (DM4 en S39) op donderdag, 4.-7. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Biostatistiek voor BMT (DM4 en S39) op donderdag, 4.-7. uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine
Wat gaan we doen? Help! Statistiek! Wat is een lineaire relatie? De rechte-lijn-vergelijking: Y = a + b X. Relatie tussen gewicht en lengte
 Help! Statistiek! Wat gaan we doen? Doel: Informeren over statistiek in klinisch onderzoek. Tijd: Doorlopende serie laagdrempelige lezingen, voor iedereen vrij toegankelijk. Derde woensdag in de maand,
Help! Statistiek! Wat gaan we doen? Doel: Informeren over statistiek in klinisch onderzoek. Tijd: Doorlopende serie laagdrempelige lezingen, voor iedereen vrij toegankelijk. Derde woensdag in de maand,
Onderzoek. B-cluster BBB-OND2B.2
 Onderzoek B-cluster BBB-OND2B.2 Succes met leren Leuk dat je onze bundels hebt gedownload. Met deze bundels hopen we dat het leren een stuk makkelijker wordt. We proberen de beste samenvattingen voor jou
Onderzoek B-cluster BBB-OND2B.2 Succes met leren Leuk dat je onze bundels hebt gedownload. Met deze bundels hopen we dat het leren een stuk makkelijker wordt. We proberen de beste samenvattingen voor jou
d. Formuleer voor het hoofdeffect Afmeting H_0 en H_a. Is dit hoofdeffect significant?
 Opdracht 14a ------------ Twee-factor ANOVA In een groot research-project bestudeerde men de fysische eigenschappen van multiplex houtmaterialen, vervaardigd door kleine plakjes hout aan elkaar te hechten.
Opdracht 14a ------------ Twee-factor ANOVA In een groot research-project bestudeerde men de fysische eigenschappen van multiplex houtmaterialen, vervaardigd door kleine plakjes hout aan elkaar te hechten.
Cursus TEO: Theorie en Empirisch Onderzoek. Practicum 2: Herhaling BIS 11 februari 2015
 Cursus TEO: Theorie en Empirisch Onderzoek Practicum 2: Herhaling BIS 11 februari 2015 Centrale tendentie Centrale tendentie wordt meestal afgemeten aan twee maten: Mediaan: de middelste waarneming, 50%
Cursus TEO: Theorie en Empirisch Onderzoek Practicum 2: Herhaling BIS 11 februari 2015 Centrale tendentie Centrale tendentie wordt meestal afgemeten aan twee maten: Mediaan: de middelste waarneming, 50%
SPSS VOOR DUMMIES+ Werken met de NSE: enkele handige basisbeginselen. Gebaseerd op SPSS21.0 & Benchmarkbestand NSE 2014
 SPSS VOOR DUMMIES+ Werken met de NSE: enkele handige basisbeginselen Gebaseerd op SPSS21.0 & Benchmarkbestand NSE 2014 Huidig kennis- en ervaringsniveau?????? Beginners Gevorderden 2 Inhoud 1. Wat doe
SPSS VOOR DUMMIES+ Werken met de NSE: enkele handige basisbeginselen Gebaseerd op SPSS21.0 & Benchmarkbestand NSE 2014 Huidig kennis- en ervaringsniveau?????? Beginners Gevorderden 2 Inhoud 1. Wat doe
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica. Tentamen Statistiek II voor TeMa (2S195) op maandag ,
 op maandag ,") TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek II voor TeMa (2S195) op maandag 8-5-26, 9.-12. uur Bij het tentamen mag gebruik worden gemaakt van een (grafisch)
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek II voor TeMa (2S195) op maandag 8-5-26, 9.-12. uur Bij het tentamen mag gebruik worden gemaakt van een (grafisch)
Het gebruik van SPSS voor statistische analyses. Een beknopte handleiding.
 Het gebruik van SPSS voor statistische analyses. Een beknopte handleiding. SPSS is een alom gebruikt, gebruiksvriendelijk statistisch programma dat vele analysemogelijkheden kent. Voor HBO en universitaire
Het gebruik van SPSS voor statistische analyses. Een beknopte handleiding. SPSS is een alom gebruikt, gebruiksvriendelijk statistisch programma dat vele analysemogelijkheden kent. Voor HBO en universitaire
TECHNISCHE UNIVERSITEIT EINDHOVEN
 TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek 2 voor TeMa (2S95) dinsdag 2-08-2003, 4.00-7.00 uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine,
TECHNISCHE UNIVERSITEIT EINDHOVEN Faculteit Wiskunde en Informatica Tentamen Statistiek 2 voor TeMa (2S95) dinsdag 2-08-2003, 4.00-7.00 uur Bij het tentamen mag gebruik worden gemaakt van een zakrekenmachine,
Vandaag. Onderzoeksmethoden: Statistiek 3. Recap 2. Recap 1. Recap Centrale limietstelling T-verdeling Toetsen van hypotheses
 Vandaag Onderzoeksmethoden: Statistiek 3 Peter de Waal (gebaseerd op slides Peter de Waal, Marjan van den Akker) Departement Informatica Beta-faculteit, Universiteit Utrecht Recap Centrale limietstelling
Vandaag Onderzoeksmethoden: Statistiek 3 Peter de Waal (gebaseerd op slides Peter de Waal, Marjan van den Akker) Departement Informatica Beta-faculteit, Universiteit Utrecht Recap Centrale limietstelling
Statistiek in de alfa en gamma studies. Aansluiting wiskunde VWO-WO 16 april 2018
 Statistiek in de alfa en gamma studies Aansluiting wiskunde VWO-WO 16 april 2018 Wie ben ik? Marieke Westeneng Docent bij afdeling Methoden en Statistiek Faculteit Sociale Wetenschappen Universiteit Utrecht
Statistiek in de alfa en gamma studies Aansluiting wiskunde VWO-WO 16 april 2018 Wie ben ik? Marieke Westeneng Docent bij afdeling Methoden en Statistiek Faculteit Sociale Wetenschappen Universiteit Utrecht
College 7 Tweeweg Variantie-Analyse
 College 7 Tweeweg Variantie-Analyse - Leary: Hoofdstuk 12 (p. 255 t/m p. 262) - MM&C: Hoofdstuk 12 (p. 618 t/m p. 623 ), Hoofdstuk 13 - Aanvullende tekst 9, 10, 11 Jolien Pas ECO 2012-2013 Het Experiment
College 7 Tweeweg Variantie-Analyse - Leary: Hoofdstuk 12 (p. 255 t/m p. 262) - MM&C: Hoofdstuk 12 (p. 618 t/m p. 623 ), Hoofdstuk 13 - Aanvullende tekst 9, 10, 11 Jolien Pas ECO 2012-2013 Het Experiment